让我们逐一来进行分析。
收集图像
首先,我需要收集大量的图像来进行学习。 作为一种收集方法,我使用了以下资源:
•Google图片搜索
•Facebook上的图像收集
•拍摄视频
最初,我用网上搜索和Facebook收集图像,但并没有收集到足够多的图像。 所以,我使用摄像机拍摄视频,并将视频分解出大量的图像。
预处理图像
现在我有了足够多的面部图像,但学习模型不能直接对他们进行学习。这是因为图像中有大量与面部无关的信息。所以我需要先对图像进行脸部剪切。
我主要使用ImageMagick来进行脸部提取。 通过使用ImageMagick我们可以提取图像中的面部部分。
ImageMagick
我收集到的大量面部图像如下:
![25c5114417eb690dcbdfabb6de5623defc74e8d6]()
也许我是这个世界上有我老板面部照片最多的人了,比他父母还多。
现在已经准备好进行机器学习了。
构建机器学习模型
Keras用于建立已经经过学习的卷积神经网络(CNN)。 TensorFlow用于Keras的后端。 如果你只识别面部,那就可以直接调用Web API进行图像识别,例如Cognitive Services中的Computer Vision API。但是这次我决定自己来实现这部分,因为考虑到系统的实时性。
网络具有以下架构。 使用Keras是非常方便的,因为它可以轻松地输出架构。
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
convolution2d_1 (Convolution2D) (None, 32, 64, 64) 896 convolution2d_input_1[0][0]
____________________________________________________________________________________________________
activation_1 (Activation) (None, 32, 64, 64) 0 convolution2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_2 (Convolution2D) (None, 32, 62, 62) 9248 activation_1[0][0]
____________________________________________________________________________________________________
activation_2 (Activation) (None, 32, 62, 62) 0 convolution2d_2[0][0]
____________________________________________________________________________________________________
maxpooling2d_1 (MaxPooling2D) (None, 32, 31, 31) 0 activation_2[0][0]
