Centos7 搭建LDAP并启用TLS加密
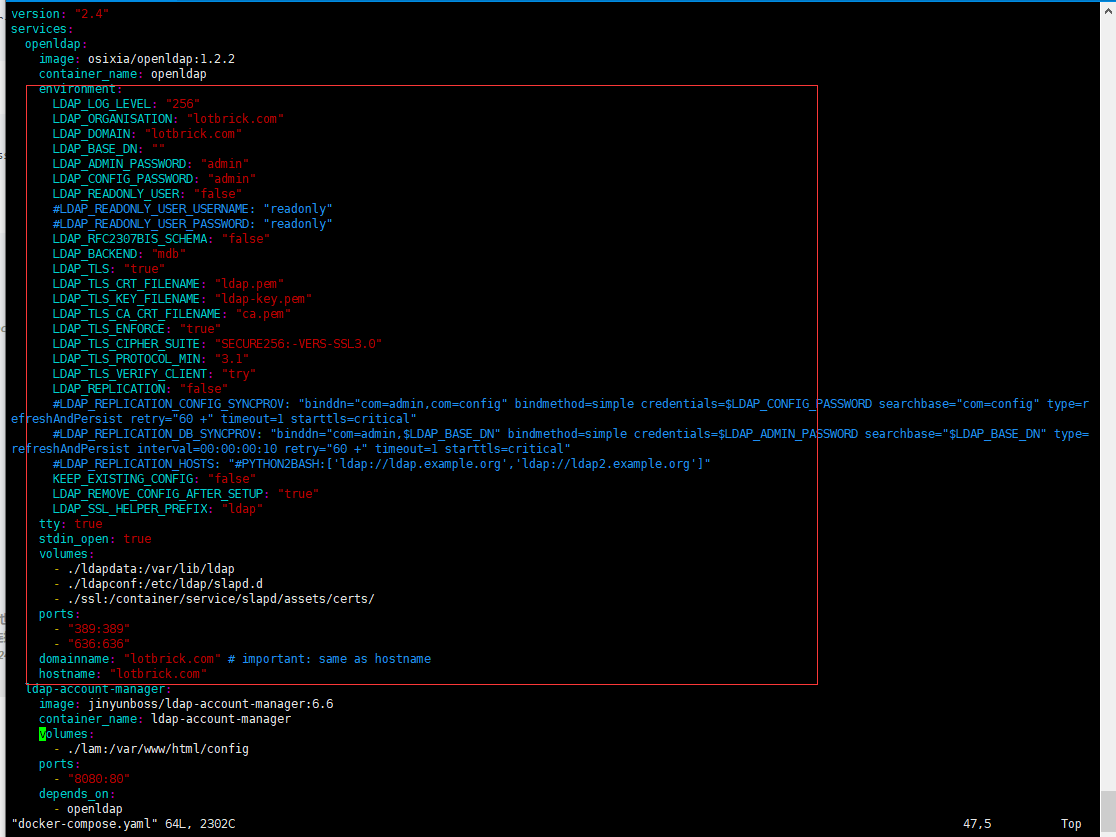
简介 LDAP(轻量级目录访问协议,Lightweight Directory Access Protocol)是为了实现目录服务的信息服务。 目录服务是一种特殊的数据库系统,其专门针对读取,浏览和搜索操作进行了特定的优化。在网络中应用了LDAP后,用户只需要使用一个账号和密码就可以轻松访问网络中的所有服务,实现用户身份的统一认证。 简单来说:拿LDAP来统一管理一些账号,例如: Gitlab,JenKins,Samba,SVN,Zabbix等。 关于SSL/TLS LDAP over SSL # LDAP over SSL 也就是 ldaps # ldap默认不加密情况下是走的389端口 # 当使用ldaps的时候走的就是636端口了 # 可以简单理解成http和https的关系 # 当然ldaps已经淘汰了,不然也不会有LDAP over TLS出来 LDAP over TLS # TLS可以简单理解为ldaps的升级 # 它默认走389端口,但是会通讯的时候加密 # 客户端连接LDAP时,需要指明通讯类型为TLS,所以他可以跟不加密的模式一样,任意端口都行 对比一下连接方式: ldaps: ldapsearch -H ldaps://127.0.0.1 TLS: ldapsearch -ZZ -H ldap://127.0.0.1 环境 CentOS Linux release 7.5.1804 Kernel 4.20.0-1.el7.elrepo.x86_64 docker-ce 18.09 docker-compose 1.23.1 安装docker-compose yum install -y python-pip pip install docker-compose docker-compose -v 准备证书 安装cfssl wget -O /bin/cfssl https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 wget -O /bin/cfssljson https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 wget -O /bin/cfssl-certinfo https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 for cfssl in `ls /bin/cfssl*`;do chmod +x $cfssl;done; 配置证书信息 cd $HOME && mkdir ssl && cd ssl # ca配置文件 cat > ca-config.json << EOF { "signing": { "default": { "expiry": "87600h" }, "profiles": { "ldap": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "87600h" } } } } EOF # 自签名ca的证书申请 cat > ldap-ca-csr.json << EOF { "CN": "ldap", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "Shenzhen", "L": "Shenzhen", "O": "ldap", "OU": "LDAP Security" } ] } EOF # ldap证书申请资料 # 下面hosts字段里就是使用这张证书的主机 # 特别注意一定要加上宿主机的IP地址,反正是自己颁发的证书,怎么加都行!!! # 加上本机回环地址,加上ldap容器名,我这里容器名待会设置成openldap # 如果你要放到公网去的话,那一可以加上FQDN地址 cat > ldap-csr.json << EOF { "CN": "ldap", "hosts": [ "127.0.0.1", "192.168.1.1", "openldap", "ldap.lotbrick.com", "lotbrick.com" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "Shenzhen", "L": "Shenzhen", "O": "ldap", "OU": "LDAP Security" } ] } EOF 给证书签名 # CA自签名 cfssl gencert -initca ldap-ca-csr.json | cfssljson -bare ca # LDAP证书签名,ldap需要的文件为:ca证书,ldap证书,ldap私钥 cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=ldap ldap-csr.json | cfssljson -bare ldap # 查看生成的证书 # 其中 ldap-key.pem ldap.pem ca.pem 是我们需要的 [root@master ssl]#ls ca-config.json ca.csr ca-key.pem ca.pem ldap-ca-csr.json