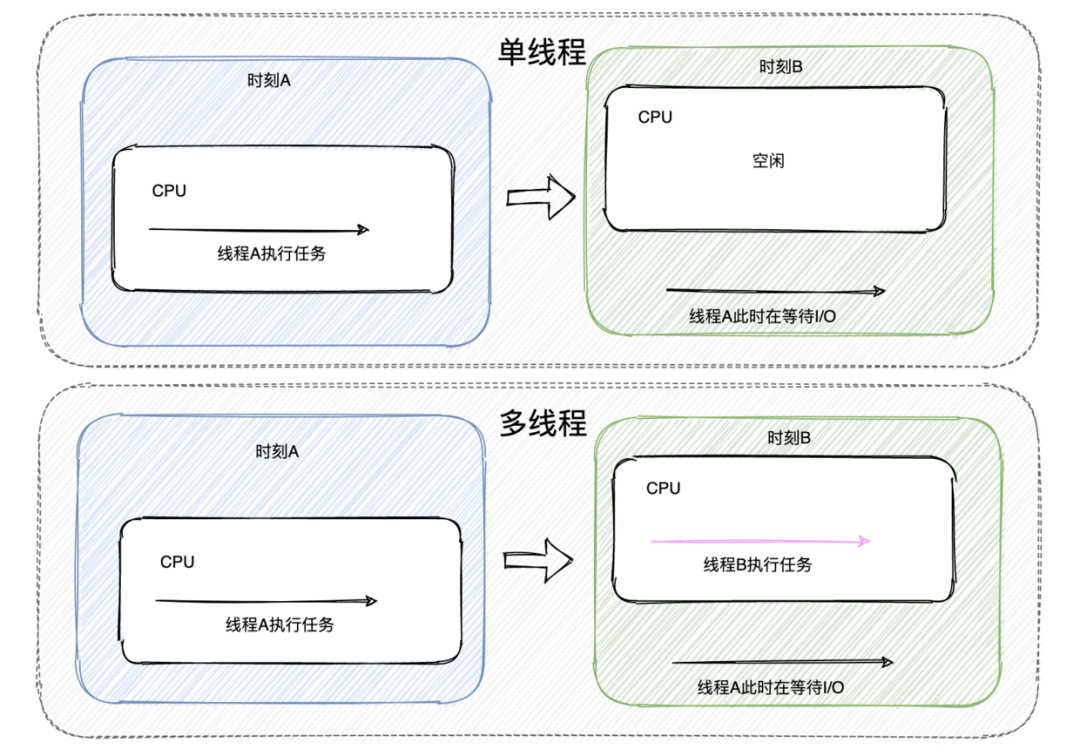
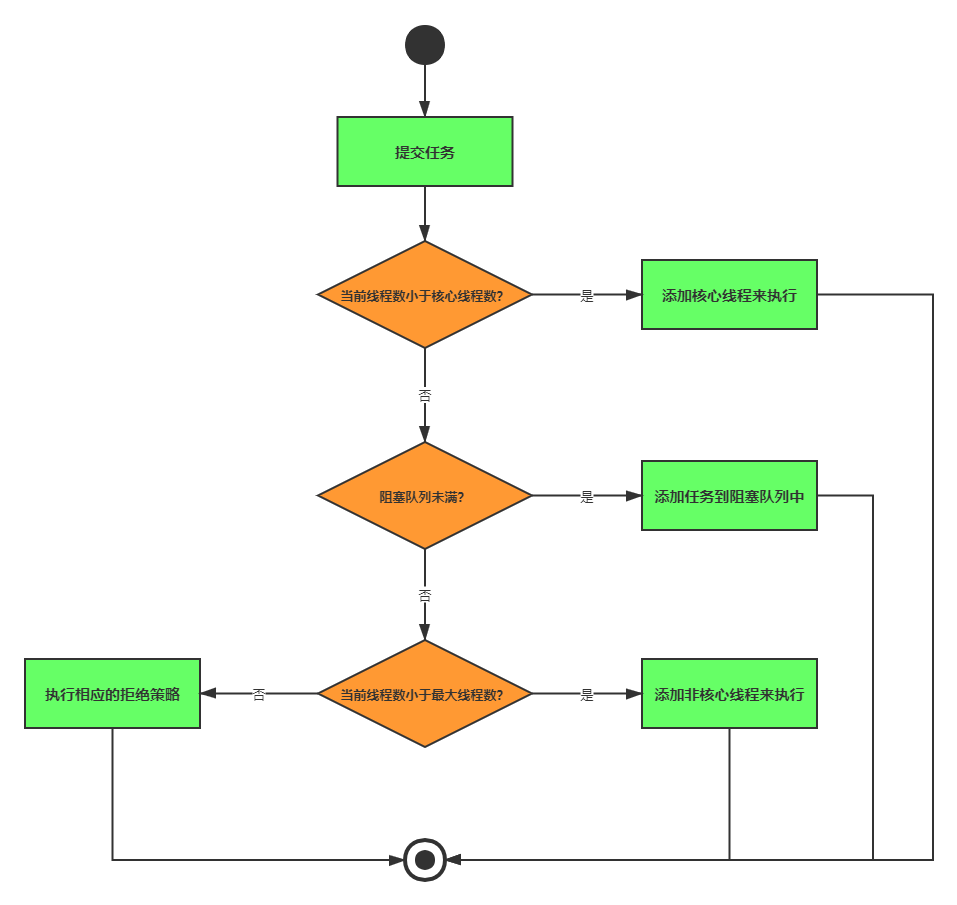
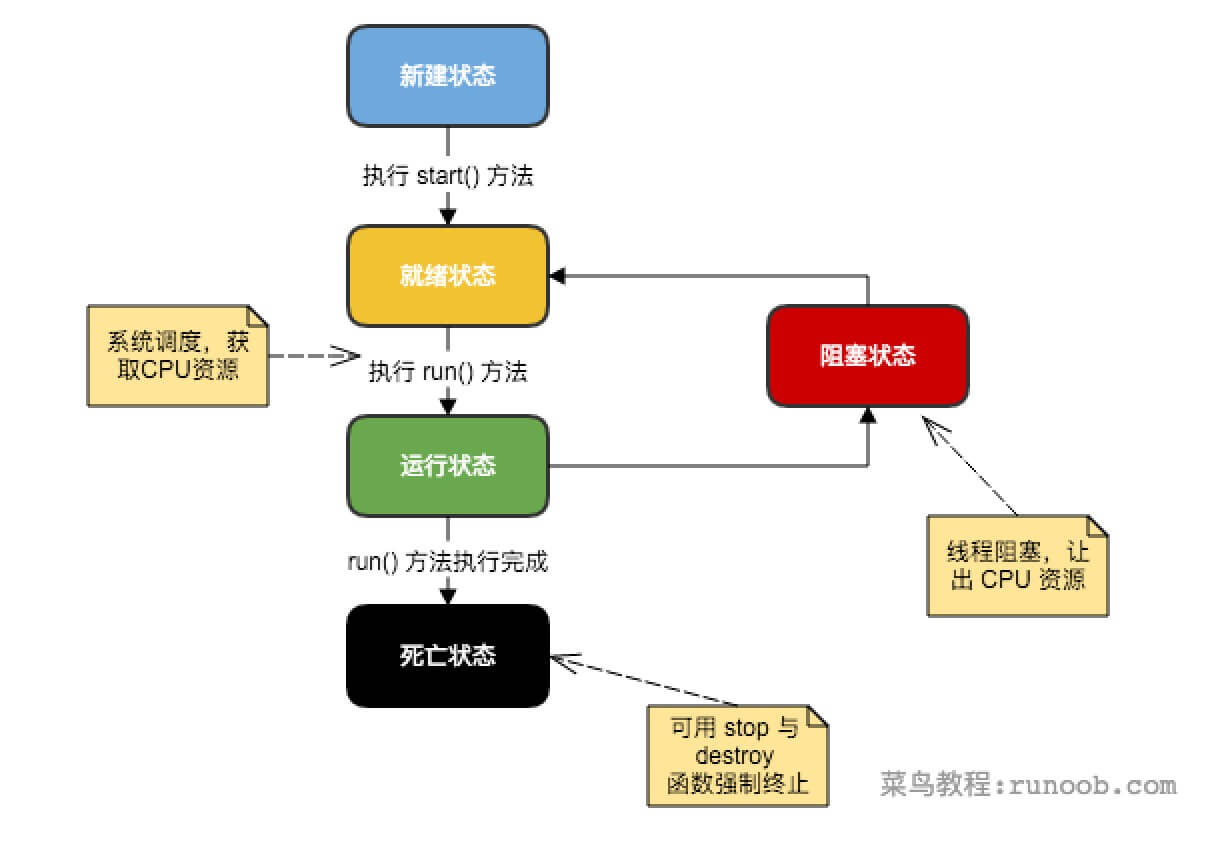
左神算法、牛客网算法、剑指java、Java后台面试宝典----个人总结(实习、春招、秋招)
第一节课 第一题:题意与leetcode354的问题相同算法原型 最长递增子序列问题 * 题意:求出给定序列的最长递增子序列的长度,给定序列不是有序的,子序列不是子数组,元素在原数组中不必是连续的 * */ /* * solutions1: 时间复杂度O(n^2),空间复杂度O(n) * 新建一个辅助数组h,h[i]表示以nums[i]结尾的最长递增子序列的长度 * h[i]值的确定,需要nums[i]与nums[j](0<=j<i)做比较,h[i] = h[j] + 1 (when nums[j] < nums[i]),找出这些值中的最大值即最终的nums[i] * 如果nums[i]最小的话,则h[i] = 1; * 因为h[i]值的确定需要nums[i]进行最多i-1次比较,所以时间复杂度为O(n^2) */ /* * solution2: 时间复杂度O(n*log(n)),空间复杂度O(n) * 新建一个辅助数组h,h[i]表示遍历到当前nums[j]位置时长度为i+1的递增子序列的最小末尾 * h填入值的部分称作有效区,还未填入值的部分称作无效区 * h[i]值的确定,h[0] = nums[0],在遍历nums 的同时,在h[i]中找到第一个大于等于nums[j]的数,并将其替换为为nums[j],如果没找到则将h有效区后一个元素置为nums[j] * h[i]会一直保持有序状态,所以找第一个大于等于nums[j]的数可以用二分法,最后返回h有效区的长度即可 * 由于在遍历的同时采用了时间复杂度为log(n)的二分查找,故时间复杂度为O(n*log(n)) */ /* * 实现solution2 */ public class LongestSubSequence { public int getLonggestLen(int[] nums) { int maxLen = 0; if (nums.length == 0) return