Android面试,View绘制流程以及invalidate()等相关方法分析
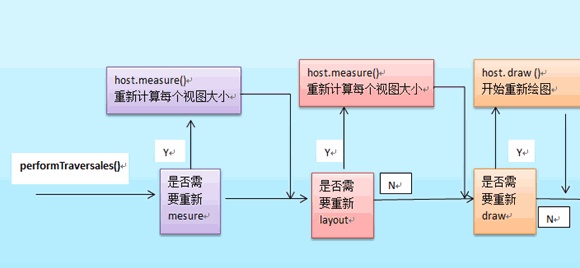
整个View树的绘图流程是在ViewRoot.java类的performTraversals()函数展开的,该函数做的执行过程可简单概况为 根据之前设置的状态,判断是否需要重新计算视图大小(measure)、是否重新需要安置视图的位置(layout)、以及是否需要重绘 (draw),其框架过程如下: measure()过程 主要作用:为整个View树计算实际的大小,即设置实际的高(对应属性:mMeasuredHeight)和宽(对应属性:mMeasureWidth),每个View的控件的实际宽高都是由父视图和本身视图决定的。 具体的调用链如下: ViewRoot根对象地属性mView(其类型一般为ViewGroup类型)调用measure()方法去计算View树的大小,回调View/ViewGroup对象的onMeasure()方法,该方法实现的功能如下: 1、设置本View视图的最终大小,该功能的实现通过调用setMeasuredDimension()方法去设置实际的高(对应属性:mMeasuredHeight)和宽(对应属性:mMeasureWidth) ; 2 、如果该View对象是个ViewGroup类型,需要重写该onMeasure()方法,对其子视图进行遍历的measure()过程。 2.1 对每个子视图的measure()过程,是通过调用父类ViewGroup.java类里的measureChildWithMargins()方法去实现,该方法内部只是简单地调用了View对象的measure()方法。(由于measureChildWithMargins()方法只是一个过渡层更简单的做法是直接调用View对象的measure()方法)。 整个measure调用流程就是个树形的递归过程 measure函数原型为 View.java 该函数不能被重载 public final void measure(int widthMeasureSpec, int heightMeasureSpec) { //.... //回调onMeasure()方法 onMeasure(widthMeasureSpec, heightMeasureSpec); //more } 为了大家更好的理解,采用“二B程序员”的方式利用伪代码描述该measure流程 //回调View视图里的onMeasure过程 private void onMeasure(int height , int width){ //设置该view的实际宽(mMeasuredWidth)高(mMeasuredHeight) //1、该方法必须在onMeasure调用,否者报异常。 setMeasuredDimension(h , l) ; //2、如果该View是ViewGroup类型,则对它的每个子View进行measure()过程 int childCount = getChildCount() ; for(int i=0 ;i<childCount ;i++){ //2.1、获得每个子View对象引用 View child = getChildAt(i) ; //整个measure()过程就是个递归过程 //该方法只是一个过滤器,最后会调用measure()过程 ;或者 measureChild(child , h, i)方法都 measureChildWithMargins(child , h, i) ; //其实,对于我们自己写的应用来说,最好的办法是去掉框架里的该方法,直接调用view.measure(),如下: //child.measure(h, l) } } //该方法具体实现在ViewGroup.java里 。 protected void measureChildWithMargins(View v, int height , int width){ v.measure(h,l) } layout布局过程 主要作用 :为将整个根据子视图的大小以及布局参数将View树放到合适的位置上 具体的调用链如下: host.layout()开始View树的布局,继而回调给View/ViewGroup类中的layout()方法。具体流程如下 1 、layout方法会设置该View视图位于父视图的坐标轴,即mLeft,mTop,mLeft,mBottom(调用setFrame()函数去实现)接下来回调onLayout()方法(如果该View是ViewGroup对象,需要实现该方法,对每个子视图进行布局) ; 2、如果该View是个ViewGroup类型,需要遍历每个子视图chiildView,调用该子视图的layout()方法去设置它的坐标值。 