ldap.csr ldap-csr.json ldap-key.pem ldap.pem 开始安装ldap 克隆仓库,获取docker-compose.yaml文件 cd $HOME git clone https://github.com/JyBigBoss/docker-compose.git cd docker-compose/LDAP/ 复制证书 mkdir ssl/ cp $HOME/ssl/{ldap-key.pem,ldap.pem,ca.pem} ssl/ 修改docker-compose.yaml文件 vi docker-compose.yaml # 修改下面的几项 # 镜像使用的是osixia/openldap # 详细的配置解释:https://github.com/osixia/docker-openldap LDAP_ORGANISATION: "lotbrick.com" LDAP_DOMAIN: "lotbrick.com" LDAP_ADMIN_PASSWORD: "admin" LDAP_CONFIG_PASSWORD: "admin" LDAP_TLS: "true" LDAP_TLS_CRT_FILENAME: "ldap.pem" LDAP_TLS_KEY_FILENAME: "ldap-key.pem" LDAP_TLS_CA_CRT_FILENAME: "ca.pem" LDAP_TLS_ENFORCE: "true" LDAP_TLS_VERIFY_CLIENT: "try" domainname: "lotbrick.com" hostname: "lotbrick.com" # 特别注意LDAP_TLS_VERIFY_CLIENT # 不要设置成demand,这个选项可以理解成双向认证,也就是客户端连接ldap时也许要提供证书,也就是客户端也需要有自己的证书 # 设置成try就行,客户端不提供证书也能连接,反正连接已经加密了。 # 官方文档:http://www.openldap.org/doc/admin24/tls.html 启动ldap #第一次启动会比较慢,淡定点 docker-compose pull docker-compose up -d ls docker ps -a # 启动之后会生成几个文件夹 # ldapconf保存的是ldap的配置文件 # ldapdata保存的是ldap的数据 # lam保存的是lam管理工具的配置 [root@master LDAP]#docker-compose up -d Creating network "ldap_default" with the default driver Creating openldap ... done Creating ldap-account-manager ... done [root@master LDAP]#ls docker-compose.yaml lam ldapconf ldapdata ssl [root@master LDAP]#docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 9b4ebdad17eb jinyunboss/ldap-account-manager:6.6 "docker-php-entrypoi…" 2 minutes ago Up 2 minutes 0.0.0.0:8080->80/tcp ldap-account-manager a7ff3bd5dced osixia/openldap:1.2.2 "/container/tool/run" 2 minutes ago Up 2 minutes 0.0.0.0:389->389/tcp, 0.0.0.0:636->636/tcp openldap 打开浏览器,配置LDAP Account Manager LDAP Account Manager容器监听在8080端口 打开http://192.168.1.1:8080 # 配置一下lam管理页面 # lam管理界面默认密码是: lam # lam可以管理多个ldap服务器,所以可以拥有多个profile,每个profile对应一台服务器 # 简单添加个用户,然后用另一台linux机器测试ldap连接 测试LDAP 安装ldap客户端 yum install -y openldap-clients nss-pam-ldapd 配置配置客户端 # 配置系统使用ldap认证 authconfig-tui # 将自签名的ca证书给客户端 cd /etc/openldap/cacerts/ # 修改/etc/nslcd.conf,添加管理员凭据 echo "binddn cn=admin,dc=lotbrick,dc=com" >> /etc/nslcd.conf echo "bindpw admin" >> /etc/nslcd.conf cat /etc/nslcd.conf # 重启nslcd服务 systemctl restart nslcd 测试 # 执行命令看看能不能读取到LDAP用户 # 能连接上ldap的话,执行之后会出现ldap用户 getent passwd id bigboss # 切换成bigboss用户试试 su - bigboss