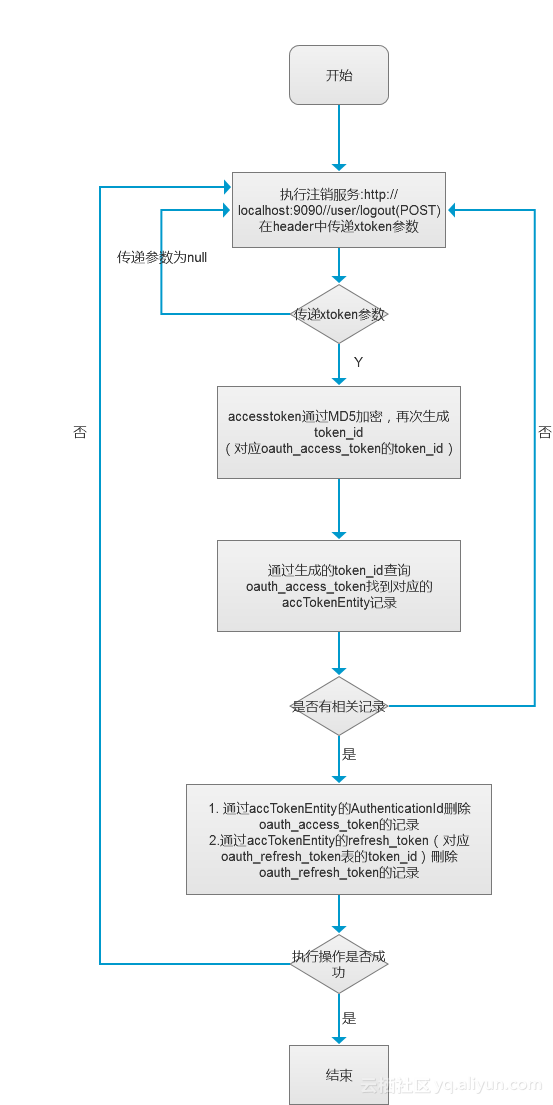
HTTP访问的两种方式(HttpClient+HttpURLConnection)整合汇总对比(转)
在Android上http 操作类有两种,分别是HttpClient和HttpURLConnection,其中两个类的详细介绍可以问度娘。 HttpClient: HttpClient是Apache Jakarta Common下的子项目,用来提供高效的、最新的、功能丰富的支持HTTP协议的客户端编程工具包,并且它支持HTTP协议最新的版本和建议。HttpClient其实是一个interface类型,已知3个实现类为AbstractHttpClient, AndroidHttpClient, DefaultHttpClient,查看文档发现DefaultHttpClient也是继承自AbstractHttpClient。HttpClient封装了对象需要执行的Http请求、身份验证、连接管理和其它特性。HttpClient有三个已知的实现类分别是:AbstractHttpClient, AndroidHttpClient, DefaultHttpClient,会发现有一个专门为Android应用准备的实现类AndroidHttpClient,当然使用常规的DefaultHttpClient也可以实现功能,但是既然开发的是Android应用程序,还是使用Android专有的实现类,一定有其优势。 HttpClient支持但默认不带GZIP压缩,可以自己写。 使用方法: 1.创建HttpClient对象。 2.创建请求方法的实例,并指定请求URL。如果需要发送GET请求,创建HttpGet对象;如果需要发送POST请求,创建HttpPost对象。 3.如果需要发送请求参数,可调用HttpGet、HttpPost共同的setParams(HetpParams params)方法来添加请求参数;对于HttpPost对象而言,也可调用setEntity(HttpEntity entity)方法来设置请求参数。 4.调用HttpClient对象的execute(HttpUriRequest request)发送请求,该方法返回一个HttpResponse。 5.调用HttpResponse的getAllHeaders()、getHeaders(String name)等方法可获取服务器的响应头;调用HttpResponse的getEntity()方法可获取HttpEntity对象,该对象包装了服务器的响应内容。程序可通过该对象获取服务器的响应内容。 6.释放连接。无论执行方法是否成功,都必须释放连接 示例: NameValuePair nameValuePair1 = new BasicNameValuePair("name", "yang"); NameValuePair nameValuePair2 = new BasicNameValuePair("pwd","123123"); List nameValuePairs = new ArrayList(); nameValuePairs.add(nameValuePair1); nameValuePairs.add(nameValuePair2); String validateURL = "http://10.0.2.2:8080/testhttp1/TestServlet"; try { HttpParams httpParams = new BasicHttpParams(); HttpConnectionParams.setConnectionTimeout(httpParams,5000); //设置连接超时为5秒 HttpClient client = new DefaultHttpClient(httpParams); // 生成一个http客户端发送请求对象 HttpPost httpPost = new HttpPost(urlString); //设定请求方式 if (nameValuePairs!=null && nameValuePairs.size()!=0) { //把键值对进行编码操作并放入HttpEntity对象中 httpPost.setEntity(new UrlEncodedFormEntity(nameValuePairs,HTTP.UTF_8)); } HttpResponse httpResponse = client.execute(httpPost); // 发送请求并等待响应 // 判断网络连接是否成功 if (httpResponse.getStatusLine().getStatusCode() != 200) { System.out.println("网络错误异常!!!!"); return false; } HttpEntity entity = httpResponse.getEntity(); // 获取响应里面的内容 inputStream = entity.getContent(); // 得到服务气端发回的响应的内容(都在一个流里面) // 得到服务气端发回的响应的内容(都在一个字符串里面) // String strResult = EntityUtils.toString(entity); } catch (Exception e) { System.out.println("这是异常!"); } HttpURLConnection: 在 JDK 的 java.net 包中已经提供了访问 HTTP 协议的基本功能:HttpURLConnection。