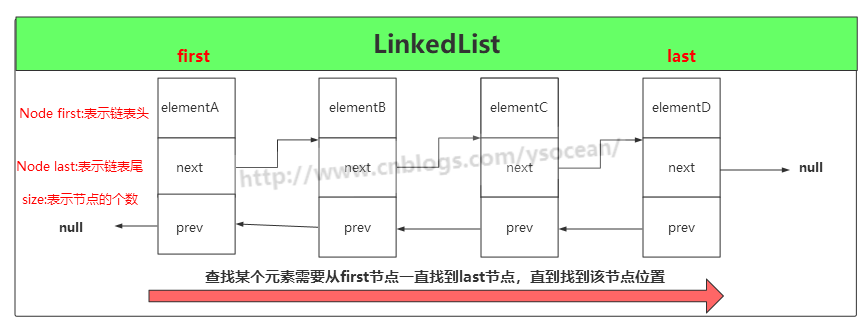
Java性能调优工具之JDK命令行
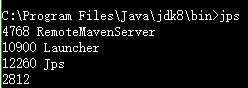
1.1 jps 类似Linux的ps,但是jps只用于列出Java的进程 可以方便查看Java进程的启动类,传入参数和JVM参数等 直接运行,不加参数,列出Java程序的进程ID以及Main函数等名称 jps命令本质也是Java程序 -m 输出传递给Java进程的参数 -l 输出主函数的完整路径 -q 只输出进程ID -v 显示传递给jvm的参数 1.2 jstat 用于观察Java应用程序运行时信息的工具,详细查看堆使用情况以及GC情况 image.png jstat -class pid:显示加载class的数量,及所占空间等信息。 -compiler -t:显示JIT编译的信息 -gc pid:可以显示gc的信息,查看gc的次数,及时间。其中最后五项,分别是young gc的次数,young gc的时间,full gc的次数,full gc的时间,gc的总时间。 -gccapacity比-gc多了各个代的最大值和最小值 -gccause 4768 最近一次GC统计和原因 LGCC:上次GC原因 GCC:当前GC原因 -gcnew pid:new对象的信息。 jstat -gcnewcapacity pid:new对象的信息及其占用量。 -gcold 显示老年代和永久代信息 -gcoldcapacity展现老年代的容量信息 image.png -gcutil显示GC回收相关信息 jstat -printcompilation pid:当前VM执行的信息。 还可以同时加两个数 输出进程4798的ClassLoader信息,每1秒统计一次,共输出2次 1.3 jinfo 查看正在运行的Java应用程序的扩展参数,甚至在运行时修改部分参数jinfo <option> <pid> jinfo可以查看运行时参数: jinfo -flag MaxTenuringThreshold 31518 -XX:MaxTenuringThreshold=15 jinfo还可以在运行时修改参数值: > jinfo -flag PrintGCDetails 31518 -XX:-PrintGCDetails > jinfo -flag +PrintGCDetails 31518 > jinfo -flag PrintGCDetails 31518 -XX:+PrintGCDetails 1.4 jmap 生成堆快照和对象的统计信息 -histo 打印每个class的实例数目,内存占用,类全名信息. VM的内部类名字开头会加上前缀”*”. 如果live子参数加上后,只统计活的对象数量. -dump:[live,]format=b,file=<filename> 使用hprof二进制形式,输出jvm的heap内容到文件=. live子选项是可选的,假如指定live选项,那么只输出活的对象到文件. 获得堆快照文件之后,我们可以使用多种工具对文件进行分析,例如jhat,visual vm等。 1.5 jhat 分析Java应用程序的堆快照文件,以前面生成的为例 jhat heap.hprof jhat在分析完成之后,使用HTTP服务器展示其分析结果,在浏览器中访问 http://127.0.0.1:7000/即可得到分析结果。 1.6b jstack 导出Java应用程序的线程堆栈jstack -l <pid> jstack可以检测死锁,下例通过一个简单例子演示jstack检测死锁的功能。java代码如下: 使用jps命令查看进程号为11468,然后使用jstack -l 11468 > a.txt命令把堆栈信息打印到文件中 从这个输出可以知道: 1、在输出的最后一段,有明确的"Found one Java-level deadlock"输出,所以通过jstack命令我们可以检测死锁 2、输出中包含了所有线程,除了我们的north,sorth线程外,还有"Attach Listener", "C2 CompilerThread0", "C2 CompilerThread1"等等; 3、每个线程下面都会输出当前状态,以及这个线程当前持有锁以及等待锁,当持有与等待造成循环等待时,将导致死锁