layout函数原型为 ,位于View.java /* final 标识符 , 不能被重载 , 参数为每个视图位于父视图的坐标轴 * @param l Left position, relative to parent * @param t Top position, relative to parent * @param r Right position, relative to parent * @param b Bottom position, relative to parent */ public final void layout(int l, int t, int r, int b) { boolean changed = setFrame(l, t, r, b); //设置每个视图位于父视图的坐标轴 if (changed || (mPrivateFlags & LAYOUT_REQUIRED) == LAYOUT_REQUIRED) { if (ViewDebug.TRACE_HIERARCHY) { ViewDebug.trace(this, ViewDebug.HierarchyTraceType.ON_LAYOUT); } onLayout(changed, l, t, r, b);//回调onLayout函数 ,设置每个子视图的布局 mPrivateFlags &= ~LAYOUT_REQUIRED; } mPrivateFlags &= ~FORCE_LAYOUT; } 同样地, 将上面layout调用流程,用伪代码描述如下: // layout()过程 ViewRoot.java // 发起layout()的"发号者"在ViewRoot.java里的performTraversals()方法, mView.layout() private void performTraversals(){ //... View mView ; mView.layout(left,top,right,bottom) ; //.... } //回调View视图里的onLayout过程 ,该方法只由ViewGroup类型实现 private void onLayout(int left , int top , right , bottom){ //如果该View不是ViewGroup类型 //调用setFrame()方法设置该控件的在父视图上的坐标轴 setFrame(l ,t , r ,b) ; //-------------------------- //如果该View是ViewGroup类型,则对它的每个子View进行layout()过程 int childCount = getChildCount() ; for(int i=0 ;i<childCount ;i++){ //2.1、获得每个子View对象引用 View child = getChildAt(i) ; //整个layout()过程就是个递归过程 child.layout(l, t, r, b) ; } } draw()绘图过程 由ViewRoot对象的performTraversals()方法调用draw()方法发起绘制该View树,值得注意的是每次发起绘图时,并不会重新绘制每个View树的视图,而只会重新绘制那些“需要重绘”的视图,View类内部变量包含了一个标志位DRAWN,当该视图需要重绘时,就会为该View添加该标志位。 调用流程 : mView.draw()开始绘制,draw()方法实现的功能如下: 1 、绘制该View的背景 2 、为显示渐变框做一些准备操作(大多数情况下,不需要改渐变框) 3、调用onDraw()方法绘制视图本身 (每个View都需要重载该方法,ViewGroup不需要实现该方法) 4、调用dispatchDraw ()方法绘制子视图(如果该View类型不为ViewGroup,即不包含子视图,不需要重载该方法)值得说明的是,ViewGroup类已经为我们重写了dispatchDraw ()的功能实现,应用程序一般不需要重写该方法,但可以重载父类函数实现具体的功能。 4.1 dispatchDraw()方法内部会遍历每个子视图,调用drawChild()去重新回调每个子视图的draw()方法(注意,这个 地方“需要重绘”的视图才会调用draw()方法)。值得说明的是,ViewGroup类已经为我们重写了dispatchDraw()的功能实现,应用程序一般不需要重写该方法,但可以重载父类函数实现具体的功能。 绘制滚动条 伪代码: // draw()过程 ViewRoot.java // 发起draw()的"发号者"在ViewRoot.java里的performTraversals()方法, 该方法会继续调用draw()方法开始绘图 private void draw(){ //... View mView ; mView.draw(canvas) ; //.... } //回调View视图里的onLayout过程 ,该方法只由ViewGroup类型实现 private void draw(Canvas canvas){ //该方法会做如下事情 //1 、绘制该View的背景 //2、为绘制渐变框做一些准备操作 //3、调用onDraw()方法绘制视图本身 //4、调用dispatchDraw()方法绘制每个子视图,dispatchDraw()已经在Android框架中实现了,在ViewGroup方法中。 // 应用程序程序一般不需要重写该方法,但可以捕获该方法的发生,做一些特别的事情。 //5、绘制渐变框 } //ViewGroup.java中的dispatchDraw()方法,应用程序一般不需要重写该方法 @Override protected void dispatchDraw(Canvas canvas) { // //其实现方法类似如下: int childCount = getChildCount() ; for(int i=0 ;i<childCount ;i++){ View child = getChildAt(i) ; //调用drawChild完成 drawChild(child,canvas) ; } } //ViewGroup.java中的dispatchDraw()方法,应用程序一般不需要重写该方法 protected void drawChild(View child,Canvas canvas) { // .... //简单的回调View对象的draw()方法,递归就这么产生了。 