Python学习笔记
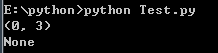
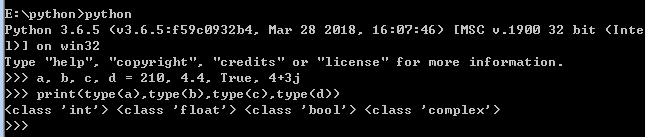
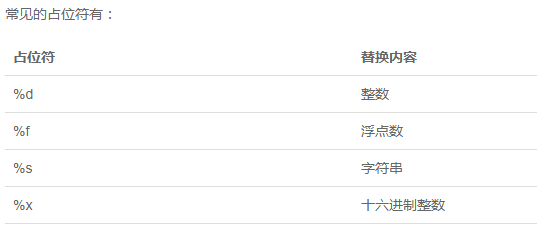
一:中文编码 1:指定编码 python-------》#!/usr/bin/python shell----------》#!/bin/bash 2:中文识别 # -*- coding: UTF-8 -*- 或 #coding=utf-8 3:多行语句 我们使用斜杠(/)将一行语句分成多行 如果是{},(),[]则直接可以进行换行 4.转义 \n表示换行、\t表示制表符、\\表示\、 如果有很多需要转义,则可使用r' ' ''' '''也可以表示换行 print('''line1 line2 line3''') 5:输出 print x,y print默认是换行的,如果再print末尾加个逗号“,”就回不换行 6.输入 shell:read -p "Please enter your age: " age python2:a = raw_input("请输入你的名字") python3:a = input("请输入你的名字") 二:变量和简单类型 python中数据类型分为5种:数字,字符串、列表、元组、字典 变量命名规则: python shell 文件名/模块名 小写,单词用“_”分割 ----->ad_stats.py 包名 小写,单词用“_”分割 类名 单词首字母大写----->ConfigUtil 全局变量名 大写字母,单词之间用_分割 ------->COLOR_WRITE 普通变量 小写字母,单词之间用_分割 ------->this_is_a_var 实例变量 以_开头,其他和普通变量一样 ----->_instance_var 普通函数 和普通变量一样-------------------->get_name() 2.1数字 整数:a=1 浮点数:a=1.234 2.2字符串 创:var1 = 'Hello World!' 查:print "var1[0]: ", var1[0] print "var2[1:5]: ", var2[1:5] 改:print "更新字符串 :- ", var1[:6] + 'Runoob!' rd()函数获取字符的整数表示,chr()函数把编码转换为对应的字符 占位符 'Hi, %s, you have $%d.' % ('Michael', 1000000) 如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串 另外一种格式化字符串的方法是format(),他会将传入的参数依次替换{1},{2},{3}......,... 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125) 2.3布尔值 布尔值只有True、False两种值 2.4空值 2.5常量 10/3=3.3333 9/3=3.0 10//3=3 10%3=1 2.6除法 余数: >>> divmod(10,3) (3, 1) 四舍五入: >>> round(10/3,4) 3.0 >>> round(10.0/3,4) 3.3333 2.7数学函数与运算优先级 1.绝对值 abs(-10)=10 2.四舍五入 round(1.234)=1 三:高级特性 1.切片 L[0:3]表示,从索引0开始取,直到索引3为止,但不包括索引3。即索引0,1,2,正好是3个元素 如果第一个索引是0,还可以省略-------》L[:3] 前10个数,每两个取一个----------》L[:10:2] 所有数,每5个取一个--------------》L[::5] 什么都不写,只写[:]就可以原样复制一个list-----------》L[:] 2.迭代 3.列表生成器 [x * x for x in range(1, 11)]--------》[1, 4, 9, 16, 25, 36, 49, 64, 81, 100] 四:列表(List) list是一种有序的集合,可以随时添加和删除其中的元素。 list1 = ['Michael', 'Bob', 'Tracy'] 增:list1.append('adm')、 list1.insert(1,'jack') #插入元素到指定的位置 删:list1.pop(1) #不填则删除末尾元素 del list1[2] 查:list1[-1] 改:list1[1] ='Sarah',dellist1[2]; 附加:s = ['python','java', ['asp','php'],'scheme'],s[2][1] 五:元组 Python的元组与列表类似,不同之处在于元组的元素不能修改。 tup1 = ('physics', 'chemistry', 1997, 2000); 查:tup1[2] 较:cmp(tuple1, tuple2) 长:len(tup1) 六:字典 字典是另一种可变容器模型,且可存储任意类型对象。 