HttpURLConnection继承自URLConnection. HttpURLconnection默认带GZIP压缩。 示例: String validateURL="http://10.0.2.2:8080/testhttp1/TestServlet?name=yang&pwd=123123"; try { URL url = new URL(validateUrl); //创建URL对象 //返回一个URLConnection对象,它表示到URL所引用的远程对象的连接 HttpURLConnection conn = (HttpURLConnection) url.openConnection(); conn.setConnectTimeout(5000); //设置连接超时为5秒 conn.setRequestMethod("GET"); //设定请求方式 conn.connect(); //建立到远程对象的实际连接 //返回打开连接读取的输入流 DataInputStream dis = new DataInputStream(conn.getInputStream()); //判断是否正常响应数据 if (conn.getResponseCode() != HttpURLConnection.HTTP_OK) { System.out.println("网络错误异常!!!!"); return false; } } catch (Exception e) { e.printStackTrace(); System.out.println("这是异常!"); } finally { if (conn != null) { conn.disconnect(); //中断连接 } } 区别: 功能用法 1、从功能上对比,HttpClient库要丰富很多,提供了很多工具,封装了http的请求头,参数,内容体,响应,还有一些高级功能,代理、COOKIE、鉴权、压缩、连接池的处理。 2、HttpClient高级功能代码写起来比较复杂,对开发人员的要求会高一些,而HttpURLConnection对大部分工作进行了包装,屏蔽了不需要的细节,适合开发人员直接调用。 3、HttpURLConnection在2.3版本增加了一些HTTPS方面的改进,4.0版本增加一些响应的缓存。 性能 1、HttpUrlConnection直接支持GZIP压缩;HttpClient也支持,但要自己写代码处理。 2、HttpUrlConnection直接支持系统级连接池,即打开的连接不会直接关闭,在一段时间内所有程序可共用;HttpClient当然也能做到,但毕竟不如官方直接系统底层支持好。 3、HttpUrlConnection直接在系统层面做了缓存策略处理(4.0版本以上),加快了重复请求的速度。 4、关于速度方面,网上有些大牛做过测试,但因访问站点的数据量,二次连接访问等发现测试结果并不统一,故不做详述。大体来说相差不是很大。 选用 1、如果一个Android应用需要向指定页面发送请求,但该页面并不是一个简单的页面,只有当用户已经登录,而且登录用户的用户名有效时才可访问该页面。如果使用HttpURLConnection来访问这个被保护的页面,那么需要处理的细节就太复杂了。可使用HttpClient来登录系统,只要应用程序使用同一个HttpClient发送请求,HttpClient会自动维护与服务器之间的Session状态,也就是说程序第一次使用HttpClient登录系统后,接下来使用HttpClient即可访问被保护页而了。这种情况建议使用HttpClient。 2、Android2.3及以上版本建议选用HttpURLConnection,2.2及以下版本建议选用HttpClient,因为貌似2.2下有些小bug,不知现在修复好没有,但是目前4.0以上版本覆盖率达89%了,这点应该问题不大。而且api体积小使用更简单,内存处理方面更适合移动设备,官方也更支持HttpURLClient,想必后续官方会更完善这个,新手或者新的应用都建议使用HttpURLConnection。 博主初学,此处只是学习笔记以作汇总学习。参考博文,详情请戳: http://blog.csdn.net/imzoer/article/details/9447985 http://blog.csdn.net/huzgd/article/details/8712187 http://blog.csdn.net/wangpeng047/article/details/19624529 转自:链接 本文转自SharkBin博客园博客,原文链接:http://www.cnblogs.com/SharkBin/p/4889606.html,如需转载请自行联系原作者