ELK日志系统之使用Rsyslog快速方便的收集Nginx日志
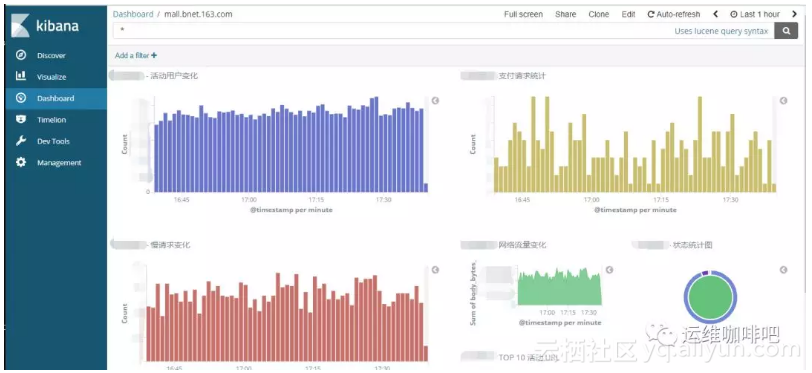
Rsyslog Rsyslog是高速的日志收集处理服务,它具有高性能、安全可靠和模块化设计的特点,能够接收来自各种来源的日志输入(例如:file,tcp,udp,uxsock等),并通过处理后将结果输出的不同的目的地(例如:mysql,mongodb,elasticsearch,kafka等),每秒处理日志量能够超过百万条。 Rsyslog作为syslog的增强升级版本已经在各linux发行版默认安装了,无需额外安装。 收集Nginx日志 ELK通过Rsyslog收集日志流程图如下: ● 处理流程为:Nginx --syslog--> Rsyslog --omkafka--> Kafka --> Logstash --> Elasticsearch --> Kibana● Nginx产生日志通过syslog系统服务传给Rsyslog服务端,Rsyslog接收到日志后通过omkafka模块将日志写入Kafka,Logstash读取Kafka队列然后写入Elasticsearch,用户通过Kibana检索Elasticsearch里存储的日志 ● Rsyslog服务系统自带无需安装,所以整个流程中客户端不需要额外安装应用 ● 服务端虽然Rsyslog也已安装,但默认没有omkafka模块,如果需要Rsyslog写入Kafka需要先安装这个模块 ● omkafka模块在rsyslog v8.7.0之后的版本才支持,所以需要先通过rsyslogd -v命令查看rsyslog版本,如果版本较低则需要升级 Rsyslog升级 1.添加rsyslog源的key # apt-key adv --recv-keys --keyserver keys.gnupg.net AEF0CF8E 2.添加rsyslog源地址 echo "deb http://debian.adiscon.com/v8-stable wheezy/" >> /etc/apt/sources.list echo "deb-src http://debian.adiscon.com/v8-stable wheezy/" >> /etc/apt/sources.list 3.升级rsyslog服务 # apt-get update && apt-get -y install rsyslog 添加omkafka模块 1.安装编译工具,下边autoreconf需要用到,不然无法生成configure文件 # apt-get -y install pkg-config autoconf automake libtool unzip 2.omkafka需要安装一堆的依赖包 # apt-get -y install libdbi-dev libmysqlclient-dev postgresql-client libpq-dev libnet-dev librdkafka-dev libgrok-dev libgrok1 libgrok-dev libpcre3-dev libtokyocabinet-dev libglib2.0-dev libmongo-client-dev libhiredis-dev # apt-get -y install libestr-dev libfastjson-dev uuid-dev liblogging-stdlog-dev libgcrypt-dev # apt-get -y install flex bison librdkafka1 librdkafka-dev librdkafka1-dbg 3.编译安装omkafka模块 # mkdir tmp && cd tmp # git init # git pull git@github.com:VertiPub/omkafka.git # autoreconf -fvi # ./configure --sbindir=/usr/sbin --libdir=/usr/lib --enable-omkafka && make && make install && cd .. Rsyslog收集nginx日志 Client端Nginx配置 log_format jsonlog '{' '"host": "$host",' '"server_addr": "$server_addr",' '"http_x_forwarded_for":"$http_x_forwarded_for",' '"remote_addr":"$remote_addr",' '"time_local":"$time_local",' '"request_method":"$request_method",' '"request_uri":"$request_uri",' '"status":$status,' '"body_bytes_sent":$body_bytes_sent,' '"http_referer":"$http_referer",' '"http_user_agent":"$http_user_agent",' '"upstream_addr":"$upstream_addr",' '"upstream_status":"$upstream_status",' '"upstream_response_time":"$upstream_response_time",' '"request_time":$request_time' '}'; access_log