面试系列七 之 业务交互数据分析
## 6.1 电商常识 `SKU`:一台银色、128G内存的、支持联通网络的iPhoneX `SPU`:iPhoneX `Tm_id`:品牌Id苹果,包括IPHONE,耳机,mac等 ## 6.2 电商业务流程 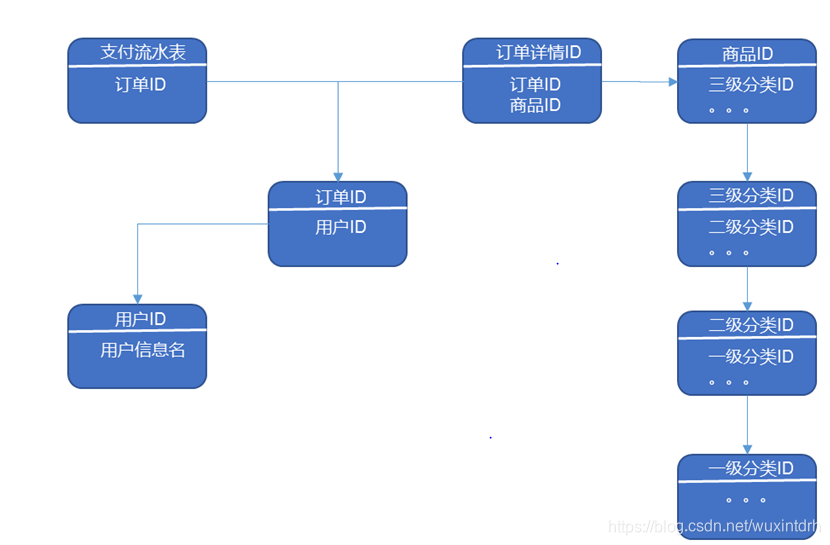 ## 6.3 业务表关键字段 ### 6.3.1 订单表(order_info) 标签 |含义 ---|-- id |订单编号 total_amount |订单金额 order_status |订单状态 user_id |用户id payment_way| 支付方式 out_trade_no |支付流水号 create_time |创建时间 operate_time |操作时间 ### 6.3.2 订单详情表(order_detail) 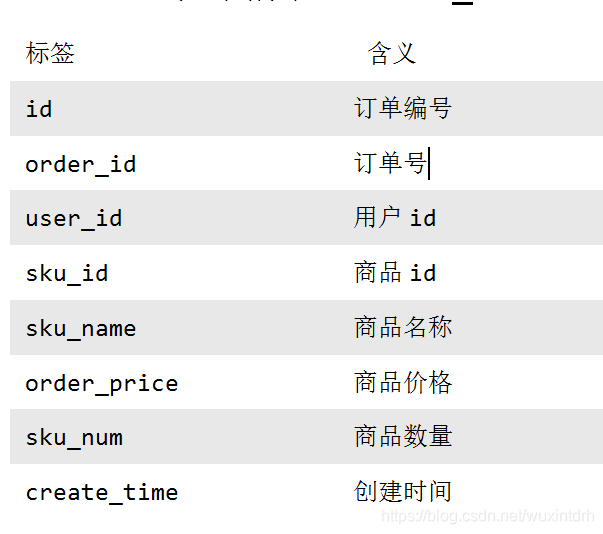 ### 6.3.3 商品表 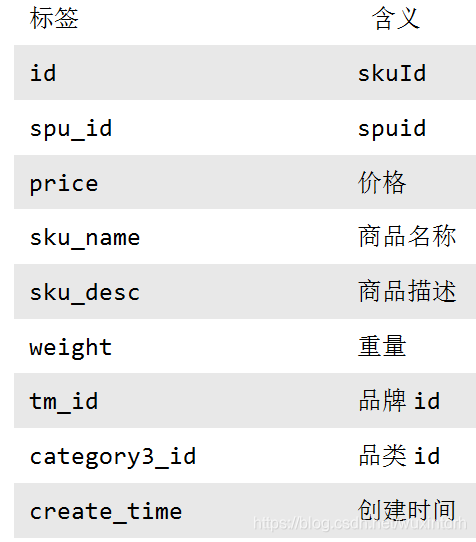 ### 6.3.4 用户表  ### 6.3.5 商品一级分类表 标签| 含义 --|-- id| id name |名称 ### 6.3.6 商品二级分类表 标签 |含义 --|-- id |id name |名称 category1_id |一级品类id ### 6.3.7 商品三级分类表 标签| 含义 --|-- id| id name |名称 Category2_id | 二级品类id ### 6.3.8 支付流水表 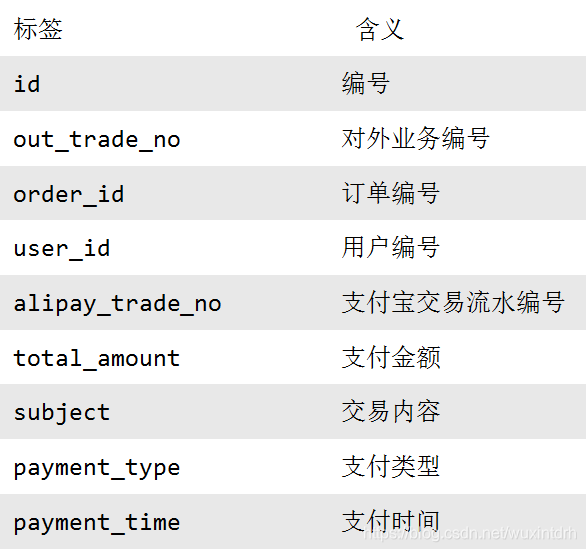 **订单表跟订单详情表有什么区别?** - 订单表的订单状态会变化,订单详情表不会,因为没有**订单状态**。 - **订单表**记录user_id,订单id订单编号,订单的总金额order_status,支付方式,订单状态等。 - **订单详情表**记录user_id,商品sku_id ,具体的商品信息(商品名称sku_name,价格order_price,数量sku_num) ## 6.4 MySql中表的分类 **实体表,维度表,事务型事实表,周期性事实表** 其实最终可以把**事务型事实表**,**周期性事实表**统称**实体表**,实体表,维度表统称维度表 订单表(order_info)(周期型事实表) 订单详情表(order_detail)(事务型事实表) 商品表(实体表) 用户表(实体表) 商品一级分类表(维度表) 商品二级分类表(维度表) 商品三级分类表(维度表) 支付流水表(事务型实体表) ## 6.5 同步策略  实体表,维度表统称维度表,每日全量或者每月(更长时间)全量 事务型事实表:每日增量 周期性事实表:拉链表 ## 6.6 关系型数据库范式理论 `1NF`:**属性不可再分割**(例如不能存在5台电脑的属性,坏处:表都没法用) `2NF`:**不能存在部分函数依赖**(例如主键(学号+课名)-->成绩,姓名,但学号 -->姓名,所以姓名部分依赖于主键(学号+课名),所以要去除,坏处:数据冗余) `3NF`:**不能存在传递函数依赖**(学号 --> 宿舍种类 --> 价钱,坏处:数据冗余和增删异常) **Mysql关系模型**:关系模型主要应用与**OLTP**系统中,为了保证数据的一致性以及避免冗余,所以大部分业务系统的表都是遵循第三范式的。 **Hive 维度模型**:维度模型主要应用于**OLAP**系统中,因为关系模型虽然冗余少, 但是在大规模数据,跨表分析统计查询过程中,会造成多表关联,这会大大降低执行效率。 