最简单的clean架构实践
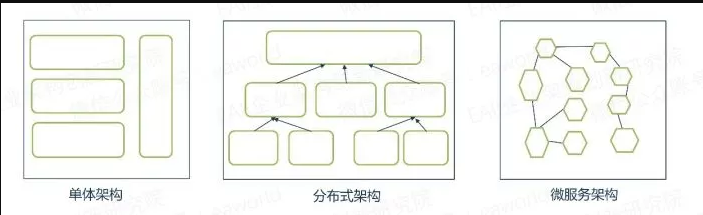
参考 参考的是学习 CleanArchitecture 心得体会 参考的代码是brzhang的项目 Clean架构 一直都想学Clean架构,今天终于实践了一个简单的CleanDemo,对Clean架构有了进一步的认识。其实Clean就是在MVP架构的基础上做进一步的分层,让每一层更薄,使得代码复用性更高,更易于测试,耦合度更小。 但是最大的缺点就是要定义很多类,很多接口,就一个小小的连个界面,几个简单的功能也要写很多代码,如果用在小项目上的话感觉有点大材小用,所以这种架构一般应用于中大型项目更划算吧。不过应用于小项目拿来练手也是可以的 对架构的简单理解 先上googlesample的图 googleSample uncle-Bob的图 uncle-bob 其实两幅图大体是一样的,主要分三层,分别是DataLayer,DomainLayer,PresentationLayer,依次由低到高,每一层只依赖它的下面一层,而且用上响应式编程如rxjava的话,一般是DataLayer,DomainLayer提供或进一步封装可被观测的对象,PresentationLayer是观测者,不过我看了几个例子都是用了响应编程了 DataLayer 例如这个目录 dataLayer 核心repository 具体结构 数据层,最底层,一般这个层是提供原始的数据接口的,方便给DomainLayer提供数据,至于它怎么实现获取数据,DomainLayer就不用管,你调用就是。可以看到上面核心的还是要有个Repository这个类,但因为界面要用的数据来源可以是本地数据库(Local),也可以使网络获取(remote)的。这种情况缓存功能会遇到,这样就是可像上图那样定义一个接口,然后定义不同实现这个接口的类,一个local的,一个remote的。至于具体怎么实现,那就随便你使用哪种方式了,比如可以数据库框架Realm,Room,GreenDao,网络请求比如Retrofit,Okhttp3那些。而且这一层有个特点,如果不使用数据库(因为用数据库肯定会用到Android的Context),那么这一层代码是不涉及Android库的,这样的话可以直接用Junit测试这一层。 DomainLayer domain 中间层,他完全不知道有一个PresentationLayer存在,只知道有DataLayer,他可以基于这些数据,做进一步的处理封装,对,主要职责就是控制DataLayer对数据做增删改查。 比如这有个例子 public Observable<List<SampleModel>> getDatasFromMutil(){ return Observable.concat(localSampleRepository.lists(100,1),remoteSampleRepository.lists(100,1)) .first(new Func1<List<SampleModel>, Boolean>() { @Override public Boolean call(List<SampleModel> sampleModels) { // TODO: 2017/10/6 这里可以做一缓存设置,比如缓存时间 Log.d(TAG, "call: >>>>>有无缓存?"+(sampleModels!=null&&sampleModels.size()>0)); return sampleModels!=null&&sampleModels.size()>0; } }).doOnNext(new Action1<List<SampleModel>>() { @Override public void call(List<SampleModel> sampleModels) { // 缓存在数据库 Realm realm = Realm.getDefaultInstance(); realm.beginTransaction(); realm.copyToRealmOrUpdate(sampleModels); realm.commitTransaction(); } }); } 这个方法就是一个Case类里的,功能就是如果本地数据库有缓存的数据就直接取出这个数据并返回,如果没有就从网络获取,并且把请求的数据缓存到本地数据库,这个使用了Rxjava的first,concat操作符来实现,十分巧妙。说到底就是对DataLayer层数据的进一步封装,当然不同的业务你可以灵活定义多个Case分开,如果不涉及Android数据库或SP的话,也是没有Android的代码的 PresentationLayer 显示层 这一层可以做进一步的分层,比如VP层,VVM层,和通常的MVP,MVVM用法差不多