面试系列六 之 用户行为数据分析
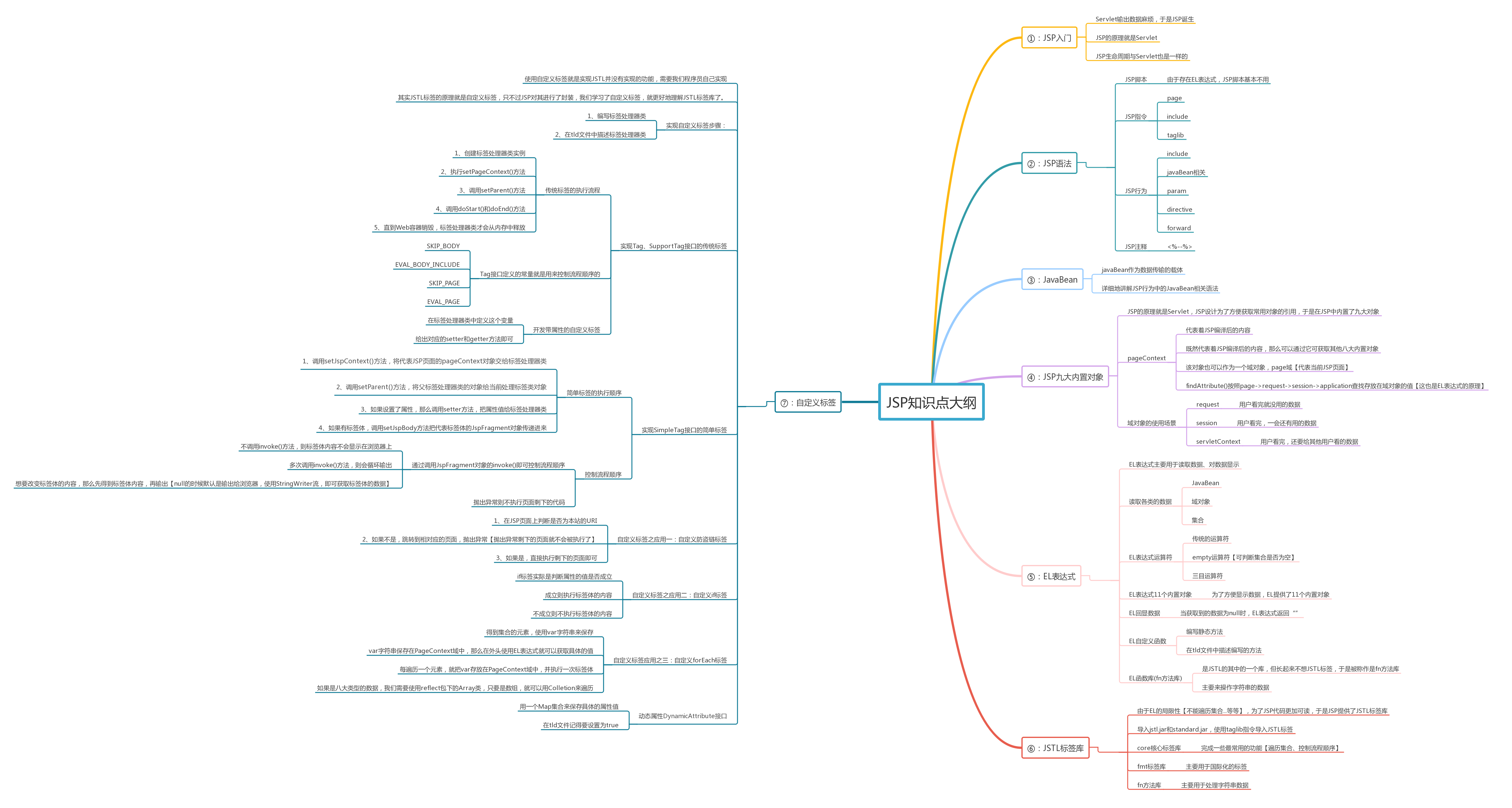
# 关注我的公众号【宝哥大数据】,更多干货等着你  ## 1.1、数仓分层架构  **分层优点:复杂问题简单化、清晰数据结构(方便管理)、增加数据的复用性、隔离原始数据(解耦)** 层级 | 功能 ---|--- ods | 原始数据层 存放原始数据,保持原貌不做处理 dwd | 明细数据层 对ods层数据清洗(去除空值,脏数据,超过极限范围的数据) dws | 服务数据层 轻度聚合 ads | 应用数据层 具体需求 数仓中各层建的表都是外部表 ## 1.2、埋点行为数据基本格式(基本字段) 公共字段:基本所有安卓手机都包含的字段 业务字段:埋点上报的字段,有具体的业务类型 下面就是一个示例,表示业务字段的上传。 行为数据启动日志/事件日志表关键字段: ```json { "ap":"xxxxx",//项目数据来源 app pc "cm": { //公共字段 "mid": "", // (String) 设备唯一标识 "uid": "", // (String) 用户标识 "vc": "1", // (String) versionCode,程序版本号 "vn": "1.0", // (String) versionName,程序版本名 "l": "zh", // (String) 系统语言 "sr": "", // (String) 渠道号,应用从哪个渠道来的。 "os": "7.1.1", // (String) Android系统版本 "ar": "CN", // (String) 区域 "md": "BBB100-1", // (String) 手机型号 "ba": "blackberry", // (String) 手机品牌 "sv": "V2.2.1", // (String) sdkVersion "g": "", // (String) gmail "hw": "1620x1080", // (String) heightXwidth,屏幕宽高 "t": "1506047606608", // (String) 客户端日志产生时的时间 "nw": "WIFI", // (String) 网络模式 "ln": 0, // (double) lng经度 "la": 0 // (double) lat 纬度 }, "et": [ //事件 { "ett": "1506047605364", //客户端事件产生时间 "en": "display", //事件名称 启动和事件日志是根据事件名称的不同 "kv": { //事件结果,以key-value形式自行定义 "goodsid": "236", "action": "1", "extend1": "1", "place": "2", "category": "75" } } ] } ``` 根据事件标签的不同可以分成不同的日志表 ## 1.3、各个层的表介绍 ### 1.3.1、ods层 1)ods_start_log 启动日志表 - 只有一个字段 line(保存着json),按照日期dt分区,表的格式:lzo 2)ods_event_log 事件日志表(格式同启动日志表) - 只有一个字段 line ,按照日期dt 分区,表的格式:lzo ### 1.3.2、dwd层 1)dwd_start_log 启动表 - 关键字段:mid_id,user_id,dt(分区字段,按照日期分区) (其实这是启动表和事件表的公共字段) - 从ods_start_log中的line用`get_json_object(line,'$.mid') mid_id`的方式获取字段 #### 1.3.2.1、自定义UDF/UDTF(项目中的应用) - 自定义UDF函数(解析公共字段,一进一出) - 自定义UDTF函数(解析具体事件字段,一进多出) - 自定义UDF:继承UDF,重写evaluate方法 - 自定义UDTF:继承自GenericUDTF,重写3个方法:initialize(自定义输出的列名和类型),process(将结果返回forward(result)),close - 为什么要自定义UDF/UDTF,因为自定义函数,可以自己埋点Log打印日志,出错或者数据异常,方便调试。 #### 1.3.2.2、事件日志基础明细表 dwd_base_event_log 事件日志基础明细表 - 1)关键字段: - 公共字段:mid_id,user_id,dt(分区字段)以及event_name、event_json、server_time - 2)从 ods_event_log的line 中用 UDF 获取 公共字段 和 server_time,用UDTF 获取 event_name , event_json。 #### 1.3.2.3、商品点击表 dwd_display_log 商品点击表 - 关键字段:公共字段 + 特有字段 - 从dwd_base_event_log中直接获取公共字段和server_time,从 dwd_base_event_log的 event_json中获取特有字段,`where event_name = "display"` - `get_json_object(event_json,'$.kv.action') action` #### 1.3.2.4、其他的具体事件明细表 类似 表明|表注释 --|-- dwd_newsdetail_log | 商品详情页表 dwd_loading_log |商品列表页表 dwd_ad_log| 广告表 dwd_notification_log |消息通知表 dwd_active_foreground_log |用户前台活跃表 dwd_active_background_log |用户后台活跃表 dwd_comment_log |评论表 dwd_favorites_log| 收藏表 dwd_praise_log |点赞表 dwd_error_log |错误日志表 从一张事件基础明细表dwd_base_event_log一共可以获得11张具体事件明细表 # 二、需求解析 ## 2.1、用户活跃主题 ### 2.1.1、DWS层日活明细表 每日活跃设备分析  ### 2.1.2、DWS层周活明细表 每周活跃设备分析  ### 2.1.3、DWS层月活明细表 每月活跃设备分析  ### 2.1.4、ADS层日周月活跃设备数表 活跃设备分析  ## 2.2、用户新增主题 ### 2.2.1、DWS层日新增明细表  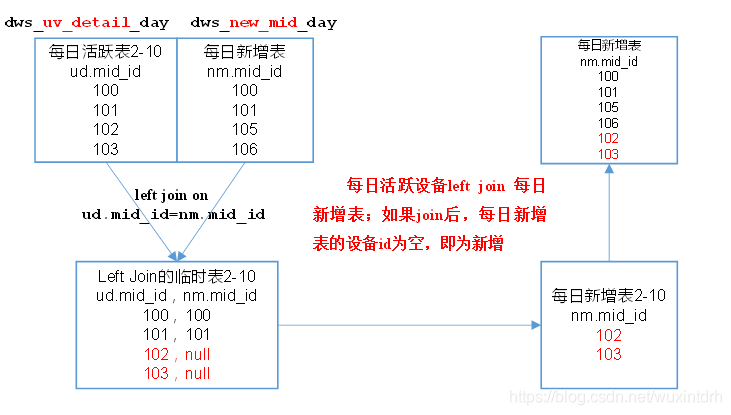 ### 2.2.2、ADS层每日新增设备数表  ## 2.3、用户留存主题 ### 2.3.1、用户留存介绍  ### 2.3.2、用户留存率分析 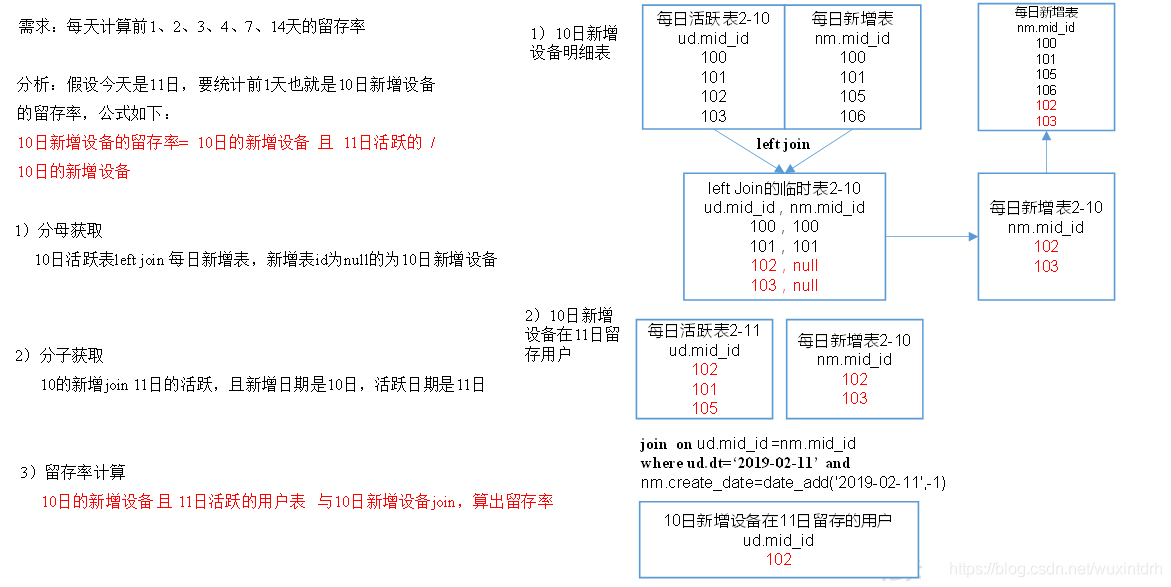 ### 2.3.3、DWS层日留存明细表  ### 2.3.4、ADS层留存用户数表 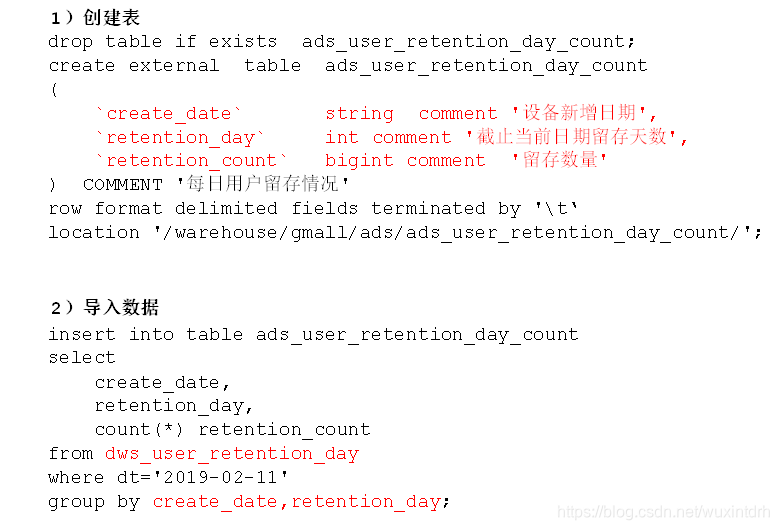 ### 2.3.5、ADS层留存用户率表  ## 2.4、沉默用户  ## 2.5、本周回流用户数  ## 2.6、流失用户数 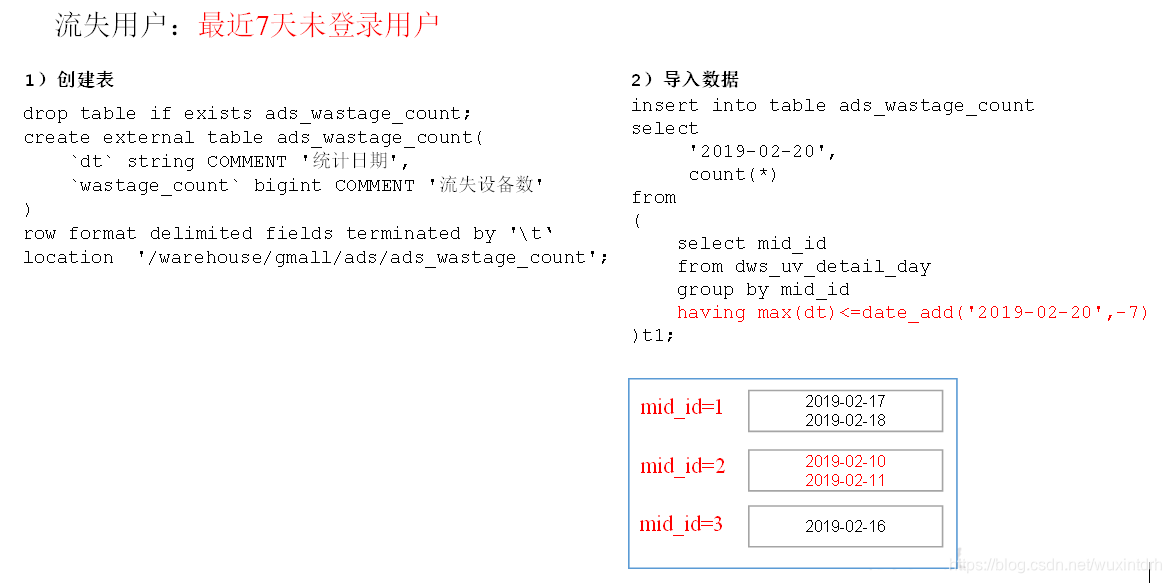 ## 2.7、最近连续3周活跃用户数  ## 2.8、最近七天内连续三天活跃用户数  ## 2.9、需求逻辑 ### 2.9.1 如何分析用户活跃? 在启动日志中统计不同设备id出现次数。 ### 2.9.2 如何分析用户新增? 用活跃用户表 left join 用户新增表,用户新增表中mid为空的即为用户新增。 ### 2.9.3 如何分析用户1天留存? 留存用户=前一天新增 join 今天活跃 用户留存率=留存用户/前一天新增 ### 2.9.4 如何分析沉默用户? (登录时间为7天前,且只出现过一次) 按照设备id对日活表分组,登录次数为1,且是在一周前登录。 ### 2.9.5 如何分析本周回流用户? 本周活跃left join本周新增 left join上周活跃,且本周新增id和上周活跃id都为null ### 2.9.6 如何分析流失用户? (登录时间为7天前) 按照设备id对日活表分组,且七天内没有登录过。 ### 2.9.7 如何分析最近连续3周活跃用户数? 按照设备id对周活进行分组,统计次数大于3次。 ### 2.9.8 如何分析最近七天内连续三天活跃用户数? - 1)查询出最近7天的活跃用户,并对用户活跃日期进行排名 - 2)计算用户活跃日期及排名之间的差值 - 3)对同用户及差值分组,统计差值个数 - 4)将差值相同个数大于等于3的数据取出,然后去重(去的是什么重???),即为连续3天及以上活跃的用户