Elastic Stack学习--elasticsearch部署
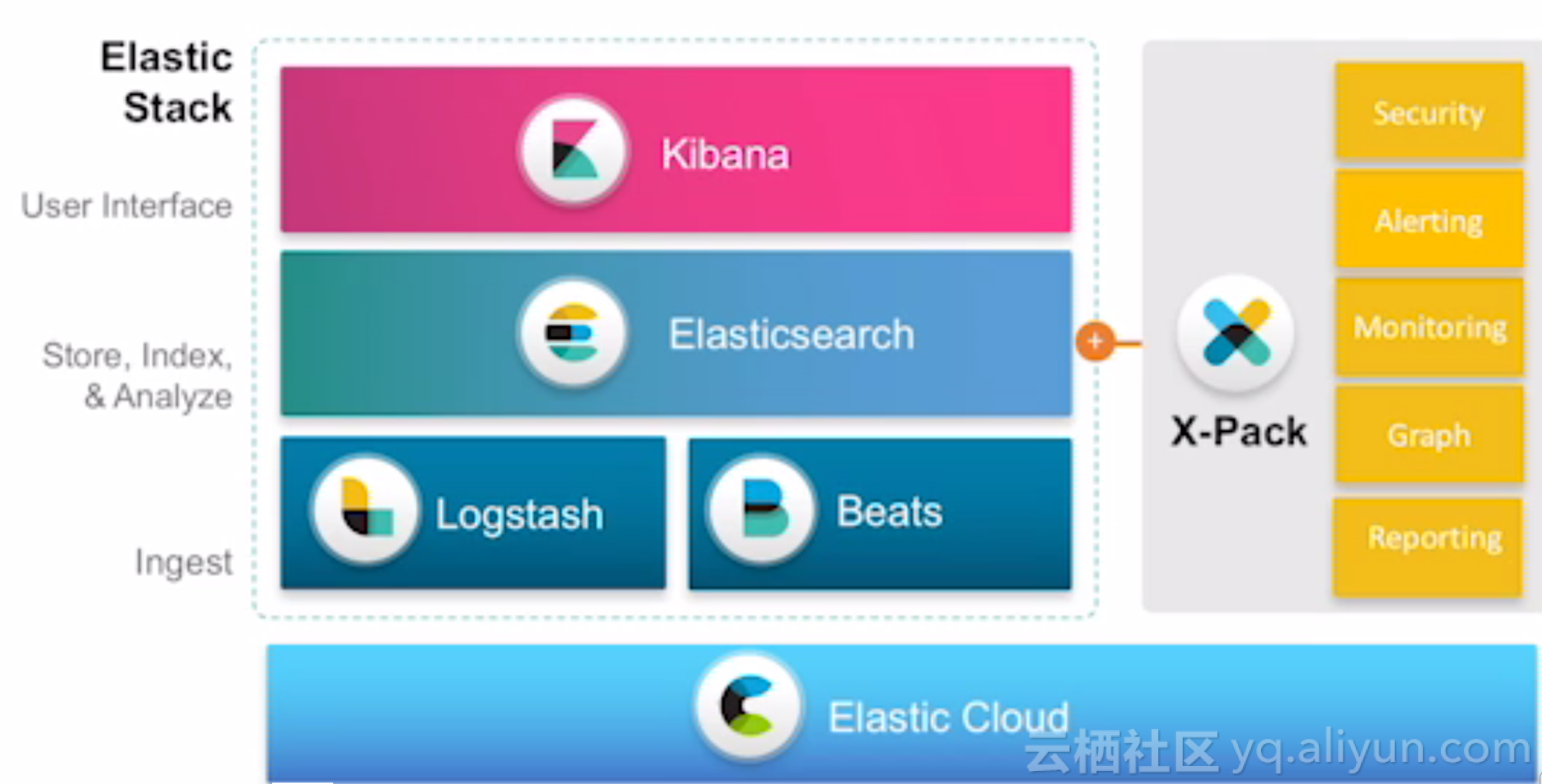
Elastic Stack是一套支持数据采集、存储、分析、展现的全流程数据分析工具,旧时称作ELK(Elasticsearch,Logstash,Kibana的缩写,)。Elastic Stack由一系列的工具集组成,其核心组成如下图: Logstash & Beats:数据采集工具,logstash适合大批量数据的采集,其结构较重,消耗资源较大,适合集群化部署。beats是一系列轻量级的数据采集工具,消耗资源较小,适合分散部署在各个业务节点上收集数据。 Elasticsearch:ELK的核心模块,是一套分布式数据检索引擎,提供数据的检索分析能力;提供二进制和restful两种类型的接口,可供上层进行数据检索; Kibana:前端用户展示界面,一方面,通过界面化方式监控和管理Elasticsearch、logstash等进程。另一方面,提供数据的检索和展示图形化界面; x-pack:一套用于elasticsearch、kibana、logstash的功能增强包,包括权限管理、告警、监控、图形化展现、报表等功能。当前使用收费,计划6.3版本后开源所有功能; Elastic Cloud:Elastic Stack的容器化解决方案,可将Elastic Stack相关进程都实现容器化部署,该功能并非必须功能; Elastic Stack中的每一个工具都可以独立部署使用,可根据实际需求进行技术选型,并非一定要完整安装每一个组件。安装Elastic Stack,首先必须保证所使用的每一个组件都具有相同的版本号,比如:elasticsearch使用6.2.2版本,则kibana、logstash以及相应的客户端组件等都应该使用相同的版本号,以便于功能相互兼容。各个进程组件的安装顺序如下,可根据实际需求取舍: Elasticsearch部署 Elasticsearch安装X-Pack Kibana部署 Kibana安装X-Pack Logstash部署 Logstash安装X-Pack Beats部署 Elasticsearch Hadoop部署 Elasticsearch部署 下载安装包,我们使用tar包:https://www.elastic.co/cn/downloads/elasticsearch 解压并进入目录: tar -xzf elasticsearch-6.2.2.tar.gz cd elasticsearch-6.2.2/ 前台方式启动进程:启动elasticsearch进程,使用默认端口:9200; ./bin/elasticsearch 后台方式启动进程:默认情况下,直接运行elasticsearch命令,将会在命令行启动非后台进程,并且输出日志到stdout。通过ctrl+c或者ctrl+z可以关闭进程;如果想启动后台进程,则可以执行如下命令,其中-d参数表示以守护进程方式运行,-p参数指定pid文件路径: ./bin/elasticsearch -d -p pid_file 通过命令行配置启动参数:elasticsearch可以通过命令行和配置文件(config/elasticsearch.yml文件)两种方式设置启动参数;其中,命令行方式适合配置需要随进程启动动态修改的参数,如node.name配置;而配置文件适合存放变化较小的通用配置,如cluster.name配置;如下是通过命令行参数配置cluster.name和node.name配置的样例,对于每个配置项前面加-E参数: ./bin/elasticsearch -d -Ecluster.name=my_cluster -Enode.name=node_1 问:对于使用命令行配置还是配置文件配置,应该如何取舍?1)看配置项是否需要根据进程每次启动时候动态设置,如果需要,则通过命令行配置,否则通过配置文件配置;2)集群范围的配置使用配置文件配置;特定实例的配置使用命令行配置; 验证启动是否成功:通过curl调用elasticsearch的http端口,查看输出; curl -XGET 'localhost:9200/?pretty' 输出json类似如下: { "name" : "Cp8oag6", "cluster_name" : "elasticsearch", "cluster_uuid" : "AT69_T_DTp-1qgIJlatQqA", "version" : { "number" : "6.2.2", "build_hash" : "f27399d", "build_date" : "2016-03-30T09:51:41.449Z", "build_snapshot" : false, "lucene_version" : "7.2.1", "minimum_wire_compatibility_version" : "1.2.3", "minimum_index_compatibility_version" : "1.2.3" }, "tagline" : "You Know, for Search" } elasticsearch默认目录结构 home:elasticsearch安装根目录,$ES_HOME变量指向目录; bin:存放二进制程序,其中elasticsearch用于启动主进程,elasticsearch-plugin用于安装插件,默认:$ES_HOME/bin; conf:存放配置文件,包括:elasticsearch.yml,jvm.options,log4j2.properties,默认:$ES_HOME/config,通过ES_PATH_CONF环境变量修改; data:数据文件存放路径,可以指定多个,多个路径以逗号分隔默认:$ES_HOME/data,通过path.data配置项修改; logs:日志文件路径,默认:$ES_HOME/logs,通过path.logs配置项修改; plugins:存放安装插件,每个插件放到一个子目录中,默认:$ES_HOME/plugins; repo:共享文件系统仓库路径,默认:未配置,通过path.repo配置项修改; script:脚本文件路径,默认:$ES_HOME/scripts,通过path.scripts配置项修改; elasticsearch配置文件 配置文件默认放在$ES_HOME/config目录,可以通过设置ES_PATH_CONF环境变量修改: export ES_PATH_CONF=/path/to/my/config ./bin/elasticsearch elasticsearch包括3个配置文件: elasticsearch.yml:主要配置文件; jvm.options:jvm参数配置,比如堆内存; log4j2.properties:日志配置; elasticsearch.yml elasticsearch.yml配置文件使用yaml格式配置,可以支持环境变量; node.name: ${HOSTNAME} network.host: ${ES_NETWORK_HOST} jvm.options jvm.options用于配置虚拟机参数,也可以通过$ES_JAVA_OPTS环境变量进行修改; export ES_JAVA_OPTS="$ES_JAVA_OPTS -Djava.io.tmpdir=/path/to/temp/dir" ./bin/elasticsearch elasticsearch常用配置项整理 path.data 和 path.logs默认情况下,elasticsearch会将数据和日志存放到根目录的data和logs目录下,如果需要改变数据或者日志的存放路径,则可以显式设置path.data和path.logs。path.data可以指定多个路径,便于将数据存放到多块磁盘上。 cluster.name用于唯一标识一个elastic集群的集群名称,一个节点只能归属于一个集群,因此只能指定一个集群名称。默认名称为elasticsearch;节点间会根据集群名称判断是否归属于同一个集群,因此不同的集群名称一定不能相同。 node.nameelasticsearch使用nodeId唯一标识一个实例,默认情况下,会使用UUID的前7位作为实例的nodeId,nodeId会被持久化,不会随着实例重启而发生变化。通过node.name可以指定一个实例的nodeId,可以使名称可读或者更加有意义。如果一个主机下仅部署一个实例,则可以指定node.name为主机名: node.name: ${HOSTNAME} network.host用于指定elasticsearch实例绑定的ip地址,默认为:127.0.0.1和[::1]。