使用Oracle GoldenGate Marketplace实现数据快速同步ADW
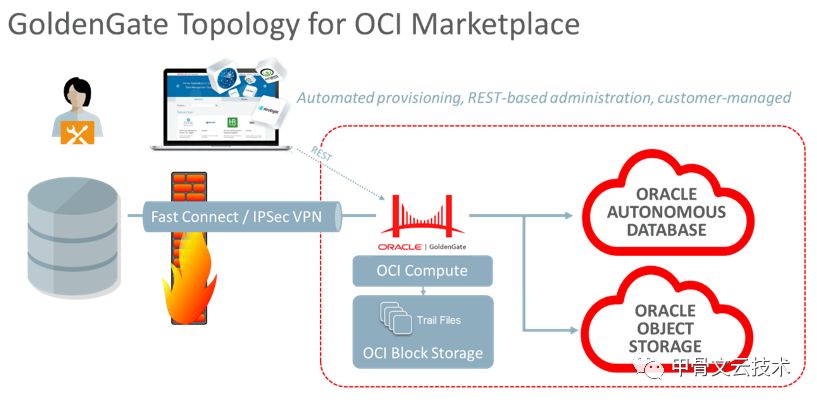
Oracle GoldenGate 是一个实现异构 IT 环境间数据实时数据集成和复制的综合软件包。该产品集支持高可用性解决方案、实时数据集成、事务更改数据捕获、运营和分析企业系统之间的数据复制、转换和验证。 GOLDENGATE 19.1 ON MARKETPLACE功能 Oracle GoldenGate for Oracle 19.1微服务版包括对Oracle数据库版本11g,12c,18c,19c,Cloud以及本地数据库的捕获和交付支持。允许从任何Oracle数据库平台和操作系统进行远程捕获,且无需在源端和目标端数据库安装任何介质。 GoldenGate on OCI微服务架构如下: 此文将逐步介绍如何使用Oracle GoldenGate Marketplace 搭建客户已有的Oracle数据库到Oracle ADW 业务数据平台的数据实时同步。 整体步骤大致如下: 1.在ORACLE CLOUD MARKETPLACE上部署GOLDENGATE微服务 2.配置源端/目标端数据库 3.Oracle GoldenGate 微服务配置 4.数据同步测试:ORACLE12C到ADW ORACLE CLOUD MARKETPLACE上部署GOLDENGATE微服务 通过在Oracle Cloud Marketplace上使用Oracle GoldenGate微服务,可以轻松地建立和管理从本地到云,本地到本地以及云到云的数据实时复制。 1.从Oracle Cloud Marketplace主页: https://cloudmarketplace.oracle.com/marketplace 2.使用“应用程序”下的搜索框并搜索关键字GoldenGate。 3.在Oracle Cloud Marketplace中找到Oracle GoldenGate微服务列表后,您可以使用提供的TerraForm Stack部署Oracle GoldenGate。 选择版本(19.1.0.0.1默认)选择需要部署到的Compartment,单击“Launch Stack”。 4.填写Stack所需信息,其中包括Stack的名称,单击“下一步”。 5.填写以下详细信息。使用Oracle GoldenGate Microservices构建计算节点需要此信息。 显示名称 - 用于标识所有新OCI资源的显示名称。Oracle GoldenGate 主机DNS名称 - 新计算节点的域名服务的名称。 选择需要部署的Compartment. 如果要创建新网络资源,请选中此复选框。 我们选择以有的网络资源 6.选择计算资源 -支持的资源是VM.Standard2.4,VM.Standard2.8,VM.Standard2.16和VM.Standard2.24。这次选择VM.Standard2.4 分配公共IP - 选中此复选框以指示新VM是否应具有公共IP地址。 部署1 - 名称(必填) - 第一个Oracle GoldenGate部署的名称。Source 部署1 - 数据库(必填) - Oracle 12c 部署2 - 名称(可选) - 第二个Oracle GoldenGate部署的名称。Target 部署2 - 数据库(可选) - Oracle 18c 粘贴SSH公钥 - 允许SSH访问作为opc用户的公钥 7.在“确认”页面上,查看您提供的信息,然后单击“创建”。 8.名称为“OGG4ADW”Stack创建成功 9.现在可以在计算节点Instances选项卡下查看Oracle GoldenGate Microservices计算节点。 10.获取Oracle GoldenGate管理员密码 获取公共IP地址后,您必须获取Oracle GoldenGate管理员帐户(oggadmin)的密码。 Oracle GoldenGate管理员帐户(oggadmin)和密码保存在~/ogg-credentials.json文件里。 记录密码。 配置源端数据库 1.配置源或目标数据库以进行复制--源端数据库 源端数据库配置:在源端数据库打开附加日志以及OGG所需配置。 2.源端数据库: 创建OGG管理员c##ggadmin和测试用户SCOTT 3.测试用户SCOTT下,创建测试表EMP SQL> show user USER is "SCOTT" SQL> CREATE TABLE EMP (EMPNO NUMBER(4) NOT NULL, ENAME VARCHAR2(10), JOB VARCHAR2(9), MGR NUMBER(4), HIREDATE DATE, SAL NUMBER(7, 2), COMM NUMBER(7, 2), DEPTNO NUMBER(2)); Table created. SQL> ALTER TABLE EMP ADD CONSTRAINT PK_EMPNO PRIMARY KEY(EMPNO); Table altered. SQL> select count(1) from emp; COUNT(1) ---------- 0 配置目标端端数据库 1.