d = {key1 : value1, key2 : value2 } 增: 删:del d['key1']; # 删除键是'key1'的条目 d.pop(key1) #删除对应的键值对 d.clear(); # 清空词典所有条目 del d; # 删除词典 查:d['key1'] d.get(key1)---------->value1 d..has_key(key1)-------->返回true或者false d.keys()-------------->返回所以键['key2','key1'] dict.values()---------->返回所以值[value1,value2] 改:d['key1']=value3 d.update(dict2)----------->将dict2添加到d后面 判:d.has_key(key1)---------->存在则返回true,否则为false 较:cmp(dict1, dict2) 长:len(dict) 七:运算符 python中运算符分为7种:1.算术运算符 2.比较(关系)运算符 3.赋值运算符 4.逻辑运算符 5.位运算符 6.成员运算符 7.身份运算符 1.算术运算符:+、-、*、%(求余)、**(次幂a**b)、//(取整) 2.比较运算符:==(比较是否相等)、!=、<>(比较两个数是否不相等)、>=、<= 3.赋值运算符:=、+=、-=、*=、/=(除法赋值运算符)、%=(取模赋值运算符)、**=(幂赋值运算符)、//=(取整运算符) 4.位运算符:&、|、^、 5.and(与)、or(或)、not 6.in(在)、not in(不在) 7.is(是)、is not(不是) 优先级 八:语句 python分为7种:条件语句,循环语句(while循环,for循环),break语句,continue循环语句,pass循环 python循环语句不用括号()括起来 1:条件语句 num = 5 if num == 3: # 判断num的值 print 'boss' elif num == 2:print 'user' elif num == 1:print 'worker' elif num < 0: # 值小于零时输出 print 'error' else:print 'roadman' # 条件均不成立时输出 2:循环语句 while...else循环 count = 0 while count < 5: print count, " is less than 5" count = count + 1 else: print count, " is not less than 5" for循环 for num in range(10,20): # 迭代 10 到 20 之间的数字 for i in range(2,num): # 根据因子迭代 if num%i == 0: # 确定第一个因子 j=num/i # 计算第二个因子 print '%d 等于 %d * %d' % (num,i,j) break # 跳出当前循环 else: # 循环的 else 部分 print num, '是一个质数' 九:函数 9.1函数规则 1:函数代码块以def关键字开头,后接函数标识符名称和圆括号() 2:任何传入参数和变量必须放在圆括号中间,圆括号中可以用于定义参数 3:函数第一行语句可以放文档字符串,用于存放函数说明 4:函数内容以冒号起始,并且缩进 #python函数 def printinfo( name, age ): "打印任何传入的字符串" print "Name: ", name; print "Age ", age; return; #调用printinfo函数 printinfo( age=50, name="miki" ); #shell函数 function RintedConfig(){ } 9.2函数参数 1.必备参数、2.关键字参数、3.默认参数、4.不定长参数 1:必备参数 必备参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。 2:关键字参数 使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。 def printinfo( name, age ): printinfo( age=50, name="miki" ); 3:缺省参数 调用函数时,缺省参数的值如果没有传入,则被认为是默认值。 def printinfo( name, age = 35 ): printinfo( name="miki" ); 4:不定长参数 你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数, def functionname([formal_args,] *var_args_tuple ): 加了星号(*)的变量名会存放所有未命名的变量参数 9.3高阶函数 1.map() map()可接受两个参数,一个是函数,一个是Iterable,map将传入的参数作用到序的每个元素,并把结果作为新的Iterable返回。 def f(x): return x*x map(f, [1,2,3,4]) >>[1,4,9,16] 2.return() return接收一个函数和两个参数,reduce把结果继续和序列的下一个元素做累积计算。 def f(x,y): return x+y >>map(f, [1,2,3,4]) >>25 3.filter() 用于过滤序列,filter()将元素作用于每个人元素,并根据返回值是true或者false来决定元素的去留。 def is_odd(n): return n % 2==1 filter(is_odd, [1,2,3,4,5,6]) 4.sorted() sorted()可将元素进行排序, def reversed_cmp(x, y): if x > y: return -1 if x < y: return 1 return 0 >>> sorted([36, 5, 12, 9, 21], reversed_cmp) [36, 21, 12, 9, 5] 9.4返回函数 高阶函数除了可以将函数作为参数,也可以将函数作为结果返回。 