对于集群而言,每个实例都应该指定一个非回环地址,便于被网络中的节点发现; discovery.zen.ping.unicast.hostselasticsearch发现集群的方式为点对点查找,因此需要指定集群中的每个节点所在的ip地址和端口,如果不指定端口,则默认查找9300端口;可以是如下格式: discovery.zen.ping.unicast.hosts: - 192.168.1.10:9300 - 192.168.1.11 - seeds.mydomain.com discovery.zen.minimum_master_nodes标识选举master时,至少需要几票才可以当选,为了减缓脑裂的发生,通常设置该值为: ( 参选节点数 / 2 ) + 1 堆内存设置 堆内存设置在jvm.options配置文件中,默认设置为1GB;在生产环境下,该值通常需要调整。调整建议如下:设置xms和xmx相等,以便于一开始边分配好所需内存,避免增量分配内存带来的性能消耗;xmx设置不超过可用物理内存的50%,以确保内核文件系统有足够内存用作缓存;xmx设置应该小于jvm指针压缩的临界点,因为超过该临界点,jvm将不使用指针压缩,导致内存使用量增加;一般临界点值小于32G,不同的系统有所不同,设置26G大小可以满足大多数系统指针压缩条件。可通过添加如下参数来测试临界点: -XX:+UnlockDiagnosticVMOptions -XX:+PrintCompressedOopsMode 也可以通过$ES_JAVA_OPTS环境变量设置虚拟机参数; 重要系统配置 设置系统资源上限elasticsearch需要调整使用系统资源的限制,如文件文件句柄数的限制。不同操作系统的参数配置不同。linux系统下,系统参数的配置通过如下两种方式: 临时配置:使用ulimit命令配置; 永久配置:在/etc/security/limits.conf中配置; bootstrap.memory_lock:禁用swap默认情况下,操作系统会开启swap。使用swap,可能将jvm堆内存交换到硬盘上,导致jvm回收性能由毫秒级变为分钟级,可能导致响应变慢或者集群断连。通过设置bootstrap.memory_lock为true,来禁止elasticsearch内存被交换出去;通过如下命令可以检测配置是否生效: curl -XGET 'localhost:9200/_nodes?filter_path=**.mlockall&pretty' 如果返回false,则说明锁定失败; 文件句柄数配置elasticsearch会使用较多文件句柄,因而需要设置elasticsearch文件句柄数高于65536个;通过如下命令配置: ulimit -n 65536 或者在/etc/security/limits.conf中配置nofile: username - nofile 65536 可通过如下命令检查当前允许的最大文件句柄数: curl -XGET 'localhost:9200/_nodes/stats/process?filter_path=**.max_file_descriptors&pretty' 虚拟内存设置elasticsearch默认使用mmapfs类型目录存放索引,而操作系统默认的mmap个数太低,需要调高;通过在root用户下执行如下命令进行调整: sysctl -w vm.max_map_count=262144 如果需要永久生效,则更新/etc/sysctl.conf中的vm.max_map_count配置; 设置线程数elasticsearch使用多个线程池来进行不同类型的操作,需要确保系统线程数限制高于4096;可通过如下命令配置: ulimit -u 4096 或者在/etc/security/limits.conf中配置nproc数量; username - nproc 4096 常用环境变量 $ES_HOME:elasticsearch安装根目录; $ES_PATH_CONF:elasticsearch配置文件存放目录; $ES_JAVA_OPTS:jvm参数配置; $ES_TMPDIR:配置临时文件存放目录;即java.io.tmpdir的值;默认:/tmp 参考资料 Elasticsearch: Getting StartedProven Architectural Patterns for Mature Elastic Stack DeploymentsIntroduction to Logging Architecture with Elastic (FR)集群分片部署策略