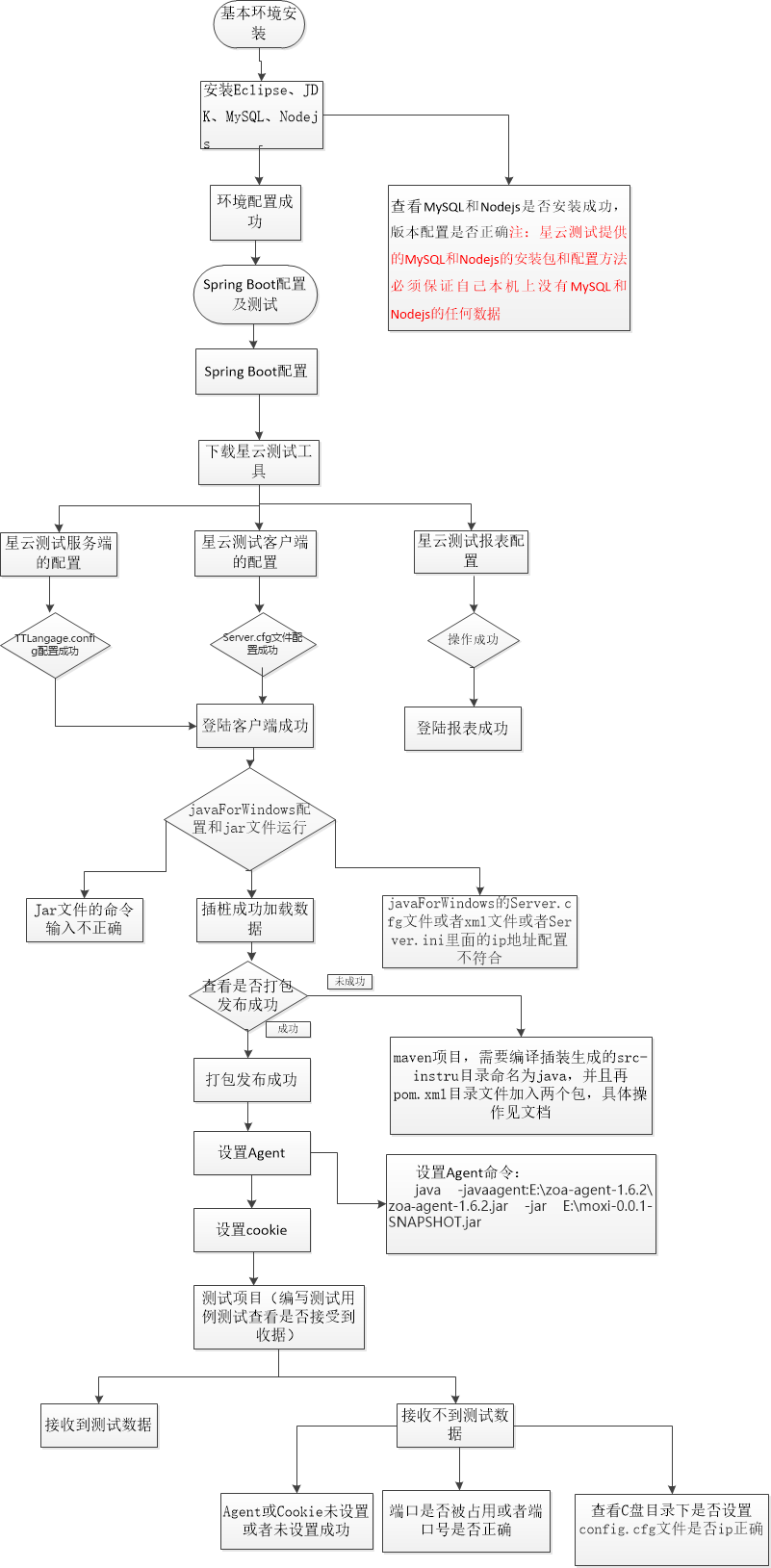
如何解决spark开发中遇到需要去掉文件前几行数据的问题
版权声明:本文由董可伦首发于https://dongkelun.com,非商业转载请注明作者及原创出处。商业转载请联系作者本人。 https://blog.csdn.net/dkl12/article/details/80550095 我的原创地址:https://dongkelun.com/2018/05/27/sparkDelFirstNLines/ 前言 我碰到的问题是这样的,我需要读取压缩文件里的数据存到hive表里,压缩文件解压之后是一个txt,这个txt里前几行的数据是垃圾数据,而这个txt文件太大,txt是直接打不开的,所以不能手动打开删除前几行数据,而这个文件是业务人员从别人那拿到的所以也不能改,本文就是讲如何解决这个问题。 1、数据 首先造几条数据,以理解我的需求 data.txt id name addr time ------------ ------------------- --------------- -------------------- 1 zhangsan shanghai 2018-05-25 2 zhangsan shanghai 2018-05-25 3 zhangsan shanghai 2018-05-25 4 zhangsan shanghai 2018-05-25 5 zhangsan shanghai 2018-05-25 其中前三行是我不想要的数据,第一行为空,第二行为字段名,第三行应该是为了美观单独加了一行。 2、尝试用代码解决 2.1 思路一 用zipWithIndex给rdd加上索引,索引从0开始依次次递增1 val path = "files/data.txt" val rdd = sc.textFile(path) println("分区数:" + rdd.getNumPartitions) val rdd1 = rdd.zipWithIndex() //过滤掉索引小于等于2的 val rdd2 = rdd1.filter(_._2 > 2) rdd1.foreach(println) println("**********分割线***********") rdd2.map(kv => kv._1).foreach(println) 分区数:1 (,0) (id name addr time ,1) (------------ ------------------- --------------- --------------------,2) (1 zhangsan shanghai 2018-05-25,3) (2 zhangsan shanghai 2018-05-25,4) (3 zhangsan shanghai 2018-05-25,5) (4 zhangsan shanghai 2018-05-25,6) (5 zhangsan shanghai 2018-05-25,7) **********分割线*********** 1 zhangsan shanghai 2018-05-25 2 zhangsan shanghai 2018-05-25 3 zhangsan shanghai 2018-05-25 4 zhangsan shanghai 2018-05-25 5 zhangsan shanghai 2018-05-25 将rdd的分区改为8(大于1即可)测试一下 将 val rdd = sc.textFile(path) 改为 val rdd = sc.textFile(path, 8) 发现结果是一样的 因为我不太熟悉读取本地数据分区和读取hdfs数据分区的是否一样,所以将数据放在分布式的hdfs上测试一下 首先将data.txt上传的hdfs上 hadoop fs -put data.txt /tmp/dkl/ 将代码中的path改为 val path = "hdfs://ambari.master.com:8020/tmp/dkl/data.txt" 发现最后的结果也是一样的(分区数可能不一样) 那么这样看来这个思路是可以解决这个问题的,但是我举得例子数据量比较少,在实际工作中数据量大的话,用zipWithIndex会有性能问题。 