def lazy_sum(*args): def sum(): ax = 0 for n in args: ax = ax + n return ax return sum 9.5匿名函数 关键字lambda表示匿名函数, 匿名函数有个限制,就是只能使用一个表达式,返回值就是该表达式的结果。 map(lambda x: x*x, [1,2,3,4,5,6]) 使用匿名函数就不用担心名字冲突,同是匿名函数也是一个对象,可以将匿名函数作为参数。 ff = lambda x: x*x print ff(5) 9.6装饰器 有时候为了增强函数的功能,但又不改变函数的定义,这种在代码运行期间动态的增加函数的功能的方法叫装饰器。 def log(text): def decorator(func): def wrapper(*args, **kw): print('%s %s():' % (text, func.__name__)) return func(*args, **kw) return wrapper return decorator @log('execute') def now(): print('2015-3-25') >>> now() execute now(): 2015-3-25 9.7偏函数 十:模块 10.1作用域 有的函数和变量,我们仅仅希望在模块内使用,python中我们通过_前缀来实现。 正常的函数和变量都是被公开的,_xxx和__xxx这样的函数或变量就是非公开的(private),不应该被直接引用。 带下划线的函数,说明该函数不能根据 from * import来导入,明显在这个模块中你导入的还只是包,然后通过了这个导入的包去调用他内部存在的函数。 十一:面向对象编程 11.1类和实例 class Student (Object): class后面接的是类名,类名手写字母必须大写,紧接的是object,表示该类所继承的类,如果没有,则继承自object类。 class Student(object): def __init__(self, name, score): self.name = name self.score = score def print_score(self): print '%s: %s' % (self.name, self.score) 11.2访问限制 如果要让内部属性,不被外部访问,可以将属性的名称前面加两个下划线,python中变量以__开头的则为私有变量(private),只有内部可以访问,外部不能被访问。 外部要获取和改变,只能通过get和set方法来进行。 class Student(object): def __init__(self, name, score): self.__name = name self.__score = score def print_score(self): print '%s: %s' % (self.__name, self.__score) #外部直接获取 >>> bart = Student('Bart Simpson', 98) >>> bart.__name Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Student' object has no attribute '__name'#必须使用getname和setname方法 class Student(object): ... def get_name(self): return self.__name def get_score(self): return self.__score 11.3基础多态 继承可以把父类的所有功能都直接拿过来,这样就不必重零做起,子类只需要新增自己特有的方法,也可以把父类不适合的方法覆盖重写; 有了继承,才能有多态。在调用类实例方法的时候,尽量把变量视作父类类型,这样,所有子类类型都可以正常被接收; 11.4获取对象信息 1.type() type可以判断一个变量、函数,类的类型。 2.isinstance() isinstance()判断的是一个对象是否是该类型本身,或者位于该类型的父继承链上。 3.dir() 如果要获得一个对象的所有属性和方法,可以使用dir()函数,它返回一个包含字符串的list。 11.5__slots__ 如果想对向前类进行限制只添加某几个属性,可以使用__slots__来进行限制。 __slots__只对当前类起作用,对继承的类不起作用。 class Student(object): __slots__=('name','age') s = Student() s.name = 'yaohong' s.age = 90 s.socre = 99 》》 s.socre = 99 AttributeError: 'Student' object has no attribute 'socre' 11.6@property Python内置的@property装饰器就是负责把一个方法变成属性调用的。 class Student(object): @property def birth(self): return self._birth @birth.setter def birth(self, value): self._birth = value @property def age(self): return 2014 - self._birth 11.7多继承 一个子类同时获得多个父类的所有功能。 