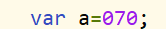Storm学习总结
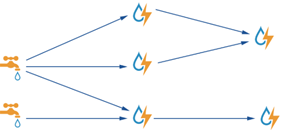
分享的目的 让大家更加深入了解Storm的架构以及运用JStorm之类的流式计算框架解决业务开发过程中遇到的问题能够有所帮助 分享大纲 Storm介绍和系统架构Storm核心类Storm trident框架Storm重要参数 Storm介绍和系统架构 1. Twitter将Storm正式开源了,这是一个分布式的、容错的实时计算系统 2. Storm为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时处理消息并更新数据 3. Storm可以方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm用于实时处理。Storm保证每个消息都会得到处理,而且它非常快,在一个小集群中,每秒可以处理数以百万计的消息 4. 开发者可以使用任意编程语言来做开发 主要特点: 1. 简单的编程模型 类似于MapReduce降低了并行批处理复杂性,Storm降低了进行实时处理的复杂性; 2. 容错性 Storm会管理工作进程和节点的故障; 3.水平扩展 计算是在多个线程、进程和服务器之间并行进行的; 4.可靠的消息处理 Storm保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息, 如何判断一条消息是否处理成功或失败,通过异或来判断; 5.快速 系统的设计保证了消息能得到快速的处理,使用ØMQ作为其底层消息队列storm系统架构图 Storm 名词 1.Nimbus 任务的中央调度器(相当于Yarn中 ResourceManager) 2.Supervisor worker的代理, 负责管理Worker的生命周期(相当于Yarn中NodeManager, AppMaster) 3.Stream 被处理的数据 4.Spout 数据源(Map或Reduce) 5.Bolt 处理数据(Map或Reduce) 6.Task 运行于Spout或Bolt中的线程(Container) 7.Executor worker进程中的线程,默认情况下,一个executor对应一个task 8.Worker 运行Task线程的进程(容器) 9.Tuple 流数据 10.Stream Grouping 定义了Bolt接收什么东西作为输入数据 11.Topology Stream Grouping连接起来的Spout和Bolt节点网络 Storm数据流—Tuple 1. Tuple(元组)是Storm最主要的数据结构,一个元组就是一个命名的值列表,其中的每一个值可以是任何类型; 2. Tuple(元组)都是动态类型——字段的类型不需要提前被声明; 3. Tuple(元组)有一些方法像getInteger 和getString之类 得到字段的值的方法,而不需要强制转换结果类型(和JDBC的ResultSet非常类似); Storm 的容错 工作进程worker 失效: 如果一个节点的工作进程worker死掉,supervisor 进程会尝试重启该worker。如果连续重启worker 失败或者worker 不能定期向Nimbus 报告心跳,Nimbus 会分配该任务到集群其他的节点上执行; 集群节点失效: 如果集群中某个节点失效,分配给该节点的所有任务会因超时而失败,Nimbus 会将分配给该节点的所有任务重新分配给集群中的其他节点; Nimbus 或者supervisor 守护进程失败: Nimbus 和supervisor 都被设计成快速失败(遇到未知错误时迅速自我失败)和无状态的(所有的状态信息都保存在Zookeeper 上或者是磁盘上)。Nimbus 和supervisor 守护进程必须在一些监控工具(例如,daemontools 或者monitor)的辅助下运行,一旦Nimbus 或者supervisor 失败,可以立刻重启它们,整个集群就好像什么事情也没发生。最重要的是,没有工作进程worker 会因为Nimbus 或supervisor 的失败而受到影响,Storm 的这个特性和Hadoop 形成了鲜明的对比,在Hadoop中如果JobTracker 失效,所有的任务都会失败; Nimbus 所在的节点失效: 如果Nimbus 守护进程驻留的节点失败,工作节点上的工作进程worker 会继续执行计算任务,如果worker 进程失败,supervisor 进程会在该节点上重启失败的worker 任务。但是,没有Nimbus的影响时,所有worker 任务不会分配到其他的工作节点机器上,即使该worker所在的机器失效; storm异步并发运行模式 在前面提到task、executor、worker、node,这四者的关系如下: 一个node上可以启动多个worker进程 一个work进程上可以执行多个executor线程3.一个executor上可以执行1个或多个task, 即bolt或spout实例,默认情况下一个executor对应一个task 这就是Storm并发运行的模式,可以在创建topology的时候设置node, work 、executor和task的并发度模型, 下面拿单词统计程序来详细说明。 