C语言是所有编程语言的基础,当我们对C语言有足够深入的理解后,就能轻松入门其他语言,比如现在流行的Python。现在,我将带领大家看一个基于C语言经典算法,使用Python编写的塔防小游戏。
在塔防游戏中,有许多敌人向着同一目标前进。在很多塔防游戏当中,有一条或几条事先预定好的路径。在一些中,比如经典的《Desktop Tower Defense》,你可以将塔放在任何位置,它们充当障碍影响敌人选择的路径。试一试,点击地图来移动墙壁:
![01]()
我们如何来实现这种效果?
像A*这样的图搜索算法经常被用来寻找两点之间的最短路径。你可以用这个来为每一个敌人找到前往目标的路径。在这种类型的游戏当中,我们有很多不同的图搜索算法来。这是一些经典方法
单源,单目标:
单源多目标或多源单目标
- 广度优先算法-无加权边
- Dijkstra算法-有加权边
- Bellman-Ford算法-支持负权重
多源多目标
- Floyd-Warshall算法
- Johnson’s算法
像《Desktop Tower Defense》这样的游戏会有很多个敌人(源)和一个共同的目的地。这使得它被归为多源单目标一类。我们可以执行一个算法,一次算出所有敌人的路径,而不是为每个敌人执行一次A*算法。更好的是,我们可以计算出每个位置的最短路径,所以当敌人挤在一块或者新敌人被创建时,他们的路径已经被计算好了。
我们先来看看有时也被称作“洪水填充法”(FIFO变种)的广度优先算法。虽然图搜索算法是适用于任何由节点和边构成的图,但是我还是使用方形网格来表示这些例子。网格是图的一个特例。每个网格瓦片是图节点,网格瓷砖之间的边界是图的边。我会在另一篇文章当中探讨非网格图。
广度优先搜索始于一个节点,并访问邻居节点。关键的概念是“边界”,在已探索和未开发的区域之间的边界。边界从原始节点向外扩展,直到探索了整张图。
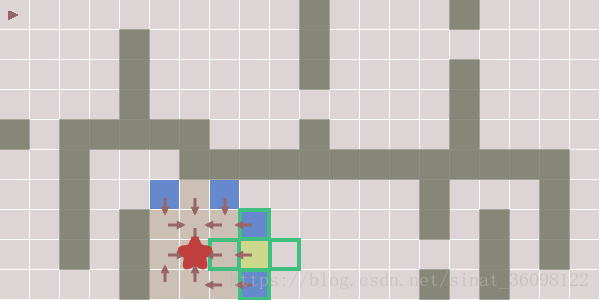
边界队列是一个图节点(网格瓦片)是否需要被分析的列表/数组。它最开始仅仅包含一个元素,起始节点。每个节点上的访问标志追踪我们是否采访过该节点。开始的时候除了起始节点都标志为FALSE。使用滑块来查看边界是如何扩展的:
![02]()
这个算法是如何工作的?在每一步,获得一个元素的边界并把它命名为current。然后寻找current的每个邻居,next。如果他们还没有被访问过的话,将他们都添加到边界队列里面。下面是一些python代码:
Python
frontier = Queue()
frontier.put(start)
visited = {}
visited[start] = True
while not frontier.empty():
current = frontier.get()
for next in graph.neighbors(current):
if next not in visited:
frontier.put(next)
visited[next] = True
frontier = Queue()
frontier.put(start)
visited = {}
visited[start] = True
while not frontier.empty():
current = frontier.get()
for next in graph.neighbors(current):
if next not in visited:
frontier.put(next)
visited[next] = True
现在已经看见代码了,试着步进上面的动画。注意边界队列,关于current的代码,还有next节点的集合。在每一步,有一个边界元素成为current节点,它的邻居节点会被标注,并且未被拜访过的邻居节点会被添加到边界队列。有一些邻居节点可能已经被访问过,他们就不需要被添加到边界队列里面了。
这是一个相对简单的算法,并且对于包括AI在内的很多事情都是有用的。我有三种主要使用它的办法:
1.标识所有可达的点。这在你的图不是完全连接的,并且想知道哪些点是可达的时候是很有用的。这就是我再上面用visited这部分所做的。
2.寻找从一个点到所有其他点或者所有点到一个点的路径。我在文章开始部分的动画demo里面使用了它。
3.测量从一个点到所有其他点的距离。这在想知道一个移动中的怪物的距离时是很有用的。