所以HIVE把相关各种表整理成两种:**事实表和维度表**两种。所有维度表围绕着事实表进行解释。 ## 6.7 数据模型 雪花模型、星型模型和星座模型 (在维度建模的基础上又分为三种模型:星型模型、雪花模型、星座模型。) 星型模型(一级维度表),雪花(多级维度),星座模型(星型模型+多个事实表) ## 6.8 业务数据数仓搭建 sqoop 导数据的原理是mapreduce, import 把数据从关系型数据库 导到 数据仓库,自定义InputFormat, export 把数据从数据仓库 导到 关系型数据库,自定义OutputFormat, 用sqoop从mysql中将八张表的数据导入数仓的ods原始数据层 全量无条件,增量按照创建时间,增量+变化按照创建时间或操作时间。 origin_data sku_info商品表(每日导全量) user_info用户表(每日导全量) base_category1商品一级分类表(每日导全量) base_category2商品二级分类表(每日导全量) base_category3商品三级分类表(每日导全量) order_detail订单详情表(每日导增量) payment_info支付流水表(每日导增量) order_info订单表(每日导增量+变化) ### 6.8.1 ods层 (八张表,表名,字段跟mysql完全相同) 从origin\_data把数据导入到ods层,表名在原表名前加`ods_` ### 6.8.2 dwd层 对ODS层数据进行判空过滤。对商品分类表进行**维度退化**(降维)。其他数据跟ods层一模一样 订单表 `dwd_order_info` 订单详情表 `dwd_order_detail` 用户表 `dwd_user_info` 支付流水表 `dwd_payment_info` 商品表 `dwd_sku_info` 其他表字段不变,唯独商品表,通过关联3张分类表,增加了 ``` category2_id` string COMMENT '2id', `category1_id` string COMMENT '3id', `category3_name` string COMMENT '3', `category2_name` string COMMENT '2', `category1_name` string COMMENT '1', ``` 小结: 1)**维度退化要付出什么代价**?或者说会造成什么样的需求处理不了? - 如果被退化的维度,还有其他业务表使用,退化后处理起来就麻烦些。 - 还有如果要**删除数据,对应的维度可能也会被永久删除。** 2)想想在实际业务中还有**那些维度表可以退化** - 城市的三级分类(省、市、县)等 ### 6.8.3 dws层  从订单表 `dwd_order_info` 中获取 下单次数 和 下单总金额 从支付流水表 `dwd_payment_info` 中获取 支付次数 和 支付总金额 从事件日志评论表 `dwd_comment_log` 中获取评论次数 最终按照`user_id`聚合,获得明细,跟之前的`mid_id`聚合不同 ## 6.9、需求 ### 6.9.1 需求一:GMV成交总额 从用户行为宽表中`dws_user_action`,根据统计日期分组,聚合,直接sum就可以了。  ### 6.9.2、 需求二:转化率 #### 6.9.2.1 新增用户占日活跃用户比率表 从日活跃数表 `ads_uv_count` 和 日新增设备数表 `ads_new_mid_count` 中取即可。  #### 6.9.2.2 用户行为转化率表 从用户行为宽表`dws_user_action`中取,**下单人数(只要下单次数>0),支付人数(只要支付次数>0)** 从日活跃数表 `ads_uv_count` 中取活跃人数,然后对应的相除就可以了。  ### 6.9.3、 需求三:品牌复购率 需求:以月为单位统计,购买2次以上商品的用户 #### 6.9.3.1 用户购买商品明细表(宽表)  #### 6.9.3.2 品牌复购率表 从用户购买商品明细宽表`dws_sale_detail_daycount`中,根据品牌`id--sku_tm_id`聚合,计算每个品牌购买的总次数,购买人数a=购买次数>=1,两次及以上购买人数b=购买次数>=2,三次及以上购买人数c=购买次数>=3, 单次复购率=b/a,多次复购率=c/a  ## 6.10、 项目中有多少张宽表 宽表要3-5张,用户行为宽表,用户购买商品明细行为宽表,商品宽表,购物车宽表,物流宽表、登录注册、售后等。 **1)为什么要建宽表** 需求目标,把每个用户单日的行为聚合起来组成一张多列宽表,以便之后关联用户维度信息后进行,不同角度的统计分析。 ## 6.11、 拉链表 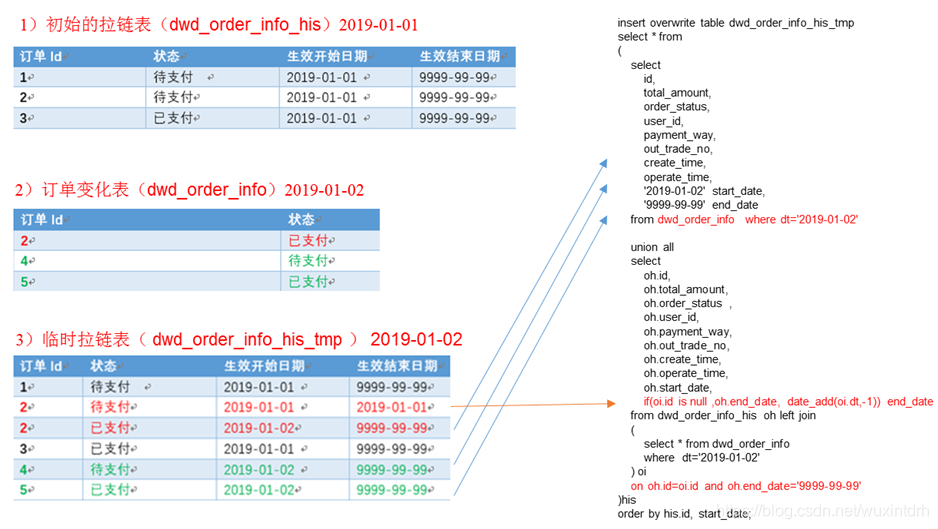 订单表拉链表 `dwd_order_info_his` ``` `id` string COMMENT '订单编号', `total_amount` decimal(10,2) COMMENT '订单金额', `order_status` string COMMENT '订单状态', `user_id` string COMMENT '用户id' , `payment_way` string COMMENT '支付方式', `out_trade_no` string COMMENT '支付流水号', `create_time` string COMMENT '创建时间', `operate_time` string COMMENT '操作时间' , `start_date` string COMMENT '有效开始日期', `end_date` string COMMENT '有效结束日期' ``` 1)创建订单表拉链表,字段跟拉链表一样,只增加了有效开始日期和有效结束日期 初始日期,从订单变化表`ods_order_info`导入数据,且让有效开始时间=当前日期,有效结束日期=`9999-99-99` (从mysql导入数仓的时候就只导了新增的和变化的数据`ods_order_info`,`dwd_order_info`跟`ods_order_info`基本一样,只多了一个id的判空处理) 2)建一张拉链临时表`dwd_order_info_his_tmp`,字段跟拉链表完全一致 3)新的拉链表中应该有这几部分数据, - (1)增加订单变化表`dwd_order_info`的全部数据 - (2)更新旧的拉链表左关联订单变化表`dwd_order_info`,关联字段:订单id, where 过滤出`end_date`只等于`9999-99-99`的数据,如果旧的拉链表中的`end_date`不等于`9999-99-99`,说明已经是终态了,不需要再更新 - 如果`dwd_order_info.id is null` , 没关联上,说明数据状态没变,让`end_date`还等于旧的`end_date` - 如果`dwd_order_info.id is not null `, 关联上了,说明数据状态变了,让`end_date`等于当前日期`-1` - 把查询结果插入到拉链临时表中 4)把拉链临时表覆盖到旧的拉链表中 # 关注我的公众号【宝哥大数据】, 更多干货