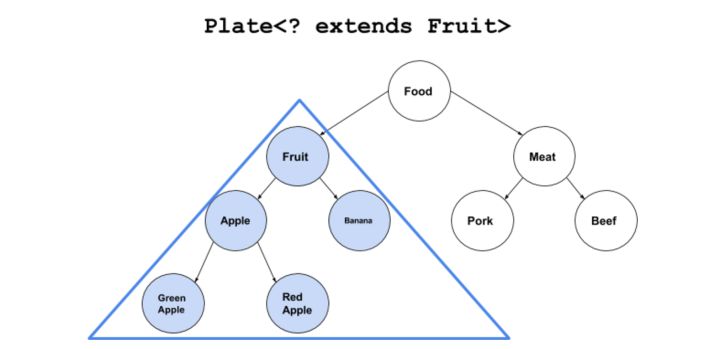
德哥PG系列课程直播(第15讲):PostgreSQL 新类型提高开发生产力
直播回顾 地址:https://yq.aliyun.com/live/909 知识点 知识点:JSON, ARRAY, RANGE 学习资料 1、PostgreSQL 店铺运营实践 - JSON[]数组 内部标签数据等值、范围检索100倍+加速示例 (含,单值+多值列合成) https://yq.aliyun.com/articles/501431标签:PostgreSQL , json , 数组 , 多值 , 等值 , 多值 , 一棵树 , 多颗树 , gin , btree , gist 2、PostgreSQL UDF实现tsvector(全文检索), array(数组)多值字段与scalar(单值字段)类型的整合索引(类分区索引) - 单值与多值类型复合查询性能提速100倍+ 案例 (含,单值+多值列合成)标签:PostgreSQL , 单值列 , 多值列 , GIN倒排索引 , 多值列变异 , 分区索引 , 分区表 , 变异索引 3、PostgreSQL 多重含义数组检索与条件过滤 (标签1:属性, 标签n:属性) - 包括UPSERT操作如何修改数组、追加数组元素标签:PostgreSQL , 多重函数数组 , UDF索引 , 过滤 , 文本处理 4、会议室预定系统实践(轻松解放开发) - PostgreSQL tsrange(时间范围类型) + 排他约束标签:PostgreSQL , tsrange , 范围 , exclude using , 排他约束 , btree_gist , 会议室预定 , 时间重叠 , 空间重叠 5、聊聊between and的坑 和 神奇的解法标签:PostgreSQL , 物联网 , 智能DNS , range , iprange , intrange , 排他约束 , GiST索引 往期回顾 PostgreSQL多场景阿里云沙箱实验(第14讲):PostgreSQL 数据清洗、采样、脱敏、批处理、合并 https://yq.aliyun.com/live/885PostgreSQL多场景阿里云沙箱实验(第13讲):PostgreSQL 图式关系数据应用实践 https://yq.aliyun.com/live/869PostgreSQL多场景阿里云沙箱实验(第12讲):PostgreSQL 物联网最佳实践https://yq.aliyun.com/live/846PostgreSQL多场景阿里云沙箱实验(第11讲):PostgreSQL 在社交应用领域的最佳实践 https://yq.aliyun.com/live/824PostgreSQL多场景阿里云沙箱实验(第10讲):PostgreSQL 时空调度数据库实践 https://yq.aliyun.com/live/807PostgreSQL多场景阿里云沙箱实验(第9讲):PostgreSQL 时空业务实践 https://yq.aliyun.com/live/794PostgreSQL多场景阿里云沙箱实验(第8讲):PostgreSQL 简单空间应用实践 https://yq.aliyun.com/live/783PostgreSQL多场景阿里云沙箱实验(第7讲):PostgreSQL 并行计算 https://yq.aliyun.com/live/733PostgreSQL多场景阿里云沙箱实验(第6讲):PostgreSQL 用户画像系统实践 https://yq.aliyun.com/live/710PostgreSQL多场景阿里云沙箱实验(第5讲):PostgreSQL 估值、概率计算 https://yq.aliyun.com/live/691PostgreSQL多场景阿里云沙箱实验(第4讲):PostgreSQL 实时多维分析 https://yq.aliyun.com/live/659PostgreSQL多场景阿里云沙箱实验(第3讲):PostgreSQL 实时搜索实践https://yq.aliyun.com/live/647PostgreSQL多场景阿里云沙箱实验(第2讲):PG秒杀场景实践https://yq.aliyun.com/live/615PostgreSQL多场景阿里云沙箱实验(第1讲):如何快速构建海量逼真测试数据https://yq.aliyun.com/live/594 主讲人 德哥(云栖社区昵称:德哥)阿里云数据库专家,PostgreSQL中国社区校长。 格言:公益是一辈子的事, I'm digoal, just do it. 专家已经在社区发布了1946篇技术博文,很快将突破2000篇。厉害了!想要成为德哥粉丝请直接点击这里。 直播时间 时间:2019年3月6日 19:30 直播地址 PostgreSQL技术进阶群,钉钉扫码入群看直播