docker部署gitlab-runner
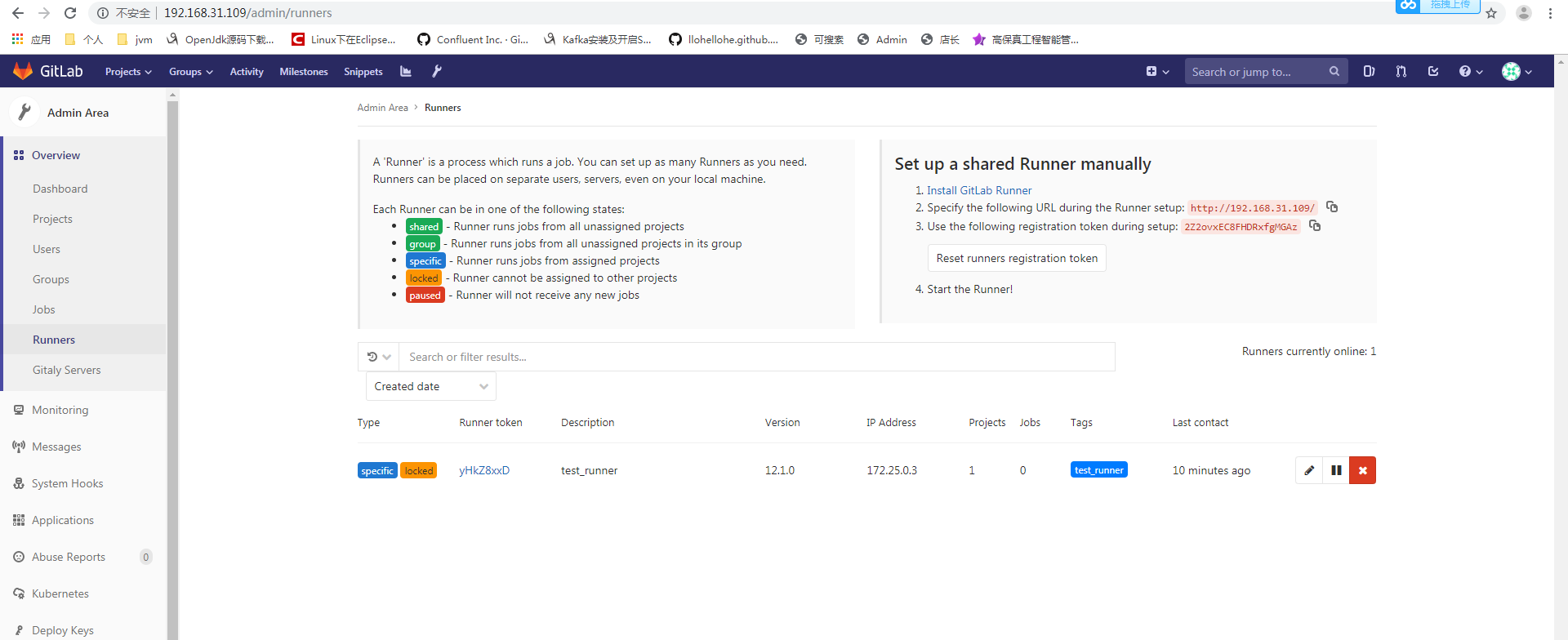
1、配置启动脚本 version: '3.1' services: gitlab-ce: image: 'gitlab/gitlab-ce:latest' container_name: gitlab-ce restart: always hostname: 'gitlab.localhost.com' environment: GITLAB_OMNIBUS_CONFIG: | external_url 'http://192.168.31.109' # external_url是项目生成时的前缀域名 ports: - '80:80' - '443:443' - '10022:22' volumes: - '/root/gitlab-ce/home/config:/etc/gitlab' - '/root/gitlab-ce/home/logs:/var/log/gitlab' - '/root/gitlab-ce/home/data:/var/opt/gitlab' networks: - 'default' gitlab-runner: image: 'gitlab/gitlab-runner:latest' container_name: gitlab-runner depends_on: - 'gitlab-ce' restart: always volumes: - '/root/gitlab-ce/runnerconfig:/etc/gitlab-runner' - '/var/run/docker.sock:/var/run/docker.sock' networks: - 'default' links: - 'gitlab-ce:gitlab.localhost.com' networks: default: driver: 'bridge' 两个容器使用gitlab.localhost.com一个域名,以便在注册runner时可以访问网络 2、注册runner docker-compose exec gitlab-runner /bin/bash # 连接进入 gitlab-runner 容器 gitlab-runner register # 进入容器后执行的命令 Please enter the gitlab-ci coordinator URL (e.g. https://gitlab.com/): http://gitlab.localhost.com # gitlab 的访问路径 Please enter the gitlab-ci token for this runner: JLP2Rk2qcUZEfs_WLrTv # 注册令牌,在 gitlab 中获取 Please enter the gitlab-ci description for this runner: [gitlab-runner]: test_runner # runner 的名字 Please enter the gitlab-ci tags for this runner (comma separated): test # runner 的 tag Registering runner... succeeded runner=JLP2Rk2q Please enter the executor: docker-ssh, parallels, docker+machine, docker-ssh+machine, docker, shell, ssh, virtualbox, kubernetes: docker # 使用 docker 作为输出模式 Please enter the default Docker image (e.g. ruby:2.1): alpine:latest # 使用的基础镜像 Runner registered successfully. Feel free to start it, but if it's running already the config should be automatically reloaded! ############################# 注册成功后会显示以上信息,然后执行下面的命令进行启动 ################################### gitlab-runner start # 启动该 runner 3、检查runner状态