默认并发度 运行的并发模型如下: 调整并发度 Tuple消息分组路由机制 Storm定义了7种内置数据流分组方式,分别是: 1. Shuffle Grouping(随机分组): 随机分发tuple给bolt的各个task,每个bolt接收到相同数量的tuple,代码中是用shuffleGrouping这个方法; 2. Fields Grouping(按字段分组): 根据给定的字段进行分组。比如说一个数据流根据word字段进行分组,所有具有相同的word字段值的tuple会路由到同一个bolt中(用得最多),代码中是用fieldsGrouping这个方法; 3. All Grouping(广播发送): 将所有tuples复制后分发给所有bolt task,这样每个订阅数据流的task都会收到tuple的一个copy,代码中是用allGrouping这个方法; 4. Global Grouping(全局分组): 将所有tuples路由到唯一的一个task上,Storm按照最小的task ID来选取接收数据的task,代码中是用globalGrouping这个方法; 5. Non Grouping(不分组): Shuffle Grouping 是一样的效果,有一点不同的是Storm 会把这个Bolt 放到此Bolt 的订阅者同一个线程里面去执行,代码中是用noneGrouping这个方法; 6. Direct Grouping(指向型分组): 这种分组意味着消息的发送者指定由消息接收者的哪个Task 处理这个消息。只有被声明为Direct Stream 的消息流可以声明这种分组方法。而且这种消息tuple 必须使用emitDirect 方法来发送,代码中是用directGrouping这个方法; 7.Local or shuffle grouping(本地或随机分组): 和随机分组类似,但是会将tuple分发给同一个worker内的bolt task。其它情况下,采用随机分组的方式,这取决于topology的并发度,本地或随机分组可以减少网络人传输,从而且提高topology的性能,代码中是用localOrShuffleGrouping这个方法; 自定义分组路由 可以通过实现CustomStreamGrouping的接口来自定义分组方式:prepare()会在运行时间调用, 用来初始化分组信息,分组的个体实现会在这些信息决定如何向接收task分发tuple.chooseTasks()方法返回一个tuple发送目标的task的标识符列表,它的两个参数是发送tuple的组件的id和tuple的值. Storm核心类 1.BaseRichSpout 重写nextTuple、declareOutputFields、 open、ack、 fail方法open : 一般是初始化SpoutOutputCollector对象nextTuple : 从数据源接受数据,并向下游的bolt发射数据流declareOutputFields : 声明发射数据的输出字段ack : 成功的处理fail : 失败的处理 2.BaseRichBolt 重写execute 、declareOutputFields、 prepare、 cleanup方法prepare:一般是初始化SpoutOutputCollector对象declareOutputFields :声明发射数据的输出字段execute : 处理数据,并向下游发送tuplecleanup : 清除工作 3.TopologyBuilder 通过setSpout、setBolt构建topology Storm trident框架 Storm Trident的数据模型 Storm Trident的核心数据模型是小批量去处理流数据(相当于Spark Stream组件),流分区在集群的节点上,对流的操作也是并行的在每个分区上进行; 官方的描述是: Trident is an alternative interface to Storm. Tuples are processed as small batches(小批量). It provides exactly-once processing (刚好一次的处理), “transactional" datastore persistence(事物的持久化), and a set of common stream analytics operations.)。Trident对事物处理方案如下: 1. 一批数据被分配指定一个唯的id 称作为“transaction id”. 如果一批数据被重复处理,将会得到是同 一个transaction id(唯一、幂等); 2. 在各批数据之中,状态更新是保序的,例如:批次3的状态更新不会在批次2状态更新成功之前(保序); Storm trident数据流 Trident数据流是分批次的,如下图所示,而普通bolt或spout数据流是一个接一个连续的, trident数据每一批的大小,取决输入数据量的大小 Trident API Trident有五种对流的操作的API: 1.