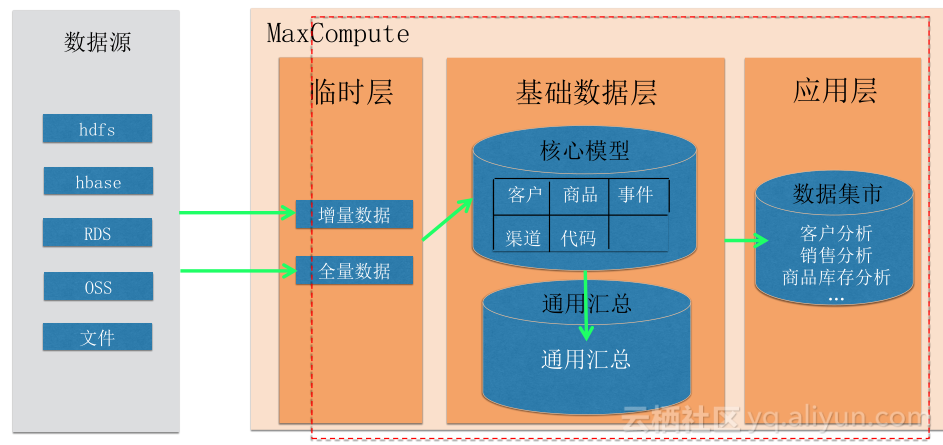
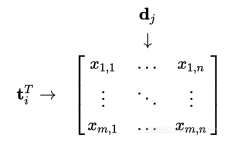
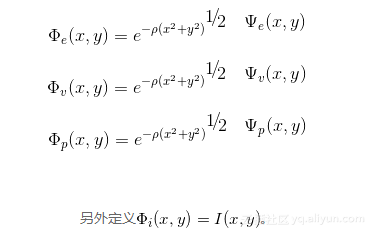一篇很好的参考文章:深度学习算法在自然语言处理中的一些心得
更多深度文章,请关注:https://yq.aliyun.com/cloud 作者简介:Frank Chung,HTC Research Engineering Blog编辑,专注于各种计算机技术的研究和探索。个人主页:https://medium.com/@frank_chung 以下为译文: 深度学习逐渐在NLP(自然语言处理)上发挥重要作用。 在此我就NLP问题的一些技术演变做一些简单阐述。 N元语法模型 连续文本序列“to be or not to be”可以通过以下方式来建模: 一元语法(单个词): to,be,or,not,to,be 二元语法(两个词): to be, be or, or not, not to, to be 三元语法(三个词): to be or, be or not, or not to, not to be N元语法模型可以解决下一个词预测的问题,例如,如果前面的词是“to be or not to”,6元语法模型可以预测下一个词的可能是“be”: P(be|to be or not to) = C(to be or not to be) / C(to be or not to) 词频-逆向文件频率(TF-IDF) TF-IDF表示了单词的重要性。 一个单词的词频(TF)是该单词在文档中出现的次数: TF(“cow” in document) = C(“cow” in document)/C(all words in document) 一个单词的文件频率是指包含这个单词的文件在所有文件中占的数量 DF(“cow”) = log(C(all documents)/C(documents contain “cow”)) 例如,如果文档1中的“cow”出现4次,并且文档1包含100个词,则文档1上的单词“cow”的词语频率为0.04。 如果“cow”存在于100个文档中并且总共有10000个文档,则“cow”的文档频率为log(10000/100)= 2。因此,TF-IDF为0.04 * 2 = 0.08。 潜在语义分析(LSA) LSA应用TF-IDF来计算词和文档之间的关系。 m个单词和n个文档 令X是一个矩阵,其中元素(i,j)意味着文档j中的词i的TF-IDF。 然后我们可以通过矩阵乘积𝑿𝑿ᵀ获得两个词的相关性,并通过矩阵积获得两个文档的相关性。 词向量 通过神经网络,出现了一种共享矩阵C的概念,该矩阵C可以将每个词投影到特征向量中,并且将该向量作为神经网络的输入来训练主要任务。 假设特征空间的维数为M,词汇量为V,矩阵C为| V | * M,C(Wt)的映射结果为1 * M向量 假设特征空间的维度为M,词汇为V,则投影C为| V | * M矩阵。 输入层包含N元语法模型中的N-1个之前的单词,其由1到| V |编码表示。 输出层由| V |组成词汇表中单词的概率。 词嵌入 Word2vec是一个两层神经网络,可以提取一个词的特征向量,这被称为“词嵌入”。word2vec应用CBOW或Skip-gram网络来训练投影矩阵,而不是通过训练预测下一个单词的方式。 连续单词包(CBOW)通过将周围单词输入到输入层来预测中心词的方式来训练投影矩阵。 而Skip-gram网络则是通过应用中心词来预测其周围词来训练投影矩阵。 这两种方式都可以用来训练用于词嵌入提取的投影矩阵。 词相似 与'Sweden'相关的单词 为了找出目标词的相关词,我们可以计算词汇表中所有其他词的余弦相似性(距离)。 向量偏移 给出China->Beijing, 找出Japan->? 给定单词a,绑定c的单词向量,如果a:b = c:d这样的关系,我们可以通过V𝚍=V𝐜+(V𝐛-V𝐚)找到结果d。 然后在词汇表中找出的词向量具有V𝐝的最小余弦距离的单词。 通过向量偏移找到的相关单词 递归神经网络 无论CBOW还是Skip-gram模型都只考虑相邻的N个词来训练神经网络。因此如果N变得非常大,则这两种方式都可能行不通。 为了克服这个缺点,递归神经网络(RNN)应运而生: 传统神经网络 考虑上述用于训练NLP问题的传统神经网络,每个词被输入到用于词向量的投影矩阵W,并且由隐藏层R转换为输出S.在这种情况下,R的输入大小固定为5 * M(假设词向量中有M个特征)。 如果N被改变为6,则R不能被扩展。 递归神经网络 在递归神经网络中,代替隐藏层R,我们一次只训练两个向量与隐藏层A,并递归地合并两个词。 这样,A的输入大小始终为2 * M。 循环神经网络 由于递归神经网络不容易实现,因此就提出了循环神经网络(RNN)来处理相同的问题。 循环神经网络的输入只有一个词,并将隐藏层的输出重定向到输入的一部分。 整个输入大小为| V | + M(M是前面单词的特征数,V是词汇表的大小)。 上述示例是用于下一字符预测的示例。 “h”被反馈到隐藏层以获得其词向量,并且该向量被反馈到具有“e”的输入的一部分。 在训练所有词之后,可以训练隐藏层(投影矩阵)的参数。 案例学习 表1.不同方法训练的词向量的句法规则 表2.词向量的不同的训练方法的语义规律 表1和表2表明:1.无论在语法或语义实验中,来自RNN的单词向量都比LSA更准确。2. 如果在应用RNN时增加单词向量的维度,则准确度会因此增加。 表3微软的完成句子挑战 表3表明,如果使ship-gram网络将投影矩阵预训练到已存在的RNN,则测试精度会变得更好。 表4. CBOW与Skip-gram的对比 表4表明Skip-gram训练结果比CBOW的好。 引用 SemEval: 词之间的语义关系。 Microsoft sentence completion challenge: 填写一个句子中错过的单词 数十款阿里云产品限时折扣中,赶紧点击领劵开始云上实践吧! 本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。 文章原标题《Notes for deep learning on NLP》,作者:Frank Chung,译者:friday012 文章为简译,更为详细的内容,请查看原文