child.draw(canvas) ; //......... } invalidate()方法 说明:请求重绘View树,即draw()过程,假如视图发生大小没有变化就不会调用layout()过程,并且只绘制那些“需要重绘的”视图,即谁(View的话,只绘制该View ;ViewGroup,则绘制整个ViewGroup)请求invalidate()方法,就绘制该视图。 一般引起invalidate()操作的函数如下: 1、直接调用invalidate()方法,请求重新draw(),但只会绘制调用者本身。 2、setSelection()方法 :请求重新draw(),但只会绘制调用者本身。 3、setVisibility()方法 : 当View可视状态在INVISIBLE转换VISIBLE时,会间接调用invalidate()方法,继而绘制该View。 4 、setEnabled()方法 : 请求重新draw(),但不会重新绘制任何视图包括该调用者本身。 requestLayout()方法 会导致调用measure()过程 和 layout()过程 。 说明:只是对View树重新布局layout过程包括measure()和layout()过程,不会调用draw()过程,但不会重新绘制任何视图包括该调用者本身。 一般引起invalidate()操作的函数如下: 1、setVisibility()方法: 当View的可视状态在INVISIBLE/ VISIBLE 转换为GONE状态时,会间接调用requestLayout() 和invalidate方法。 同时,由于整个个View树大小发生了变化,会请求measure()过程以及draw()过程,同样地,只绘制需要“重新绘制”的视图。 requestFocus() 说明:请求View树的draw()过程,但只绘制“需要重绘”的视图。 View中的draw和onDraw的区别 1.大概扫一下源码就可以明白,draw()这个函数本身会做很多事情, * 1. Draw the background * 2. If necessary, save the canvas' layers to prepare for fading * 3. Draw view's content * 4. Draw children * 5. If necessary, draw the fading edges and restore layers * 6. Draw decorations (scrollbars for instance)在第三步的时候,它就会调用onDraw()方法,来绘制view的内容。也就是draw会调用onDraw。所以看需要,一般情况下,直接用onDraw绘制view的content就可以了,如果绘制多一点的内容,可以调用draw(),不过Android官方推荐用只用onDraw就可以了。“When implementing a view, do not override this method; instead, you should implement onDraw” 2.View组件的绘制会调用draw(Canvas canvas)方法,draw过程中主要是先画Drawable背景,对drawable调用setBounds(),然后是draw(Canvas c)方法.有点注意的是背景drawable的实际大小会影响view组件的大小,drawable的实际大小通过getIntrinsicWidth()和getIntrinsicHeight()获取,当背景比较大时view组件大小等于背景drawable的大小,画完背景后,draw过程会调用onDraw(Canvas canvas)方法,然后就是dispatchDraw(Canvas canvas)方法, dispatchDraw()主要是分发给子组件进行绘制,我们通常定制组件的时候重写的是onDraw()方法。值得注意的是ViewGroup容器组件的绘制,当它没有背景时直接调用的是dispatchDraw()方法, 而绕过了draw()方法,当它有背景的时候就调用draw()方法,而draw()方法里包含了dispatchDraw()方法的调用。因此要在ViewGroup上绘制东西的时候往往重写的是dispatchDraw()方法而不是onDraw()方法,或者自定制一个Drawable,重写它的draw(Canvas c)和 getIntrinsicWidth(),getIntrinsicHeight()方法,然后设为背景。 3.ondraw() 和dispatchdraw()的区别 绘制VIew本身的内容,通过调用View.onDraw(canvas)函数实现 绘制自己的孩子通过dispatchDraw(canvas)实现 本文转自我爱物联网博客园博客,原文链接:http://www.cnblogs.com/yydcdut/p/3960826.html,如需转载请自行联系原作者