____________________________________________________________________________________________________
dropout_1 (Dropout) (None, 32, 31, 31) 0 maxpooling2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_3 (Convolution2D) (None, 64, 31, 31) 18496 dropout_1[0][0]
____________________________________________________________________________________________________
activation_3 (Activation) (None, 64, 31, 31) 0 convolution2d_3[0][0]
____________________________________________________________________________________________________
convolution2d_4 (Convolution2D) (None, 64, 29, 29) 36928 activation_3[0][0]
____________________________________________________________________________________________________
activation_4 (Activation) (None, 64, 29, 29) 0 convolution2d_4[0][0]
____________________________________________________________________________________________________
maxpooling2d_2 (MaxPooling2D) (None, 64, 14, 14) 0 activation_4[0][0]
____________________________________________________________________________________________________
dropout_2 (Dropout) (None, 64, 14, 14) 0 maxpooling2d_2[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 12544) 0 dropout_2[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 512) 6423040 flatten_1[0][0]
____________________________________________________________________________________________________
activation_5 (Activation) (None, 512) 0 dense_1[0][0]
____________________________________________________________________________________________________
dropout_3 (Dropout) (None, 512) 0 activation_5[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 2) 1026 dropout_3[0][0]
____________________________________________________________________________________________________
activation_6 (Activation) (None, 2) 0 dense_2[0][0]
====================================================================================================
Total params: 6489634
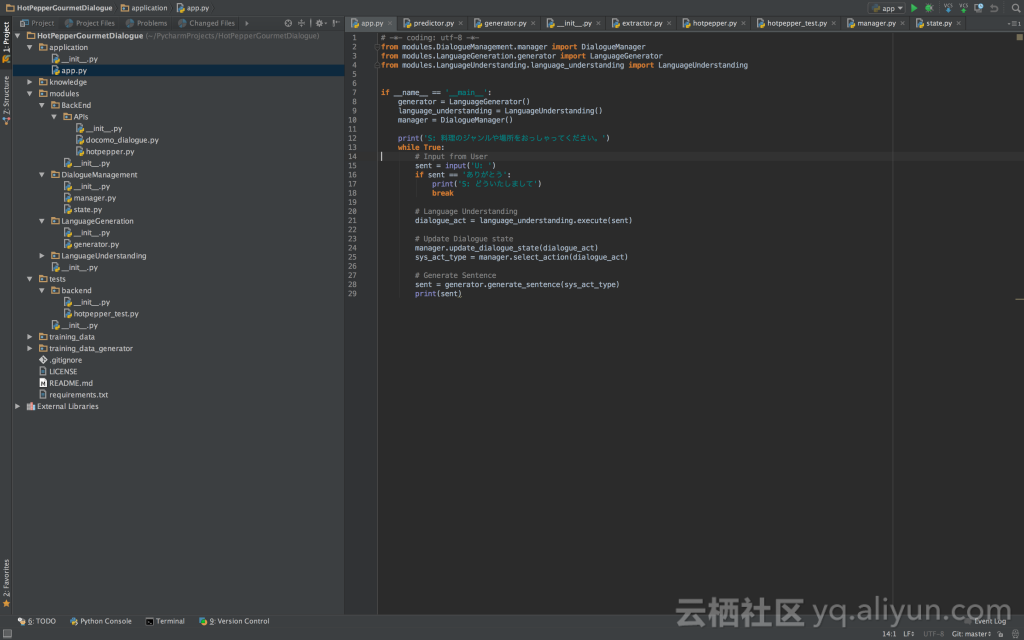
代码如下:
BossSensor/boss_train.py
至此,系统可以识别出老板的面部了。
切换屏幕
现在,当学习模型识别老板的脸,我需要切换屏幕。 在这个时候,让我们显示准备好的截屏来假装工作。
我是一个程序员,所以我准备了下面的图像。
![cfdacf73fd5040a73ae348ef8117abd43da3eacb]()
我只显示这张图片。
由于我想以全屏显示图像,所以使用了PyQt。 下面是代码:
BossSensor/image_show.py
现在,一切都准备就绪。
完成的产品
一旦我们整合所有运用到的技术,我们就大功告成了。
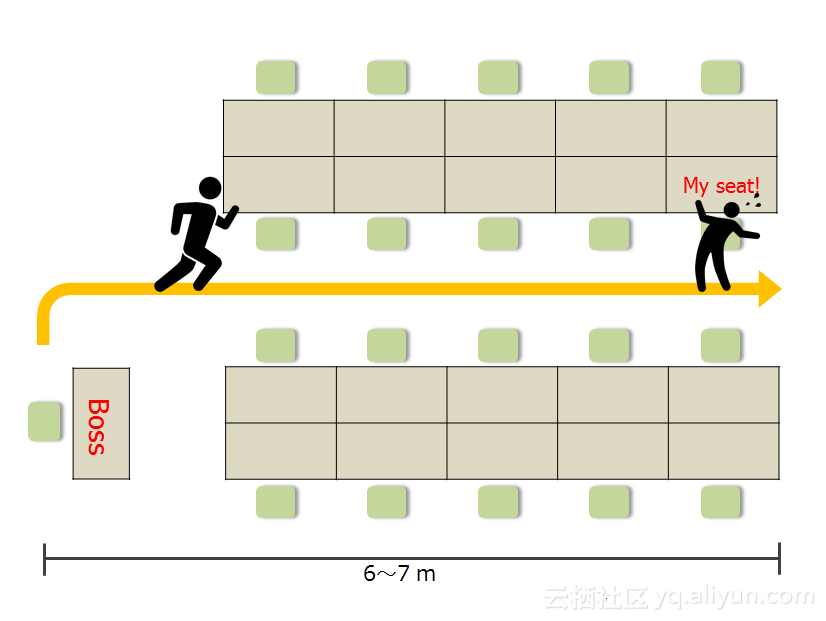
“我的老板离开了他的座位,他正在接近我的座位”
![15825ba0de1c2033f30110f1c63058a3a22b862e]()
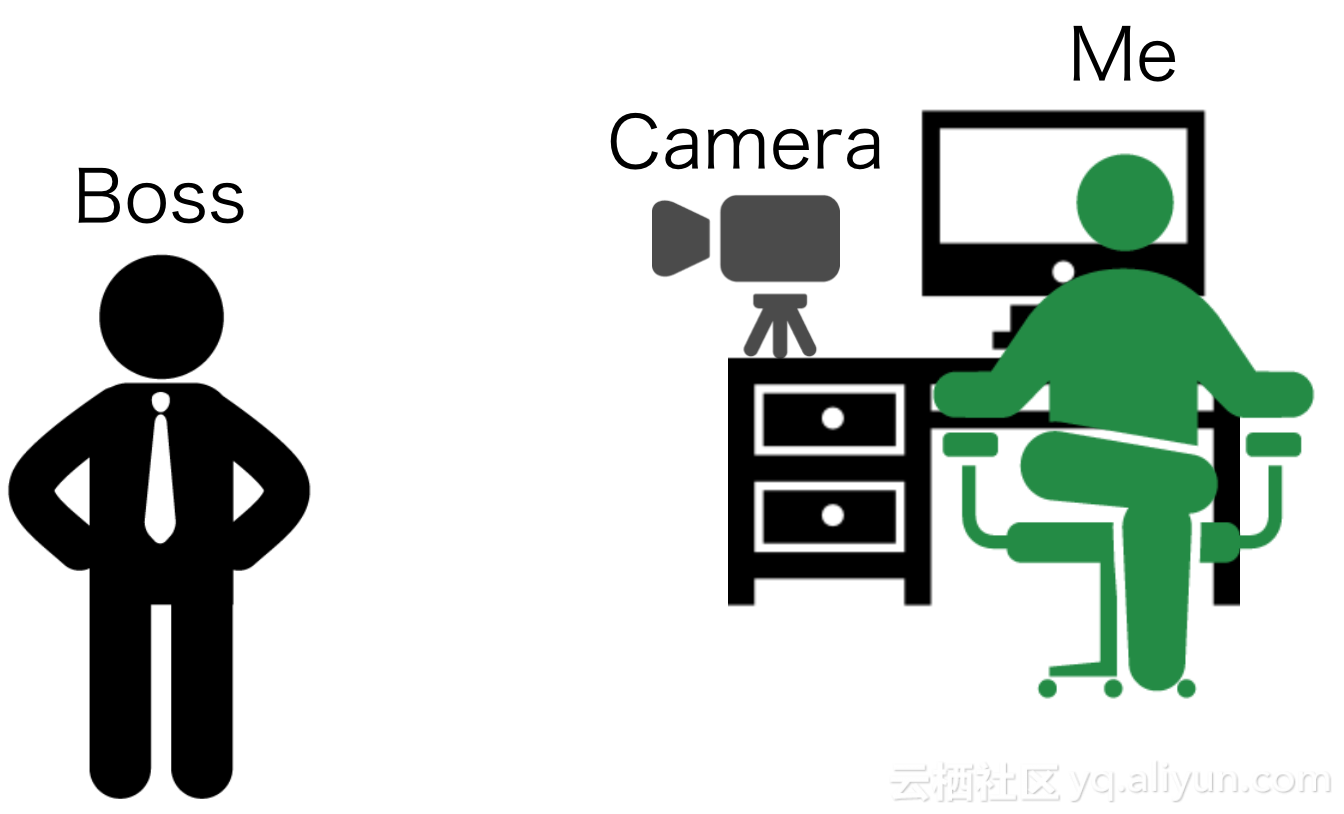
“OpenCV已经检测到面部并将图像输入到学习模型中。”
![def987da509748976e78c12be4185e72a394d349]()
快切屏!
![40d2742ae32f087e7a669f63d53c621c4deee0ea]()
源代码
你可以从以下链接下载Boss Sensor:
BossSensor
结论
我结合了从Web相机的实时图像采集和面部识别使用Keras来识别我的老板和切换屏幕。目前,我用OpenCV来检测面部,但由于OpenCV中的面部检测的准确性似乎不太好,我想尝试使用Dlib来提高准确性。 另外,我还想试验一下我自己的面部检测模型。最后,由于从网络摄像机获取的图像的识别精度不太好,我还想改进这个方面。
数十款阿里云产品限时折扣中,赶紧点击领劵开始云上实践吧!
文章原标题《Deep Learning Enables You to Hide Screen when Your Boss is Approaching》,作者:HIRONSAN,译者:friday012
文章为简译,更为详细的内容,请查看原文