不需要网络传输的本地批次运算,每个分区(partion)的运算是互相独立的 Functions Filters partitionAggregate stateQuery and partitionPersist projection 2.需要网络传输的重分布操作,不改变数据的内容; shuffle broadcast partitionBy global batchGlobal partition 3. 聚合操作,网络传输是该操作的一部分 aggregate 4. 流分组(groupby)操作 groupby 5. 合并和关联操作 merge join 一个Trident topology完整的示例 示例中包含:filterfunctiongroupbypersistentAggregate filter function projection 投影操作是对数据上进行列裁剪用法:如果你有一个流有【“a”,“b”,“c”,“d”】四个字段,执行下面的代码:mystream.project(new Fields("b","d"))输出流将只有【“b”,“d”】两个字段 Repartition(重分区) 重分区操作是通过一个函数改变元组(tuple)在task之间的分布。也可以调整分区数量(比如,如果并发的hint在repartition之后变大)重分区(repatition)需要网络传输,以下是重分区函数: 1. shuffle: 使用随机算法在目标分区中选一个分区发送数据;用法: inputStream.shuffle(); 2. broadcast: 每个元组重复的发送到所有的目标分区。这个在DRPC中很有用。如果你想做在每个分区上做一个statequery;用法: inputStream.broadcast(); 3.paritionBy: 根据一系列分发字段(fields)做一个语义的分区。通过对这些字段取hash值并对目标分区数取模获取目标分区。paritionBy保证相同的分发字段(fields)分发到相同的目标分区;用法: inputStream.partitionBy(new Fields("event", "city")); 4.global: 所有的tuple分发到相同的分区。这个分区所有的批次相同;用法: inputStream.global(); 5.batchGobal: 本批次的所有tuple发送到相同的分区,不通批次可以在不通的分区;用法: inputStream.batchGlobal(); 6.patition: 这个函数接受用户自定义的分区函数,很少用。用户自定义函数事项 backtype.storm.grouping.CustomStreamGrouping接口; 用法: inputStream.partition(grouping); Aggregation(聚合) 1. Trident有aggregate和persistentAggregate函数对流做聚合, aggregate在每个批次上独立运行;persistentAggregate聚合流的所有的批次并将结果存储下来,然后现在一个流上做全局的聚合 2. 如果使用reducerAggregator或者aggretator,这个流先被分成一个分区,然后聚合函数在这个分区上运行。 3. 如果使用CombinerAggreator,Trident会在每个分区上做一个局部的汇总,然后重分区聚合到一个分区,在网络传输结束后完成聚合。CombinerAggreator非常有效,在尽可能的情况下多使用.下面是一个做批次内聚合的例子:mystream.aggregate(new Count(), new Fields("count"))和partitionAggregate一样,聚合的aggregate也可以串联。如果将CombinerAggreator和非CombinerAggreator串联,trident就不能做局部汇总的优化。 Trident流分组操作 1. groupBy操作根据特殊的字段对流进行重分区,分组字段相同的元组(tuple)被分到同一个分区,如果对分组的流进行聚合,聚合会对每个组聚合而不是这个批次聚合。(和关系型数据库的groupby相同). 2 persistentAggregate也可以在分组的流上运行,这种情况下结果将会存储在MapState里面,key是分组字段,和普通聚合一样,分组流的聚合也可以串联。 Trident—merge和join 合并: 将不同的流合并,最简单的方式就是合并(meger)多个流成为一个流, 用法如下:topology.merge(stream1, stream2, stream3);Trident合并的流字段会以第一个流的字段命名 关联: 类似SQL的join都是对固定输入的。而流的输入是不固定的,所以不能按照sql的方法做join。Trident中的join只会在spout发出的每个批次见进行,下面是个join的例子: 一个流包含字段【“key”,“val1” ,“val2”】,另一个流包含字段【“x”,“val1”】:topology.join(stream1, new Fields("key"), stream2, new Fields("x"), new Fields("key","a","b","c"));Stream1的“key”和stream2的“x”关联。Trident要求所有的字段要被名字,因为原来的名字将会会覆盖。