Python 学习(八)--网络操作
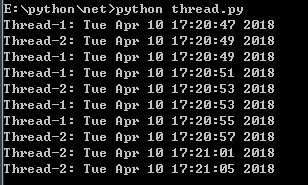
Python 提供了两个级别访问的网络服务: 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统Socket接口的全部方法。 高级别的网络服务模块 SocketServer, 它提供了服务器中心类,可以简化网络服务器的开发。 1. Socket Socket又称"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯。 socket()函数 Python 中,我们用 socket()函数来创建套接字,语法格式如下: socket.socket([family[, type[, proto]]]) 参数 family: 套接字家族可以使AF_UNIX或者AF_INET type: 套接字类型可以根据是面向连接的还是非连接分为SOCK_STREAM或SOCK_DGRAM protocol: 一般不填默认为0. Socket 对象(内建)方法 服务器端套接字 1). s.bind() : 绑定地址(host,port)到套接字, 在AF_INET下,以元组(host,port)的形式表示地址。 2). s.listen() : 开始TCP监听。backlog指定在拒绝连接之前,操作系统可以挂起的最大连接数量。该值至少为1,大部分应用程序设为5就可以了。 3). s.accept() : 被动接受TCP客户端连接,(阻塞式)等待连接的到来 客户端套接字 1). s.connect() : 主动初始化TCP服务器连接,。一般address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。 2). s.connect_ex() : connect()函数的扩展版本,出错时返回出错码,而不是抛出异常 公共用途的套接字函数 1). s.recv() : 接收TCP数据,数据以字符串形式返回,bufsize指定要接收的最大数据量。flag提供有关消息的其他信息,通常可以忽略。 2). s.send() : 发送TCP数据,将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。 3). s.sendall() : 完整发送TCP数据,完整发送TCP数据。将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。 4). s.recvfrom() : 接收UDP数据,与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。 5). s.sendto() : 发送UDP数据,将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。 6). s.close() : 关闭套接字 7). s.getpeername() : 返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。 8). s.getsockname() : 返回套接字自己的地址。通常是一个元组(ipaddr,port) 9). s.setsockopt(level,optname,value) : 设置给定套接字选项的值。 10). s.getsockopt(level,optname[.buflen]) : 返回套接字选项的值。 11). s.settimeout(timeout) : 设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如connect()) 12). s.gettimeout() : 返回当前超时期的值,单位是秒,如果没有设置超时期,则返回None。 13). s.fileno() : 返回套接字的文件描述符。 14). s.setblocking(flag) : 如果flag为0,则将套接字设为非阻塞模式,否则将套接字设为阻塞模式(默认值)。非阻塞模式下,如果调用recv()没有发现任何数据,或send()调用无法立即发送数据,那么将引起socket.error异常。 15). s.makefile() : 创建一个与该套接字相关连的文件 2. Socket示例 1). 服务端 我们使用 socket 模块的 socket 函数来创建一个 socket 对象。socket 对象可以通过调用其他函数来设置一个 socket 服务。现在我们可以通过调用 bind(hostname, port) 函数来指定服务的 port(端口)。接着,我们调用 socket 对象的 accept 方法。该方法等待客户端的连接,并返回 connection 对象,表示已连接到客户端。 # 文件名:server.py # 导入 socket、sys模块 import socket import sys # 创建socket对象 serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 获取本地主机名 host = socket.gethostname() # 设置端口 port = 9999 # 绑定端口号 serversocket.bind((host, port)) # 设置最大连接数, 超过后排队 serversocket.listen(5) while True: # 建立客户端连接 clientsocket, addr = serversocket.accept() print("连接地址:%s" % str(addr)) msg = "欢迎访问小雨工作室" + "\r\n" clientsocket.send(msg.encode("utf-8")) clientsocket.close() pass 2). 客户端 接下来我们写一个简单的客户端实例连接到以上创建的服务。端口号为 9999。 socket.connect(hosname, port ) 方法打开一个 TCP 连接到主机为 hostname 端口为 port 的服务商。连接后我们就可以从服务端后期数据,记住,操作完成后需要关闭连接。 # 文件名:client.py # 导入 socket、sys模块 import socket import sys # 创建socket对象 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 获取本地主机名 host = socket.gethostname() # 设置端口号 port = 9999 # 连接服务,指定主机和端口 s.connect((host, port)) # 接收小于1024字节的数据 msg = s.recv(1024) # 关闭客户端 s.close() print(msg.decode("utf-8")) 3). 运行结果: 打开两个命令提示符窗口,一个运行服务器,一个运行客户端。 