目标端数据库配置(ADW): SQL> alter user ggadmin identified by <password> account unlock; User altered. SQL> grant dwrole to ggadmin; Grant succeeded. SQL> grant pdb_dba to ggadmin; Grant succeeded. SQL> grant create session, resource, create view, create table to ggadmin; Grant succeeded. SQL> select name,value from v$parameter where name='enable_goldengate_replication'; NAME VALUE ---------------------------------------- ---------- enable_goldengate_replication TRUE SQL> create user scott identified by <password>; User created. SQL> grant connect,resource,create table to scott; Grant succeeded. SQL> grant pdb_dba to scott; Grant succeeded. SQL> alter user scott quota unlimited on data; User altered. 2.目标端数据库上创建测试用户SCOTT和EMP表: SQL> show user USER is "SCOTT" SQL> CREATE TABLE EMP 2 (EMPNO NUMBER(4) NOT NULL, 3 ENAME VARCHAR2(10), 4 JOB VARCHAR2(9), 5 MGR NUMBER(4), 6 HIREDATE DATE, 7 SAL NUMBER(7, 2), 8 COMM NUMBER(7, 2), 9 DEPTNO NUMBER(2)); Table created. SQL> desc emp Name Null? Type ----------------------------------------- -------- ---------------------------- EMPNO NOT NULL NUMBER(4) ENAME VARCHAR2(10) JOB VARCHAR2(9) MGR NUMBER(4) HIREDATE DATE SAL NUMBER(7,2) COMM NUMBER(7,2) DEPTNO NUMBER(2) SQL> ALTER TABLE EMP ADD CONSTRAINT PK_EMPNO PRIMARY KEY(EMPNO); Table altered. SQL> select count(1) from emp; COUNT(1) ---------- 0 ORACLE GOLDENGATE MICROSERVICES更改管理员密码 1.更改OGG默认管理员OGGADMIN密码 更改OGG默认管理员密码(例如oggadmin)是保护Oracle GoldenGate Microservices部署的首要任务。需要更改oggadmin的密码,您必须先在Service Manager和Administration Server中更改它。 浏览器中输入https://<public_ip_address> 进入OGG管理页面如下: 单击”转到此网页” 输入OGG管理用户名以及保存在~/ogg-credentials.json文件里的密码 2.登录Service Manager后使用左上角的菜单图标打开菜单,从菜单中选择Administrator 在“oggadmin”编辑选项,更新oggadmin用户的密码,单击“提交”。 3.从Service Manager页面中,点击“Overview”回到控制台, 在部署框中选择Administration Server的端口号。这将导航到该部署的登录页面。 使用oggadmin用户及密码登录。也需要在每个部署的页面上更新oggadmin用户的密码。 分别点击Administration Server的端口9011和9021 4.9011和9021的每个部署的页面上更新oggadmin用户的密码 5.Oracle GoldenGate Microservices计算节点中配置环境变量: 点击下面的Source 6.源端数据库为12cR2,所以ORACLE_HOME配置为/u01/app/client/oracle12 7.目标端数据库为18c,所以ORACLE_HOME配置为/u01/app/client/oracle18 使用ORACLE GOL 使用ORACLE GOLDENGATE MICROSERVICES创建数据库连接 创建配置源端数据库连接 1.通过点击Administration Server的端口号。9011 这将导航到该部署的登录页面 打开Overview页面左上角的上下文菜单,从上下文菜单中,选择“配置”。 在“数据库”选项卡中,单击加号(+)图标以添加新凭证。 源端因为是12c多租户数据库,所以我们分别创建连接CDB和PDB的数据库凭证如下: 2.点击测试按钮,进行数据库连接测试如下:CDB 连接成功会显示Checkpoint等信息 3.点击测试按钮,进行数据库连接测试如下:PDB 在源端添加SCHEMATRANDATA 4.