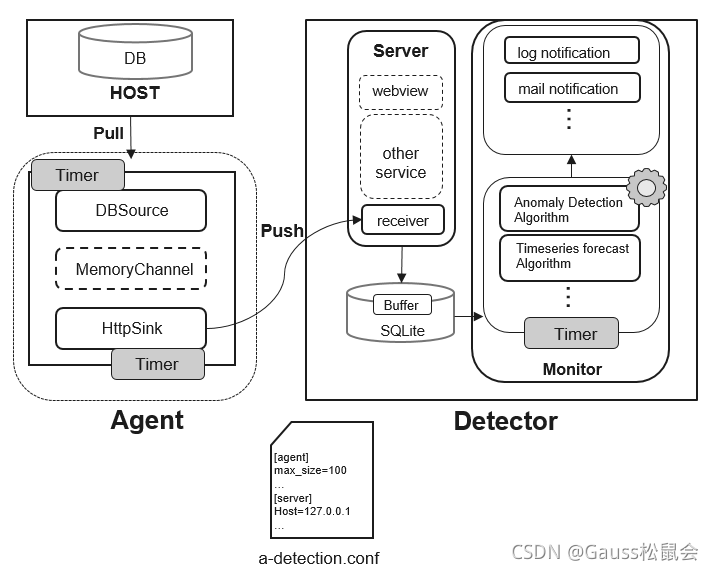
干货丨如何在数据库中利用高频数据找到最相关股票?
在制定投资策略时,我们往往会研究股票之间的相关性。研究个股的相关性或者个股与指数,ETF之间的相关性,从而通过对冲套利来获得稳定收益。找到最相关的股票,可以根据交易员的经验,也可以根据股票的相关信息(行业,beta,每日回报等)。 本文将介绍如何利用海量的高频数据寻找最相关的股票。 假设我们有一个数据表quotes,包含以下字段: symbol:股票代码 date:日期 time:时间 bid:买入价格 ofr:卖出价格 下面以纽约证券交易所2007年8月一个月实时报价数据的数据表quotes为例,计算股票在2007年8月1日的两两相关性。 选择500只最具流动性的股票。注意,由于本文使用的是纽约证券交易所的数据集,所以开盘时间是9:30-16:00。 dateValue=2007.08.01 num=500 syms = (exec count(*) from quotes where date = dateValue, time between 09:30:00 : 15:59:59, 0<bid, bid<ofr, ofr<bid*1.2 group by Symbol order by count desc).Symbol[0:num] 2. 构造股票每分钟交易价格的矩阵。列表示股票,行表示分钟。 priceMatrix = exec avg(bid + ofr)/2.0 as price from quotes where date = dateValue, Symbol in syms, 0<bid, bid<ofr, ofr<bid*1.2, time between 09:30:00 : 15:59:59 pivot by time.minute() as minute, Symbol exec和pivot by是DolphinDB编程语言的特点之一。exec与select的用法相同,但是select子句生成的是表,exec子句生成的是向量。pivot by用于整理维度,与exec一起使用时会生成一个矩阵。 3. 生成股票回报矩阵 retMatrix = each(def(x):ratios(x)-1, priceMatrix) 4. 生成500*500的股票回报相关矩阵 corrMatrix = cross(corr, retMatrix, retMatrix) 这时已经生成了500只最具流动性股票的两两相关性矩阵,取每只股票相关性最高的10只股票。 mostCorrelated = select * from table(corrMatrix.columnNames() as sym, corrMatrix).unpivot(`sym, syms).rename!(`sym`corrSym`corr) context by sym having rank(corr,false) between 1:10 步骤3和步骤4中使用的模板函数each和cross是 DolphinDB database 中的高阶函数,它以函数和对象作为输入内容,把函数应用到每个对象上。模板函数在复杂的批量计算中非常有用。 context by 语句是 DolphinDB database 编程语言的一个创新,是对标准SQL的扩展,大大简化了对面板数据的操作。context by与group by类似,都是用于分组计算。它们的区别是,group by对每组计算产生一个结果,而context by可对每组计算产生与组中元素个数相同的结果个数。换句话说,group by返回的结果个数等于组的个数,而context by返回结果的个数等于表中记录条数。context by增加了数据操作的灵活性,它可以把函数应用到组内的每个成员,这对组内计算的场景非常有用。 5. 这时我们可以分析某只股票与其他股票的相关性。比如,取与雷曼兄弟股票相关性最高的10只股票。从结果看,排名前三的都是与雷曼兄弟处于同一行业的三个投行。如果要取得更好的效果,避免数据的偶然性,可以计算更多天,然后取平均。 select * from mostCorrelated where sym='LEH' order by corr desc sym corrSym corr LEH MS 0.7027 LEH GS 0.6825 LEH MER 0.6788 LEH IAI 0.6785 LEH IYG 0.6481 LEH IWF 0.6296 LEH OEF 0.6287 LEH IYF 0.6275 LEH IWP 0.6213 LEH IWB 0.6161 性能分析 在2007年8月1日,共有8361只股票的实时报价数据,大约是3.8亿条数据。上面的代码需要对数据进行过滤,按分钟聚合,形成数据表透视,并进行矩阵迭代运算,如此复杂的计算任务,DolphinDB在一个4节点(每节点8核)的集群上耗时仅8秒。除此之外,DolphinDB的代码十分简洁高效,只需4行核心代码即可实现,这得益于功能强大的编程语言。如果你对DolphinDB编程语言感兴趣,可以查看DolphinDB的混合范式编程。