图1.png 3. Python Internet 模块 图2.png 4. SMTP发送邮件 SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。python的smtplib提供了一种很方便的途径发送电子邮件。它对smtp协议进行了简单的封装。 1). Python创建 SMTP 对象语法如下: import smtplib smtpObj = smtplib.SMTP( [host [, port [, local_hostname]]] ) 参数说明: host: SMTP 服务器主机。 你可以指定主机的ip地址或者域名如:runoob.com,这个是可选参数。 port: 如果你提供了 host 参数, 你需要指定 SMTP 服务使用的端口号,一般情况下SMTP端口号为25。 local_hostname: 如果SMTP在你的本机上,你只需要指定服务器地址为 localhost 即可。 2). Python SMTP对象使用sendmail方法发送邮件,语法如下: SMTP.sendmail(from_addr, to_addrs, msg[, mail_options, rcpt_options] 参数说明: from_addr: 邮件发送者地址。 to_addrs: 字符串列表,邮件发送地址。 msg: 发送消息(msg是字符串,表示邮件。我们知道邮件一般由标题,发信人,收件人,邮件内容,附件等构成,发送邮件的时候,要注意msg的格式。这个格式就是smtp协议中定义的格式)。 3). 标准邮件需要三个头部信息: From, To, 和 Subject ,每个信息直接使用空行分割。 我们通过实例化 smtplib 模块的 SMTP 对象 smtpObj 来连接到 SMTP 访问,并使用 sendmail 方法来发送信息本机安装sendmail示例程序: # 导入邮件模块 import smtplib from email.mime.text import MIMEText from email.header import Header # 发送者邮箱 sender= "945541086@qq.com" # 接收者邮箱 receivers = ["zaitingma@foxmail.com"] # 三个参数:第一个是文本内容,第二个是文本格式,第三个是字符编码 message = MIMEText("Python 邮件发送测试", "plain", "utf-8") message["From"] = Header("小雨工作室", "utf-8") message["To"] = Header("测试", "utf-8") # 设置主题 subject = "Python SMTP 邮件测试" message["Subject"] = Header(subject, "utf-8") try: smtpObj = smtplib.SMTP("localhost") smtpObj.sendmail(sender, receivers, message.as_toString()) print("邮件发送成功") pass except Exception as e: print("Error: 无法发送邮件") raise e 本机未安装sendmail示例程序: import smtplib from email.mime.text import MIMEText from email.header import Header # 第三方SMTP服务 # 设置服务器 mail_host="smtp.qq.com" # 设置用户名 mail_user="945541086@qq.com" # 设置口令 mail_pass="***********" # 设置发送者 sender = "945541086@qq.com" # 设置接收者 receivers = ["zaitingma@foxmail.com"] message = MIMEText("Python 邮件发送测试","plain","utf-8") message["From"] = Header("菜鸟教程","utf-8") message["To"] = Header("测试", "utf-8") # 设置主题 subject = "Python SMTP 邮件测试" message["Subject"] = Header(subject, "utf-8") try: smtpObj = smtplib.SMTP() # 25 为 SMTP 端口号 smtpObj.connect(mail_host, 25) smtpObj.login(mail_user, mail_pass) smtpObj.sendmail(sender, receivers, message.as_toString()) print("邮件发送成功") pass except Exception as e: print("Error: 无法发送邮件") raise e 发送带网页的邮件: Python发送HTML格式的邮件与发送纯文本消息的邮件不同之处就是将MIMEText中_subtype设置为html。 import smtplib from email.mime.text import MIMEText from email.header import Header sender = 'from@runoob.com' receivers = ['429240967@qq.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱 mail_msg = """ <p>Python 邮件发送测试...</p> <p><a href="http://www.runoob.com">这是一个链接</a></p> """ message = MIMEText(mail_msg, 'html', 'utf-8') message['From'] = Header("菜鸟教程", 'utf-8') message['To'] = Header("测试", 'utf-8') subject = 'Python SMTP 邮件测试' message['Subject'] = Header(subject, 'utf-8') try: smtpObj = smtplib.SMTP('localhost') smtpObj.sendmail(sender, receivers, message.as_string()) print ("邮件发送成功") except smtplib.SMTPException: print ("Error: 无法发送邮件") 发送带附件的邮件: 发送带附件的邮件,首先要创建MIMEMultipart()实例,然后构造附件,如果有多个附件,可依次构造,最后利用smtplib.smtp发送。 import smtplib from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart from email.header import Header sender = 'from@runoob.com' receivers = ['429240967@qq.