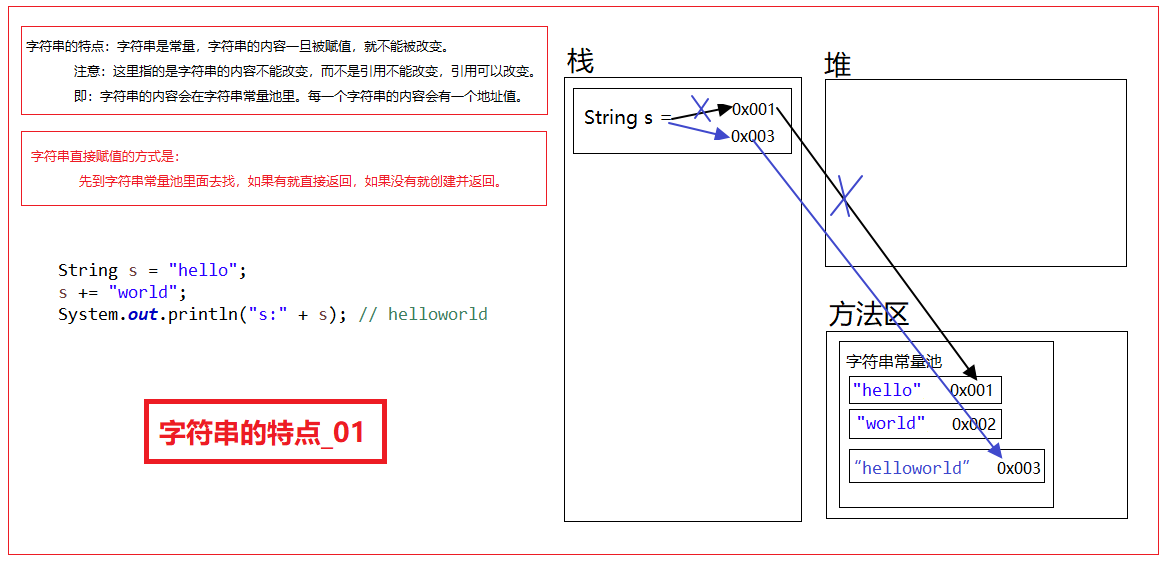
《微软-统一沟通-UC 2013》-1-部署-基础架构-1-install AD DS
《微软-统一沟通-UC 2013》 实验环境-产品: 1. Windows Server 2012 2. Sql Server 2012 3. Office Web Apps Server 2013 4. Exchange Server 2013 5. SharePoint Server 2013 6. Lync Server 2013 7. Forefront Threat Management Gateway 2010 *************** 只有你想不到的! 没有你做不到的! *************** Installing AD DS by using Server Manager AD DS can be installed in Windows Server 2012 by using the Add Roles Wizard in Server Manager, followed by the Active Directory Domain Services Configuration Wizard, which is new beginning in Windows Server 2012. The Active Directory Domain Services Installation Wizard (dcpromo.exe) is deprecated beginning in Windows Server 2012. The following sections explain how to create server pools in order to install and manage AD DS on multiple servers, and how to use the wizards to install AD DS. Creating server pools Server Manager can pool other servers on the network as long as they are accessible from the computer running Server Manager. Once pooled, you choose those servers for remote installation of AD DS or any other configuration options possible within Server Manager. The computer running Server Manager automatically pools itself. For more information about server pools, see Add Servers to Server Manager . Note In order to manage a domain-joined computer using Server Manager on a workgroup server, or vice-versa, additional configuration steps are needed. For more information, see “Add and manage servers in workgroups” in Add Servers to Server Manager . Installing AD DS Administrative credentials The credential requirements to install AD DS vary depending on which deployment configuration you choose. For more information, see Credential requirements to run Adprep.exe and install Active Directory Domain Services . Use the following procedures to install AD DS using the GUI method. The steps can be performed locally or remotely. For more detailed explanation of these steps, see the following topics: Deploying a Forest with Server Manager Install a Replica Windows Server 2012 Domain Controller in an Existing Domain (Level 200) Install a New Windows Server 2012 Active Directory Child or Tree Domain (Level 200) Install a Windows Server 2012 Active Directory Read-Only Domain Controller (RODC) (Level 200) To install AD DS by using Server Manager 1. In Server Manager, clickManageand clickAdd Roles and Featuresto start the Add Roles Wizard. 2. On theBefore you beginpage, clickNext. 3. On theSelect installation typepage, clickRole-based or feature-based installationand then clickNext. 4. On theSelect destination serverpage, clickSelect a server from the server pool, click the name of the server where you want to install AD DS and then clickNext. To select remote servers, first create a server pool and add the remote servers to it. For more information about creating server pools, see Add Servers to Server Manager . 5. On theSelect server rolespage, clickActive Directory Domain Services, then on theAdd Roles and Features Wizarddialog box, clickAdd Features, and then clickNext. 6. On theSelect featurespage, select any additional features you want to install and clickNext. 7. On theActive Directory Domain Servicespage, review the information and then clickNext. 8. On theConfirm installation selectionspage, clickInstall. 9. On theResultspage, verify that the installation succeeded, and clickPromote this server to a domain controllerto start the Active Directory Domain Services Configuration Wizard. Important If you close Add Roles Wizard at this point without starting the Active Directory Domain Services Configuration Wizard, you can restart it by clicking Tasks in Server Manager. 10. On theDeployment Configurationpage, choose one of the following options: o If you are installing an additional domain controller in an existing domain, clickAdd a domain controller to an existing domain, and type the name of the domain (for example, emea.corp.contoso.com) or clickSelect…to choose a domain, and credentials (for example, specify an account that is a member of the Domain Admins group) and then clickNext. Note The name of the domain and current user credentials are supplied by default only if the machine is domain-joined and you are performing a local installation. If you are installing AD DS on a remote server, you need to specify the credentials, by design. If current user credentials are not sufficient to perform the installation, clickChange…in order to specify different credentials. o For more information, see Install a Replica Windows Server 2012 Domain Controller in an Existing Domain (Level 200) . o