2.2 思路2 尝试直接获取rdd的前几行数据,然后过滤掉这几行数据,但是这个前提是前几行数据在rdd里是唯一的,否在会过滤掉其他行一样的数据,我的使用场景是删掉垃圾数据,如果其他行也有一样的数据,那么正好删掉了~ val path = "files/data.txt" val rdd = sc.textFile(path, 8) println("分区数:" + rdd.getNumPartitions) //前三条 val arr = rdd.take(3) //过滤掉arr里的数据 val rdd3 = rdd.filter(!arr.contains(_)) rdd3.foreach(println) 结果 分区数:8 1 zhangsan shanghai 2018-05-25 2 zhangsan shanghai 2018-05-25 3 zhangsan shanghai 2018-05-25 4 zhangsan shanghai 2018-05-25 5 zhangsan shanghai 2018-05-25 从结果看是可以解决我的问题,且和分区多少无关,大家可以试一下。 2.3 关于rdd前几行的定义 一开始我对于rdd前几行的数据的定义是有疑惑的,不知道改变rdd分区的数目,通过rdd.first或者rdd.take获取到的前几条数据是否是固定的,此次通过写代码测试,确定是和分区无关的,而且我担心测试数据量过小,将1.5G的txt放在hdfs测试,并且不指定分区数目(默认)进行测试,发现分区默认大小13,前几行数据依旧是固定,由此更加确认和rdd分区无关。 2.4 关于rdd重新分区 可通过repartition和coalesce对rdd进行重新分区,通过如下代码测试 rdd.repartition(3).take(3).foreach(println) rdd.coalesce(3).take(3).foreach(println) 通过结果得出coalesce之后顺序和之前的顺序是一样的,而repartition之后的顺序和之前不一样了,也就是如果rdd进行repartition之后的前几行和原来的前几行是不一样的,但是重新分区的数目固定的话,每次repartition之后的顺序是一样的。 注:repartition 内部实现调用的 coalesce 且为coalesce中 shuffle = true的实现 关于Spark中repartition和coalesce的使用场景,参考Spark中repartition和coalesce的区别与使用场景解析 因为我没有repartition的需求,所以可以通过2.2的代码解决我的问题,且如果有repartition的需求,可以在删掉前几行之后再repartition~ 3、通过Linux命令删除文件前几行 命令如下: cat data.txt id name addr time ------------ ------------------- --------------- -------------------- 1 zhangsan shanghai 2018-05-25 2 zhangsan shanghai 2018-05-25 3 zhangsan shanghai 2018-05-25 4 zhangsan shanghai 2018-05-25 5 zhangsan shanghai 2018-05-25 tail -n+4 