maxLen; int[] h = new int[nums.length]; h[0] = nums[0]; maxLen = 1; for (int i = 1; i < nums.length; i++) { int pos = getPos(h, 0, maxLen - 1,nums[i]); if (pos == -1) { h[maxLen++] = nums[i]; } else h[pos] = nums[i]; } return maxLen; } public int getPos(int[] h, int left, int right, int num) { if (left <= right) { int mid = left + (right - left) / 2; if (h[mid] >= num) { int pos = getPos(h, left, mid - 1, num); if (pos == -1) return mid; return pos; } else { return getPos(h, mid + 1, right, num); } } return -1; } public static void main(String[] args){ LongestSubSequence l = new LongestSubSequence(); int[] nums = {1,3,6,7,9,4,10,5,6}; l.getLonggestLen(nums); } } 第二题 * 题意:详见2016 《牛课堂第一节课课件.pdf》第2题,leetcode42原题 */ /* * solution1:时间复杂度 O(n) 空间复杂度O(n) * 首先简化一下题意:如果能求得当前位置格子上的水量,那么总水量就是每个位置水量之和 * 当前格子上所能存储的水量 = 当前格子左边最大值与右边最大值之间的较小值 - 当前格子高度 * 所以要先求出当前格子左边的最大值与右边最大值,对于右边最大值用数组r来辅助存储,从右往左遍历一下原数组即可得到r * 对于左边的最大值在遍历原数组的同时用一个全局变量记录下来就行,此时时间复杂度为O(n) 空间复杂度O(n),还没达到最优解 * * solution2:时间复杂度 O(n) 空间复杂度O(1) * 