如果你正在生成路径,你可能会想知道从每个点移动的方向。当你访问一个邻居节点的时候,要记得你是从哪个节点过来的。让我们把visited重命名为came_from并且用它来保存之前位置的轨迹:
Python
frontier = Queue()
frontier.put(start)
came_from = {}
came_from[start] = None
while not frontier.empty():
current = frontier.get()
for next in graph.neighbors(current):
if next not in came_from:
frontier.put(next)
came_from[next] = current
frontier = Queue()
frontier.put(start)
came_from = {}
came_from[start] = None
while not frontier.empty():
current = frontier.get()
for next in graph.neighbors(current):
if next not in came_from:
frontier.put(next)
came_from[next] = current
我们来看看它看起来是怎样的:
![03]()
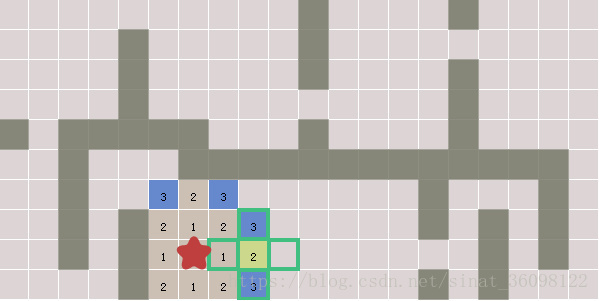
如果你需要距离,你可以在起始节点讲一个计数器设置为0,并在每次访问邻居节点的时候将它加一。让我们把visitd重命名为distance,并且用它来存储一个计数器:
Python
frontier = Queue()
frontier.put(start)
distance = {}
distance[start] = 0
while not frontier.empty():
current = frontier.get()
for next in graph.neighbors(current):
if next not in distance:
frontier.put(next)
distance[next] = 1 + distance[current]
frontier = Queue()
frontier.put(start)
distance = {}
distance[start] = 0
while not frontier.empty():
current = frontier.get()
for next in graph.neighbors(current):
if next not in distance:
frontier.put(next)
distance[next] = 1 + distance[current]
我们来看看它看起来是怎样的:
![04]()
如果你想同时计算路径和距离,你可以使用两个变量。
这就是广度优先检索算法。对于塔防风格的游戏,我用它来计算所有位置到一个指定位置的路径,而不是重复使用A*算法为每个敌人分开计算路径。我用它来寻找一个怪物指定行动距离内所有的位置。我也是用它来进行程序化的地图生成。Minecraft使用它来进行可见性提出。由此可见这是一个不错的算法。
下一步
我有python和c++代码的实现。 如果你想要找到从一个点出发而不是到达一个点的路径,只需要在检索路径的时候翻转came_from指针。
如果你想要知道一些点而不是一个点的路径,你可以在图的边缘为你的每个目标点添加一个额外的点。额外的点不会出现在网格中,但是它会表示在图中的目标位置。 提前退出:如果你是在寻找一个到达某一点或从某一点出发,。我在A*算法的文章当中描述了这种情况。
加权边:如果你需要不同的移动成本,广度优先搜索可以替换为为Dijkstra算法。我在A*算法的文章当中描述了这种情况。
启发:如果你需要添加一种指导寻找目标的方法,广度优先算法可以替换为最佳优先算法。我在A*算法的文章当中描述了这种情况。
如果你从广度优先算法,并且加上了提前退出,加权边和启发,你会得到A*。如你所想,我在A*算法的文章当中描述了这种情况。
满满的自豪感,真的很想知道大家的想法,还请持续关注更新,更多干货和资料请直接联系我,也可以加群710520381,邀请码:柳猫,欢迎大家共同讨论