由于Python允许使用多重继承,因此,Mixin就是一种常见的设计。 只允许单一继承的语言(如Java)不能使用Mixin的设计。 11.8定制类 __str__ class Student(object): def __init__(self, name): self.name = name def __str__(self): return self.name def __repr__(self): return self.name print Student('YAOHONG') print Student('YAOHONG') 11.9使用元类 十二:文件I/O 10.1打印到屏幕 print “”itnihao” 10.2读取输入 1.raw_input str = raw_input("请输入:"); print "你输入的内容是: ", str 2.input input可以接收一个函数表达式 str = input("请输入:"); print "你输入的内容是: ", str 3.open() file object = open(file_name [, access_mode][, buffering]) file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。 access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。 buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。 4.close() close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。 5.write() write()方法可将任何字符串写入一个打开的文件 6.read() fo = open("foo.txt", "r+") str = fo.read(10); print "读取的字符串是 : ", str # 关闭打开的文件 fo.close() 7.rename() os.rename( "test1.txt", "test2.txt" ) 8.remove() os.remove("test2.txt") 8.mkdri() os.mkdir("test")在当前目录下创建新的test文件 9.chdir() os.chdir("/home/newdir")改变当前目录为/home/newdir目录 10.getcwd() os.getcwd()获取当前目录 11.rmdir() # 删除”/tmp/test”目录 os.rmdir( "/tmp/test" ) 十三:异常处理 1.捕获异常:try/except try: fh = open("testfile", "w") fh.write("这是一个测试文件,用于测试异常!!") except IOError: print "Error: 没有找到文件或读取文件失败" else: print "内容写入文件成功" fh.close() 2.try/finally try-finally 语句无论是否发生异常都将执行最后的代码。 3.触发异常 使用raise语句自己触发异常 def functionName( level ): if level < 1: raise Exception("Invalid level!", level) # 触发异常后,后面的代码就不会再执行 十四:file file使用open函数来创建 常用函数: file.close() file.flush() file.next() 返回下一行 file.read(size) 从文件读取指定的字节数,如果未给定或为负则读取所有。 file.readline(size) 读取整行 file.seek() 设置文件当前位置 file.tell() 返回文件当前位置 file.truncate() 截取文件,截取文件通过size指定 file.write() 将指定字符串写入文件 file.writelines() 向文件写入一个字符串列表 十五:OS os.access() 检测文件是否可读可写,文件是否存在,是否拥有执行权限 os.chdir(path) 切换到新的目录 os.chmod() 更改文件或者目录权限 os.chown() 更改文件所有者 os.close() 关闭文件 os.path.join('a','b')字符串拼接形成a/b os.system("ls") 执行shell命令,如assert os.system("rm -rf %s" % install_path) == 0, "卸载 失败" os.path.exists(BIN_PATH) 判断某个变量是否存在 os.unlink(path) 方法用于删除文件,如果文件是一个目录则返回一个错误。 os.remove() 删除文件 十六:open open(a.txt).read() 去取a.txt文件 十七:enumerate enumerate(list1) 枚举list,map等获取索引和元素for index, item in enumerate(list1): 十八:string str.strip("@") 去掉以@开头结尾的 str.startswith("#") 判断是否以#开头 十九:Python常见模块 python常见命令如下,点击链接查看详情 1.os 2.os.path 3.shutil 4.sys 5.inspect