为了不使用辅助数组,我们采用双指针的方法 * 双指针left和right分别指向数组的第二个元素和倒数第二个元素,由题意可知第一个元素和最后一个元素的储水量都是零 * 当前元素的遍历则从第二个和倒数第二个元素开始,用leftMax和rightMax分别记录左边最大值和右边最大值,用一个全局变量totalWater 更新总的储水量 * 若leftMax < rightMax则结算左指针height[left],leftMax > height[left]时,totalWater += leftMax - height[left++],反之更新左边最大值leftMax = height[left++],左指针向右移一位; * 反之,结算右边的当前元素,过程与左边类似 */ public class Question1 { public int getWater(int[] height){ if (height == null || height.length < 3) return 0; int totalWater = 0; int left = 1, right = height.length - 2; int leftMax = height[0], rightMax = height[height.length - 1]; while (left <= right) { if (leftMax < rightMax) { if (leftMax > height[left]) { totalWater += leftMax - height[left++] ; } else { leftMax = height[left++]; } } else { if (rightMax > height[right]) { totalWater += rightMax - height[right--] ; } else { rightMax = height[right--]; } } } return totalWater; } public static void main(String[] args){ Question1 q = new Question1(); int[] height = {0,1,0,2,1,0,1,3,2,1,2,1}; q.getWater(height); } }