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱 #创建一个带附件的实例 message = MIMEMultipart() message['From'] = Header("菜鸟教程", 'utf-8') message['To'] = Header("测试", 'utf-8') subject = 'Python SMTP 邮件测试' message['Subject'] = Header(subject, 'utf-8') #邮件正文内容 message.attach(MIMEText('这是菜鸟教程Python 邮件发送测试……', 'plain', 'utf-8')) # 构造附件1,传送当前目录下的 test.txt 文件 att1 = MIMEText(open('test.txt', 'rb').read(), 'base64', 'utf-8') att1["Content-Type"] = 'application/octet-stream' # 这里的filename可以任意写,写什么名字,邮件中显示什么名字 att1["Content-Disposition"] = 'attachment; filename="test.txt"' message.attach(att1) # 构造附件2,传送当前目录下的 runoob.txt 文件 att2 = MIMEText(open('runoob.txt', 'rb').read(), 'base64', 'utf-8') att2["Content-Type"] = 'application/octet-stream' att2["Content-Disposition"] = 'attachment; filename="runoob.txt"' message.attach(att2) try: smtpObj = smtplib.SMTP('localhost') smtpObj.sendmail(sender, receivers, message.as_string()) print ("邮件发送成功") except smtplib.SMTPException: print ("Error: 无法发送邮件") 在 HTML 文本中添加图片: 邮件的 HTML 文本中一般邮件服务商添加外链是无效的,正确添加突破的实例如下: import smtplib from email.mime.image import MIMEImage from email.mime.multipart import MIMEMultipart from email.mime.text import MIMEText from email.header import Header sender = 'from@runoob.com' receivers = ['429240967@qq.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱 msgRoot = MIMEMultipart('related') msgRoot['From'] = Header("菜鸟教程", 'utf-8') msgRoot['To'] = Header("测试", 'utf-8') subject = 'Python SMTP 邮件测试' msgRoot['Subject'] = Header(subject, 'utf-8') msgAlternative = MIMEMultipart('alternative') msgRoot.attach(msgAlternative) mail_msg = """ <p>Python 邮件发送测试...</p> <p><a href="http://www.runoob.com">菜鸟教程链接</a></p> <p>图片演示:</p> <p><img src="cid:image1"></p> """ msgAlternative.attach(MIMEText(mail_msg, 'html', 'utf-8')) # 指定图片为当前目录 fp = open('test.png', 'rb') msgImage = MIMEImage(fp.read()) fp.close() # 定义图片 ID,在 HTML 文本中引用 msgImage.add_header('Content-ID', '<image1>') msgRoot.attach(msgImage) try: smtpObj = smtplib.SMTP('localhost') smtpObj.sendmail(sender, receivers, msgRoot.as_string()) print ("邮件发送成功") except smtplib.SMTPException: print ("Error: 无法发送邮件") QQ邮箱 QQ 邮箱 SMTP 服务器地址:smtp.qq.com,ssl 端口:465 import smtplib from email.mime.text import MIMEText from email.utils import formataddr my_sender='945541086@qq.com' # 发件人邮箱账号 my_pass = '**************' # 发件人邮箱授权码 my_user='1425941077@qq.com' # 收件人邮箱账号,我这边发送给自己 def mail(): ret=True try: msg=MIMEText('Python 测试邮件发送','plain','utf-8') msg['From']=formataddr(["Mazaiting",my_sender]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号 msg['To']=formataddr(["FK",my_user]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号 msg['Subject']="Python邮件测试" # 邮件的主题,也可以说是标题 server=smtplib.SMTP_SSL("smtp.qq.com", 465) # 发件人邮箱中的SMTP服务器,端口是25 server.login(my_sender, my_pass) # 括号中对应的是发件人邮箱账号、邮箱密码 server.sendmail(my_sender,[my_user,],msg.as_string()) # 括号中对应的是发件人邮箱账号、收件人邮箱账号、发送邮件 server.quit() # 关闭连接 except Exception as e: # 如果 try 中的语句没有执行,则会执行下面的 ret=False ret=False raise e return ret ret=mail() if ret: print("邮件发送成功") else : print("邮件发送失败") 图2.png