添加用于连接到源数据库的凭证后,必须在源端上启用事务数据日志记录。 从Oracle Database 12.1和更高版本开始,您必须使用模式指定PDB数据库。 即<pdb>.<schema> pdb1.scott 创建配置目标端数据库连接 1.通过点击Administration Server的端口号。9021 这将导航到该部署的登录页面 打开Overview页面左上角的上下文菜单,从上下文菜单中,选择“配置”。 在“数据库”选项卡中,单击加号(+)图标以添加新凭证。 目标端是ADW18c数据库,所以我们创建到数据库凭证如下: 2.点击测试按钮,进行数据库连接测试如下: 连接成功会显示Checkpoint等信息 在目标端添加检查点表 3.检查点表对于监视已应用于目标系统的检查点至关重要。无论使用何种复制,最佳做法是为目标系统启用检查点表。 Checkpoint选项中,点击添加 使用ORACLE GOLDENGATE MICROSERVICES配置进程 目前,Oracle自治数据仓库云仅支持非集成模式的Replicat。 不支持集成模式Replicat,parallel Replicat和coordindated Replicat。 配置捕获进程 在开始复制之前,您必须设置捕获进程。 Oracle GoldenGate Microservices支持三种模式的捕获进程。 Classic Extract -- OGG18c之后版本不建议使用,不支持同步到ADW/ATP Integrated Extract Initial Load Extract 配置EXTRACT进程 1.从源端管理控制台中选择添加Extract进程如下: 2.选择Integrated Extract进程,点击“Next” 3.输入Extract进程相关信息如下: 进程名:ext 数据库连接信息:源端选择CDB连接(source),创建连接参照上述创建连接部分。 Trail文件名:eg 4.选择需要注册的PDB1,点击“Next” 5.下一步填写进程相关配置信息如下:Table pdb1.scott.emp; extract ext useridalias oggadmin_pdb domain sourcepdb exttrail eg Table pdb1.scott.emp; 控制台上选择注册Extract进程到数据库,点击“创建和执行” 6.在控制台可以看到Extract进程。 配置REPLICAT进程 1.点击目标端管理服务器端口进入控制台,配置Replicat进程 2.点击添加Replicat进程 3.选择Nonintegrated Replicat 4.输入Replicat配置信息如下:目标端连接target,选择checkpoint table 5.下一步填写进程相关配置信息如下: MAP pdb1.scott.emp, TARGET MSHUTOQY95TFZPE_ADW.SCOTT.emp; 点击“创建和执行” replicat rep useridalias target domain target MAP pdb1.scott.emp, TARGET MSHUTOQY95TFZPE_ADW.SCOTT.emp; 6.在控制台可以看到Replicat进程。 数据同步测试:ORA数据同步测试:ORACLE12C到ADW 源端插入数据 SQL> select count(1) from emp; COUNT(1) ---------- 0 SQL> INSERT INTO EMP VALUES(7369, 'SMITH', 'CLERK', 7902, sysdate, 800, NULL, 20); 1 row created. SQL> INSERT INTO EMP VALUES (7499, 'ALLEN', 'SALESMAN', 7698, sysdate, 1600, 300, 30); 1 row created. SQL> commit; Commit complete. SQL> select count(1) from emp; COUNT(1) ---------- 2 从Extract进程选项中选择“详细” 在统计栏中查看同步信息 2条数据成功的被捕获 在目标端确认数据同步成功 SQL> select * from emp; EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO ----- ---------- ---------- ----- --------- ---------- ---------- ---------- 7369 SMITH CLERK 7902 24-JUL-19 800 20 7499 ALLEN SALESMAN 7698 24-JUL-19 1600 300 30 通过点击目标端的进程详细,统计栏显示2条数据已经插入 测试删除数据从源端数据库 SQL> select count(1) from emp; COUNT(1) ---------- 2 SQL> delete emp; 2 rows deleted. SQL> commit; Commit complete. 通过点击源端的进程详细,统计栏显示删除已经被捕获 目标端确认数据源已经被删除 SQL> select * from emp ; no rows selected 通过点击目标端的进程详细,统计栏显示删除已经被同步