data.txt > data_new.txt cat data_new.txt 1 zhangsan shanghai 2018-05-25 2 zhangsan shanghai 2018-05-25 3 zhangsan shanghai 2018-05-25 4 zhangsan shanghai 2018-05-25 5 zhangsan shanghai 2018-05-25 mv data_new.txt data.txt mv:是否覆盖"data.txt"? y cat data.txt 1 zhangsan shanghai 2018-05-25 2 zhangsan shanghai 2018-05-25 3 zhangsan shanghai 2018-05-25 4 zhangsan shanghai 2018-05-25 5 zhangsan shanghai 2018-05-25 注:其中的cat只是为了便于理解每个操作步骤之后的结果 这样就可以删除文件前三条数据了,之后压缩,上传到hdfs再用spark程序处理即可 参考:linux删除大文件的前n行 4、最后 不知道我对spark的分区的理解是否正确,如果不对的话,欢迎大家提出指正~ 附录 最后附上将此格式的txt文件读取为rdd并转为df的示例程序 package com.dkl.leanring.spark.sql import org.apache.spark.sql.Row import org.apache.spark.sql.SparkSession import org.apache.spark.sql.types.StringType import org.apache.spark.sql.types.StructField import org.apache.spark.sql.types.StructType object Demo { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().appName("DelFirstNLines").master("local").getOrCreate() val sc = spark.sparkContext val path = "files/data.txt" val data = sc.textFile(path, 8) val arr = data.take(3) val rdd = data.filter(!arr.contains(_)) //第二行为列名 val colName = arr(1).split(" +") // +表示根据一个或多个空格进行分割 val schema = StructType(colName.map(fieldName => StructField(fieldName, StringType, true))) val rowRDD = rdd.map(_.split(" +")).map(p => Row(p: _*)) val df = spark.createDataFrame(rowRDD, schema) df.show() spark.stop() } } +---+--------+--------+----------+ | id| name| addr| time| +---+--------+--------+----------+ | 1|zhangsan|shanghai|2018-05-25| | 2|zhangsan|shanghai|2018-05-25| | 3|zhangsan|shanghai|2018-05-25| | 4|zhangsan|shanghai|2018-05-25| | 5|zhangsan|shanghai|2018-05-25| +---+--------+--------+----------+