syslog:server=rsyslog.domain.com,facility=local7,tag=nginx_access_log,severity=info jsonlog; 1.Nginx在v1.10之后的版本才支持syslog的方式处理日志,请确保你的Nginx版本高于1.10 2.为了降低logstash的处理压力,同时也为了降低整个配置的复杂度,我们nginx的日志直接采用json格式 3.抛弃文本文件记录nginx日志,改用syslog直接将日志传输到远端的rsyslog服务器,以便我们后续的处理;这样做的另一个非常重要的好处是我们再也无需考虑nginx日志的分割和定期删除问题(一般我们为了方便管理通常会采用logrotate服务来对日志进行按天拆分和定期删除,以免磁盘被占满) 4.access_log直接输出到syslog服务,各参数解释如下: ●syslog:指明日志用syslog服务接收 ●server:接收syslog发送日志的Rsyslog服务端地址,默认使用udp协议,端口是514 ●facility:指定记录日志消息的类型,例如认证类型auth、计划任务cron、程序自定义的local0-7等,没有什么特别的含义,不必深究,默认的值是local7 ●tag:给日志添加一个tag,主要是为了方便我们在服务端区分是哪个服务或者client传来的日志,例如我们这里给了tag: nginx_access_log,如果有多个服务同时都写日志给rsyslog,且配置了不通的tag,在rsyslog服务端就可以根据这个tag找出哪些是nginx的日志 ●severity:定义日志的级别,例如debug,info,notice等,默认是error Server端Rsyslog配置 # cat /etc/rsyslog.d/rsyslog_nginx_kafka_cluster.conf module(load="imudp") input(type="imudp" port="514") # nginx access log ==> rsyslog server(local) ==> kafka module(load="omkafka") template(name="nginxLog" type="string" string="%msg%") if $inputname == "imudp" then { if ($programname == "nginx_access_log") then action(type="omkafka" template="nginxLog" broker=["10.82.9.202:9092","10.82.9.203:9092","10.82.9.204:9092"] topic="rsyslog_nginx" partitions.auto="on" confParam=[ "socket.keepalive.enable=true" ] ) } :rawmsg, contains, "nginx_access_log" ~ 1.在rsyslog.d目录下添加一个专门处理nginx日志的配置文件 2.rsyslog配置文件重要配置解释如下: ●module:加载模块,这里我们需要加载imudp模块来接收nginx服务器syslog发过来的日志数据,也需要加载omkafka模块来将日志写入到kafka ●input:开启udp协议,端口514,也可以同时开启tcp协议,两者可以共存 ●template:定义一个模板,名字叫nginxLog,模板里可以定义日志的格式,因为我们传的已经是json了,不需要再匹配格式,所以这里不额外定义,注意模板名字要唯一 ●action:在匹配到inputname为imudp且programname为nginx_access_log(就是我们上边nginx配置里边的tag)之后的处理方式,这里的配置为匹配到的日志通过omkafka模块写入kafka集群,还有一些关于omkafka更详细的配置参考上边给出的omkafka模块官方文档 ●:rawmsg, contains:最后这一行的意思是忽略包含nginx_access_log的日志,没有这一行的话rsyslog服务默认会把所有日志都记录到message里边一份,我们已经把日志输出到kafka了,本地就没必要再记录了 3.omkafka模块检查kafka里边topic是否存在,如果不存在则创建,无需手动创建kafka的topic Server端logstash配置 input { kafka { bootstrap_servers => "10.82.9.202:9092,10.82.9.203:9092,10.82.9.204:9092" topics => ["rsyslog_nginx"] } } filter { mutate { gsub => ["message", "\\x", "\\\x"] } json { source => "message" } date { match => ["time_local","dd/MMM/yyyy:HH:mm:ss Z"] target => "@timestamp" } } output { elasticsearch { hosts => ["10.82.9.205", "10.82.9.206", "10.82.9.207"] index => "rsyslog-nginx-%{+YYYY.MM.dd}" } } 重要配置参数解释如下: ● input:配置kafka的集群地址和topic名字 ● filter:一些过滤策略,因为传入kafka的时候是json格式,所以不需要额外处理,唯一需要注意的是如果日志中有中文,例如url中有中文内容时需要替换 \x,不然json格式会报错 ●output:配置ES服务器集群的地址和index,index自动按天分割 联调测试 配置完成后分别重启rsyslog服务和nginx服务,访问nginx产生日志 1.查看kafka是否有正常生成topic # bin/kafka-topics.sh --list --zookeeper 127.0.0.1:2181 __consumer_offsets rsyslog_nginx 2.查看topic是否能正常接收日志 # bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic rsyslog_nginx {"host": "domain.com","server_addr": "172.17.0.2","http_x_forwarded_for":"58.52.198.68","remote_addr":"10.120.89.84","time_local":"28/Aug/2018:14:26:00 +0800", "request_method":"GET","request_uri":"/","status":200,"body_bytes_sent":1461,"http_referer":"-","http_user_agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36","upstream_addr":"-","upstream_status":"-", "upstream_response_time":"-","request_time":0.000} 3.kibana添加index,查看Elasticsearch中是否有数据,如果前两步都正常,kibana搜不到index或index没有数据,多半是index名字写错了之类的基础问题,仔细检查 kibana查询展示 ●打开Kibana添加rsyslog-nginx-*的Index,并选择timestamp,创建Index Pattern ●进入Discover页面,可以很直观的看到各个时间点请求量的变化,根据左侧Field实现简单过滤,例如我们想查看所有访问状态为404的uri,可以点击request_uri和status后边的add,这两项的内容将出现在右侧,然后点击status下边404状态码后边的加号,则只查看状态为404的请求,点击上方auto-refresh可以设置页面自动刷新时间 ●通过各种条件的组合查询可以实现各种各样的需求,例如每秒请求、带宽占用、异常比例、慢响应、TOP IP、TOP URL等等各种情况,并且可以通过Visualize很方便的将这些信息绘制图标,生成Dashboard保存 写在最后 ●Nginx的access log绝对是网站的一个宝藏,通过日志量的变化可以知道网站的流量情况,通过对status状态的分析可以知道我们提供服务的可靠性,通过对特定活动url的追踪可以实时了解活动的火爆程度,通过对某些条件的组合查询也能为网站运营提供建议和帮助,从而使我们的网站更友好更易用 ●Rsyslog服务的单点问题可以通过部署多个Rsyslog服务过三层负载来保证高可用,不过以我们的经验来说rsyslog服务还是很稳定的,跑了一年多,每分钟日志处理量在20w左右,没有出现过宕机情况,不想这么复杂的话可以写个check rsyslog服务状态的脚本跑后台,挂了自动拉起来 ●整个过程中我们使用了UDP协议,第一是因为Nginx日志的syslog模式默认支持的就是UDP协议,翻了官网没找到支持TCP的方式,我想这也是考虑到UDP协议的性能要比TCP好的多,第二也考虑到如果使用TCP遇到网络不稳定的情况下可能会不停的重试或等待,影响到Nginx的稳定。对于因为内容过长超过以太网数据帧长度的问题暂时没有遇到 原文发布时间为:2018-08-30 本文作者:37丫37 本文来自云栖社区合作伙伴“ 运维咖啡吧”,了解相关信息可以关注“ 运维咖啡吧”。