If you are installing a new child domain, clickAdd a new domain to an existing forest, forSelect domain type, selectChild Domain, type or browse to the name of the parent domain DNS name (for example, corp.contoso.com), type the relative name of the new child domain (for example emea), type credentials to use to create the new domain, and then clickNext. For more information, see Install a New Windows Server 2012 Active Directory Child or Tree Domain (Level 200) . o If you are installing a new domain tree, clickAdd new domain to an existing forest, forSelect domain type, chooseTree Domain, type the name of the root domain (for example, corp.contoso.com), type the DNS name of the new domain (for example, fabrikam.com), type credentials to use to create the new domain, and then clickNext. For more information, see Install a New Windows Server 2012 Active Directory Child or Tree Domain (Level 200) . o If you are installing a new forest, clickAdd a new forestand then type the name of the root domain (for example, corp.contoso.com). For more information, see Install a New Windows Server 2012 Active Directory Forest (Level 200) . 11. On theDomain Controller Optionspage, choose one of the following options: o If you are creating a new forest or domain, select the domain and forest functional levels, clickDomain Name System (DNS) server, specify the DSRM password, and then clickNext. o If you are adding a domain controller to an existing domain, clickDomain Name System (DNS) server,Global Catalog (GC), orRead Only Domain Controller (RODC)as needed, choose the site name, and type the DSRM password and then clickNext. For more information about which options on this page are available or not available under different conditions, see Domain Controller Options . 12. On theDNS Optionspage (which appears only if you install a DNS server), clickUpdate DNS delegationas needed. 13. If you do, provide credentials that have permission to create DNS delegation records in the parent DNS zone. If a DNS server that hosts the parent zone cannot be contacted, theUpdate DNS Delegationoption is not available. For more information about whether you need to update the DNS delegation, see Understanding Zone Delegation . If you attempt to update the DNS delegation and encounter an error, see DNS Options . 14. On theRODC Optionspage (which appears only if you install an RODC), specify the name of a group or user who will manage the RODC, add accounts to or remove accounts from the Allowed or Denied password replication groups, and then clickNext. For more information, see Password Replication Policy . 15. On theAdditional Optionspage, choose one of the following options: o If you are creating a new domain, type a new NetBIOS name or verify the default NetBIOS name of the domain, and then clickNext. o If you are adding a domain controller to an existing domain, select the domain controller that you want to replicate the AD DS installation data from (or allow the wizard to select any domain controller). If you are installing from media, clickInstall from media pathtype and verify the path to the installation source files, and then clickNext. You cannot use install from media (IFM) to install the first domain controller in a domain. IFM does not work across different operating system versions. In other words, in order to install an additional domain controller that runs Windows Server 2012 by using IFM, you must create the backup media on a Windows Server 2012 domain controller. For more information about IFM, see Installing an Additional Domain Controller by Using IFM . 16. On thePathspage, type the locations for the Active Directory database, log files, and SYSVOL folder (or accept default locations), and clickNext. Important Do not store the Active Directory database, log files, or SYSVOL folder on a data volume formatted with Resilient File System (ReFS). 17. On thePreparation Optionspage, type credentials that are sufficient to run adprep. For more information, see Credential requirements to run Adprep.exe and install Active Directory Domain Services . 18. On theReview Optionspage, confirm your selections, clickView scriptif you want to export the settings to a Windows PowerShell script, and then clickNext. 19. On thePrerequisites Checkpage, confirm that prerequisite validation completed and then clickInstall. Automatically Restart OS 20. On theResultspage, verify that the server was successfully configured as a domain controller. The server will be restarted automatically to complete the AD DS installation. 本文转自 CTO_LiuJinFeng 51CTO博客,原文链接:http://blog.51cto.com/dynamic/1155585,如需转载请自行联系原作者