Join的输入会包含:1.首先是join字段。例子中stream1中的“key”对应stream2中的“x”。2.接下来,会吧非join字段依次列出来,排列顺序按照传给join的顺序。例子中” a”,” b”对应stream1中 的“val1”和“val2”,“c”对应stream2中的“val1”。 注意:当join的流分别来自不同的spout,这些spout会同步发射的批次,也就是说,批次处理会包含每 个spout发射的tuple。 partitionAggregate 有三种不同的聚合接口:CombinerAggreator,ReduceAggregator和Aggregator Aggregator(聚合器) CombinerAggregator CombinerAggregator用来将一个集合的tuple组合到一个单独的字段中,Storm 对每一个tuple调用init方法,然后重复调用combine()方法直到一个分片的数据处理完成为止。传递给combine方法的两个参数是局部聚合的结果,以及调用了init()返回的值。Storm将tuple生成的值进行组合之后,Storm发送组合结果作为一个新的字段,如果分片是空的,Storm会发送zero()方法执行的返回。 ReducerAggregator Storm调用init()方法来获取原始值。然后为分片中每一个tuple调用reduce()方法,直到分片的数据处理完成。第一个参数是局部聚合的结果,这个方法需要将第二个参数tuple合并到局部聚合结果中并返回。 Aggregator Aggregators能发射任何类型和任何字段的tuple, 在执行期间,他能发射任何tuple,执行的方式如下:在处理一批数据之前,就调用init(), init()方法的返回值对象代表aggregation的state, 并且会传递到aggregate和complete方法中去;针对一批数据中的每一个tuple,都会调用aggregator方法,这个方法能够更新state和选择性的发射tuple流;当一批数据处理完成的时候,就会调用complete方法; 编程中三种聚合器的选择 共同点:都可以实现一些简单、复杂的计数、统计功能、在partitionAggregate操作方法上性能、功能都差不多; 区别: CombinerAggregator: 比较灵活,每一个tuple的初始值都可以根据实际情况灵活设置,适合流的 aggregate操作,此时trident会有自动优化机制(在网络传输之前就会做局转换合并) ReducerAggregator: 最容易使用, 初始值可以根据实际情况灵活设置,适合比较简单处理的场景 Aggregator: 最灵活, 批次的初始值可以灵活设置, 常用在多次统计处理,一次发射的场景 要求:学会用三种Aggregator实现各自的计数功能, Trident State Trident State有如下三个组件: StateFactory : 该接口定义了Trident用来建立持久state对象的方法; State : 该接口定义了beginCommit()和commit()方法,分别在Trident一批分区数据写到后端存储之前和之后调用。如果写入成功,意味着,所有的处理都没有报错,Trident会调用commit()方法; StateUpdater : 该接口定义了updateState()方法用来调用更新state,假定处理了一批tuple,Trident将三个参数传递给这个方法,需要更新的State对象,一个批次分区数据中TridentTuple对象的列表和TridentCollector实例用来视需要发送额外的tuple作为state更新的结果; Trident State事物 在Storm中,有三种类型的状态,每个类型的描述如下:在写Storm脚本的时候,这三种事物对应的MapState接口的实现,分别是: 重复事物型:TransactionalMap 不透明事物型:OpaqueMap 非事物型:NonTransactionalMap重复事物和不透明事物详细看附件 Trident事物和幂等性 StateUpdater 从数据流中的tuple更新状态(state)信息, updateState()调用的时机是在state对象的beginCommit()和commit()方法调用之间进行,接口定义如下: 使用的场景:主要是在Stream类的partitionPersist的各种方法中,主要的作用是允许topology从数据流中的tuple更新状态(state)信息,部分重载方法如下: StateQuery stateQuery方法从State实现类对象生成一个输入数据流, 操作示例如下: TridentTopology topology = new TridentTopology(); topology.newDRPCStream("words") .each(new Fields("args"), new Split(), new Fields("word")) .groupBy(new Fields("word")) .stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count")) .each(new Fields("count"), new FilterNull()) ; StateQueryProcessor核心源码如下:由上面的代码可以看出,在流在执行stateQuery方法的时候,针对每一批数据中的每一个tuple,都会执行QueryFunction实现类的execute方法 persistentAggregate persistentAggregate: 持久化聚合的的操作过程,它是GroupedStream类的 一个方法,它一般是用来在Stream对象通过groupby分组聚合操作之后生成的GroupedStream方法之后,在每个分片数据的每个分组上运行这方法,方法的各个参数,以及返回值如下: 1. 