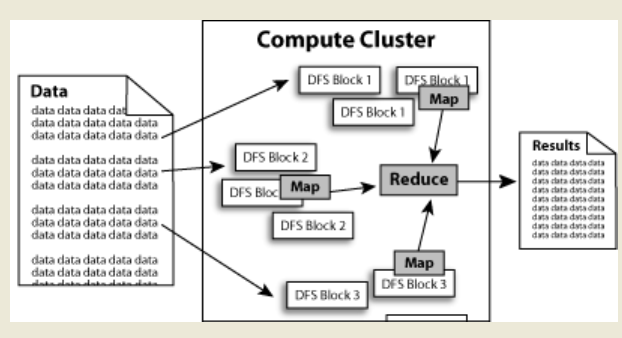
完全分布式安装hadoop
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq1010885678/article/details/43499577 以三个节点为例的服务器集群来安装和配置hadoop 以下是各服务器ip地址和对应所做的节点 192.168.61.128 master 192.168.61.129 slave1 192.168.61.133 slave2 首先修改每个服务器上的hosts文件 使用命令 vi /etc/hosts编辑 在最后追加 192.168.61.128 master 192.168.61.129 slave1 192.168.61.133 slave2 三行 为每个服务器创建hadoop账户 在root用户下,使用命令 useradd hadoop passwd hadoop 输入两遍新密码完成 为每个服务器安装jdk jdk文件版本为jdk-7u45-linux-i586.rpm 可以在官网上下载各个版本的linux jdk文件 使用命令 rpm -ivh jdk-7u45-linux-i586.rpm 进行安装 安装完成之后编辑profile文件配置环境变量 vi /etc/profile 在末尾追加 export JAVA_HOME=/usr/java/jdk1.7.0_45 export PATH=$JAVA_HOME/bin/:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar 注意jdk对应的版本号 编辑完成后使用命令 source /etc/profile 保存配置 之后输入java -version可以查看jdk版本信息 配置ssh免密码登录 在每个服务器上 输入命令 chmod -R 755 /home/hadoop mkdir ~/.ssh ssh-keygen -t rsa ssh-keygen -t dsa rsa和dsa分别生成不同加密格式的ssh密钥,直接一直按回车键保存在默认的路径 在master节点上配置authorized_keys文件 输入命令 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 将本地的密钥保存在authorized_keys ssh slave1 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys ssh slave1 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys ssh slave2 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys ssh slave2 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 使用ssh分别将slave1和slave2节点上的密钥保存在authorized_keys 这样之后,master节点上的authorized_keys文件就保存了所有服务器的密钥 由于还没有设置ssh免密码登录,所以传输的时候需要输入各个节点的密码(系统对用hadoop用户的密码) 之后将这个文件分别传输到各个节点上 scp ~/.ssh/authorized_keys slave1:~/.ssh/authorized_keys scp ~/.ssh/authorized_keys slave2:~/.ssh/authorized_keys 配置完成 接下来要对各个节点上的.ssh目录设置权限(很重要,有时候就是因为权限问题无法登陆) 输入命令 chmod -R 700 ~/.ssh 注意当前你所在的路径 接下来可以再每个服务器上测试ssh是否可以免密码登录了 例: 在master节点上输入 ssh master date 将会提示 The authenticity of host 'master (10.10.10.100)' can't be established. RSA key fingerprint is 99:ef:c2:9e:28:e3:b6:83:e2:00:eb:a3:ee:ad:29:d8. Are you sure you want to continue connecting (yes/no)? 这是因为这台机器上的ssh没有把master记录在已知的主机列表中 输入yes回车即可 (之后的各个节点一样,输入yes让其记住主机,之后就可以免密码登录) 如果中间出现什么异常或者错误,有可能是权限问题导致,请百度之 在master节点上配置hadoop 将hadoop包放到/home.hadoop目录下方便操作 进入hadoop目录下的conf目录 1.修改hadoop-env.sh文件 添加 export JAVA_HOME=/usr/java/jdk1.7.0_45 配置jdk的环境变量,注意jdk版本 2.修改core-site.xml文件 <property> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/tmp</value> </property> 设置namenode节点的IP和端口 设置hadoop.tmp.dir路径,默认是/tmp/$username,重启就会删除该目录的文件,所以这里给他配置一个自定义的路径 3.修改hdfs-site.xml文件 <property> <name>dfs.data.dir</name> <value>/home/hadoop/hadoop-data</value> </property> <property> <name>dfs.name.dir</name> <value>/home/hadoop/hadoop-name</value> </property> <property> <name>fs.checkpoint.dir</name> <value>/home/hadoop/hadoop-namesecondary</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> 设置hdfs文件系统 4.修改mapred-site.xml文件 <property> <name>mapred.job.tracker</name> <value>master:9001</value> </property> 设置jobtracker的ip和端口 以上xml文件的配置都只是在源文件的基础上添加对应的property节点即可 5.在conf目录下 vi masters 输入master vi slaves 输入 slave1 slave2 有几个slave节点就写几个,注意换行 配置完成之后使用ssh将hadoop传输到各个节点上 scp -r hadoop-0.20.2/ slave1:~/ scp -r hadoop-0.20.2/ slave2:~/ 传输完毕之后再master节点上 进入hadoop目录下的bin目录 输入命令 hadoop namenode -format 开始格式化namenode 注意看提示格式化是否成功 在输入命令 start-all.sh 启动hadoop集群 启动完成后 在master节点输入jps可以看到已经在运行的namenode,secondarynode和tasktracker进程 在各个slave节点上输入jps可以看到已经在运行的datanode和jobtracker进程 在master节点输入stop-all.sh可以停止集群运行 如果遇到在slave节点上的进程运行一会就自动停止 可能原因有两个: 1.系统防火墙阻止 在各个节点上,切换到root用户使用命令 service iptables stop 成功会返回三个ok提示,关闭防火墙 2.先使用stop-all.sh停止集群 在core-site.xml文件中配置的hadoop.tmp.dir的值,找到对应的路径 删除里面的文件 然后使用 hadoop namenode -format 重新格式化一下namenode 如果其实hadoop-name文件已经存在,找到这个文件夹,删除之,在重新格式化即可 在使用start-all.sh启动集群 以上每个步骤确保看到成功的提示(或者没有失败的提示) 在配置过程中就是因为没有仔细看系统提示 失败的操作一直以为是成功的导致浪费了大量的时间 另外,操作使用的hadoop版本是0.20.2 如果出现其他的错误,可以到各个节点的hadoop目录下的logs文件件查看对应的日志文件 在到网上自行百度之~ 启动完成之后在任意一个节点中打开浏览器输入一下网址可以通过WEB界面查看hadoop http://192.168.61.128:50030/(jobtracker的HTTP服务器地址和端口) http://192.168.61.128:50060/(taskertracker的HTTP服务器地址和端口) http://192.168.61.128:50070/(namenode的HTTP服务器地址和端口) http://192.168.61.128:50075/(datanode的HTTP服务器地址和端口) http://192.168.61.128:50090/(secondary namenode的HTTP服务器地址和端口)