【官方文档】Nginx负载均衡学习笔记(二)负载均衡基本概念介绍
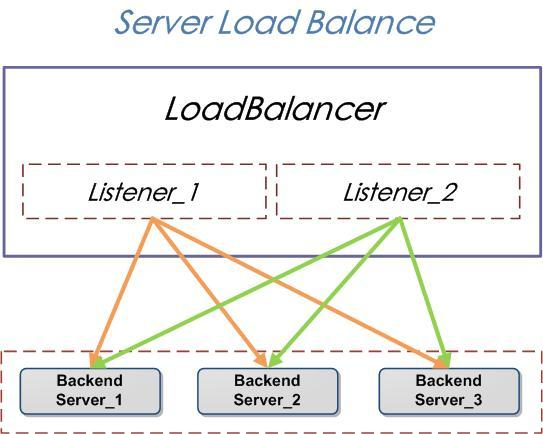
简介 负载均衡(Server Load Balancer)是将访问流量根据转发策略分发到后端多台 ECS 的流量分发控制服务。负载均衡可以通过流量分发扩展应用系统对外的服务能力,通过消除单点故障提升应用系统的可用性。 负载均衡主要有如下几个功能点: 负载均衡服务通过设置虚拟服务地址(IP),将位于同一地域(Region)的多台云服务器(Elastic Compute Service,简称ECS)资源虚拟成一个高性能、高可用的应用服务池;根据应用指定的方式,将来自客户端的网络请求分发到云服务器池中。 负载均衡服务会检查云服务器池中ECS的健康状态,自动隔离异常状态的ECS,从而解决了单台ECS的单点问题,同时提高了应用的整体服务能力。在标准的负载均衡功能之外,负载均衡服务还具备TCP与HTTP抗DDoS攻击的特性,增强了应用服务器的防护能力。 负载均衡服务是ECS面向多机方案的一个配套服务,需要同ECS结合使用。 核心概念 负载均衡服务主要有三个核心概念: LoadBalancer:负载均衡实例。 Listener:用户定制的监听器,定义了负载均衡策略和转发规则。 BackendServer:后端的一组ECS(云服务器)。 下图描述了负载均衡服务的核心概念。来自外部的访问请求,由负载均衡实例根据相关的策略和转发规则分发到后端ECS进行处理。 协议支持 当前提供4层(TCP协议和UDP协议)和7层(HTTP和HTTPS协议)的负载均衡服务。 健康检查 支持对后端ECS进行健康检查,自动屏蔽异常状态的ECS,待该ECS恢复正常后自动解除屏蔽。 会话保持 提供会话保持功能,在Session的生命周期内,可以将同一客户端的请求转发到同一台后端ECS上。 调度算法 支持加权轮询(WRR),加权最小连接数(WLC),和轮询3种调度算法。 加权轮询:根据服务器的处理能力为后端 ECS 分配不同的权值,将外部请求依序分发到后端ECS上,后端ECS权重越高被分发的几率也越大。 加权最小连接数:根据服务器的处理能力为后端 ECS 分配不同的权值,将外部请求分发到当前连接数最小的后端ECS上,后端ECS权重越高被分发的几率也越大。 轮询:将外部请求依序分发到后端ECS上。 域名URL转发 针对七层协议(HTTP协议和HTTPS协议),支持按用户访问的域名和URL来转发流量到不同的虚拟服务器组。 访问控制 支持白名单控制,通过设置负载均衡监听,仅允许特定IP访问,适用于用户的应用只允许特定IP访问的场景。(只能通过Lua) 使用场景 负载均衡主要可以应用于以下场景中: 灵活的进行流量分发,适用于具有高访问量的业务。 横向扩展应用系统的服务能力,适用于各种 web server 和 app server。 消除应用系统的单点故障,当其中一部分 ECS 发生故障后,应用系统仍能正常工作。 提高应用系统容灾能力,多可用区部署,机房发生故障后,仍能正常工作。 https://help.aliyun.com/document_detail/27541.html?spm=5176.doc27543.6.544.5RC2R1 术语表 中文 英文 说明 负载均衡服务 Server Load Balancer 阿里云计算提供的一种网络负载均衡服务,可以结合阿里云提供的 ECS 服务为用户提供基于 ECS 实例的 TCP 与 HTTP 负载均衡服务。 负载均衡实例 Load Balancer 负载均衡实例可以理解为负载均衡服务的一个运行实例,用户要使用负载均衡服务,就必须先创建一个负载均衡实例,LoadBalancerId 是识别用户负载均衡实例的唯一标识。 负载均衡服务监听 Listener 负载均衡服务监听,包括监听端口、负载均衡策略和健康检查配置等,每个监听对应后端的一个应用服务。 后端服务器 Backend Server 接受负载均衡分发请求的一组ECS,负载均衡服务将外部的访问请求按照用户设定的规则转发到这一组后端 ECS上进行处理。 服务地址 Address 系统分配的服务地址,当前为IP地址。用户可以选择该服务地址是否对外公开,来分别创建公网和私网类型的负载均衡服务。 证书 Certificate 用于 HTTPS 协议。用户将证书上传到负载均衡中,在创建 HTTPS 协议监听的时候绑定证书,提供 HTTPS 服务。 主可用区 Master Availability Zone 负载均衡会在某些地域的多个可用区进行部署,用户可指定主备可用区创建负载均衡实例,该实例将默认工作在主可用区。 备可用区 Slave Availability Zone 负载均衡会在某些地域的多个可用区进行部署,用户可指定主备可用区创建负载均衡实例,当主可用区发生故障时,该实例可切换到备可用区工作。