方法第一个参数传入的StateFactory对象生成的State对象,结合前面介绍的State三种事物中某一种事物来进行持久化操作操作处理,一般持久化操作需要实现IBackingMap这个接口,比例持久化到本地文件、Memcache、redis、HBase、LevelDB、HDFS、mysql等,通常在开发环境 下为了方便写入到一个Map中即可; 2. 方法的第二参数一般是一个Aggregator对象,在分片上执持persistentAggregate的时候,会去执行这个Aggregator对象的初始化方法、多次迭代方法、完成方法,比例ReducerAggregator对象,在这个分片上先执行ReducerAggregator的init方法,然后针对每一个tuple,执行ReducerAggregator的 reduce方法,直到完成; 3. 第三参数是由第二个参数聚合操作指定产生的新字段, 如Count聚合,一般会设置成count字段; 4. 返回值的类型是一个TridentState对象,一般情况下返回的TridentState对象会再生成一个新的Stream对象,继续往下游处理; partitionPersist partitionPersist : 是在一个在分区上进行持久化的操作方法,不需要网络通信, 它是Stream类的一个方法,在每个分片数据的每个分组上运行这方法,方法的各个参数,以及返回值如下: 1. 第一个参数是一个StateFactory类型,和persistentAggregate的第一个参数一样,功能也一样; 2. 第二个参数是输入的字段集合; 3. 第三个参数是一个StateUpdater实例, storm在一个数据分片上调用这个方法时,会在state对象的beginCommit和commit这两个方法之间会调用这个StateUpdater实例的updateState去更新状态 ,数据批次的状态是方法的第一个参数,该批次数据的集合是第二个参数, 第三个参数是一个TridentController控制器对象,方法调用的部分核心源码如下: 4. 第四个参数是一个方法操作的字段; Storm重要参数 worker.childopts: 默认情况下,Storm启动worker进程时,JVM的最大内存是768M,但是在线上环境中,由于会在Bolt中加载大量数据,768M内存无法满足需求,会导致内存溢出程序崩溃,可以通过在Strom的配置文件storm.yaml中设置worker的启动参数, 例如可以这样设置:"-Xmn1024m -Xms2048m -Xmx2048m -XX:+UseConcMarkSweepGC -XX:+UseCMSInitiatingOccupancyOnly" Supervisor.slots.ports: Storm的Slot,最好设置成OS核数的整数倍;同时由于Storm是基于内存的实时计算,Slot数不要大于每台物理机可运行Slot个数; storm.messaging.netty.buffer_size: 传输的buffer大小,默认1MB,当Spout发射的消息较大时,此处需要对应调整###storm.messaging.netty.max_retries:建议设置为3 storm.messaging.netty.max_wait_ms: 建议设置为10000; storm.messaging.netty.min_wait_ms: 建议设置为3000; Topology.acker.executors: 由于Acker基本消耗的资源较小,强烈建议将此参数设置在较低的水平, 建议设置为1; Topology.max.spout.pending: 一个SpoutTask中处于pending状态的最大的Tuple数量。该配置应用于单个Task,而不是整个Spout或Topology,可在Topology中进行覆盖, 通常情况下,建议设置为1024; Storm应用 1. 日志分析 2. 消息转化器 3. 实时统计分析 1. 阿里双11交易大屏 2. 腾讯网2015年 9.3阅兵在线人数实时统计(lamba架构) 3. 搜索引擎中热点词频 4.人工智能 5. NLP(语音合成处理,高德导航上林志玲的导航语言提示) 6. 股票实事趋势分析 7. 互联网风控 8. 广告推荐 推荐资料 Storm 官方文档 : http://storm.apache.org/ Storm分布式实时计算模式 Storm源码分析 问题 Storm是如何确定一条消息是否处理成功?原值和返回值进行异或计算,如下: