RabbitMQ学习:RabbitMQ的六种工作模式终结篇(四)
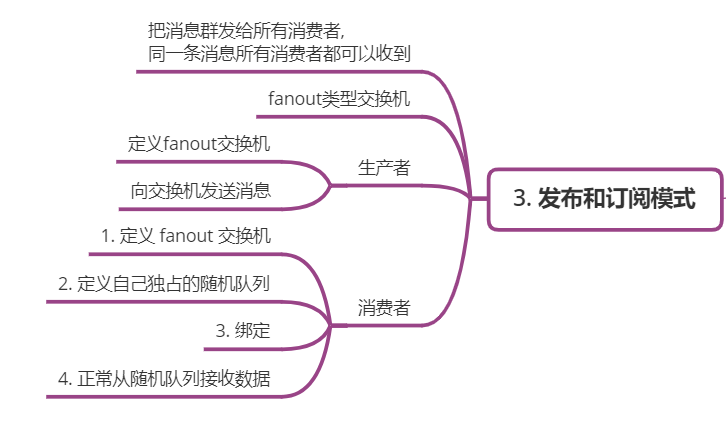
前言,在前面我讲到了RabbitMQ的六种工作模式中简单模式和工作模式 -- https://my.oschina.net/u/4115134/blog/3228182 ,这里呢,我就一次性将剩下的四种--发布订阅模式/路由模式/主题模式及Rpc异步调用模式,给大家进行分析,讲解一下,同时也给自己复习复习!!! 三、发布订阅模式 在前面的例子中,我们任务消息只交付给一个工作进程。在这部分,我们将做一些完全不同的事情——我们将向多个消费者传递同一条消息。这种模式称为“发布/订阅”。 为了说明该模式,我们将构建一个简单的日志系统。它将由两个程序组成——第一个程序将发出日志消息,第二个程序接收它们。 在我们的日志系统中,接收程序的每个运行副本都将获得消息。这样,我们就可以运行一个消费者并将日志保存到磁盘; 同时我们可以运行另一个消费者在屏幕上打印日志。 最终, 消息会被广播到所有消息接受者。 Exchanges 交换机 RabbitMQ消息传递模型的核心思想是,生产者永远不会将任何消息直接发送到队列。实际上,通常生产者甚至不知道消息是否会被传递到任何队列。 相反,生产者只能向交换机(Exchange)发送消息。交换机是一个非常简单的东西。一边接收来自生产者的消息,另一边将消息推送到队列。交换器必须确切地知道如何处理它接收到的消息。它应该被添加到一个特定的队列中吗?它应该添加到多个队列中吗?或者它应该被丢弃。这些规则由exchange的类型定义。 有几种可用的交换类型:direct、topic、header和fanout。我们将关注最后一个——fanout。让我们创建一个这种类型的交换机,并称之为 logs: ch.exchangeDeclare("logs", "fanout"); fanout交换机非常简单。它只是将接收到的所有消息广播给它所知道的所有队列。这正是我们的日志系统所需要的。 我们前面使用的队列具有特定的名称(还记得hello和task_queue吗?)能够为队列命名对我们来说至关重要——我们需要将工作进程指向同一个队列,在生产者和消费者之间共享队列。 但日志记录案例不是这种情况。我们想要接收所有的日志消息,而不仅仅是其中的一部分。我们还只对当前的最新消息感兴趣,而不是旧消息。 要解决这个问题,我们需要两件事。首先,每当我们连接到Rabbitmq时,我们需要一个新的空队列。为此,我们可以创建一个具有随机名称的队列,或者,更好的方法是让服务器为我们选择一个随机队列名称。其次,一旦断开与使用者的连接,队列就会自动删除。在Java客户端中,当我们不向queueDeclare()提供任何参数时,会创建一个具有生成名称的、非持久的、独占的、自动删除队列 //自动生成队列名 //非持久,独占,自动删除 String queueName = ch.queueDeclare().getQueue(); 绑定Bindings 我们已经创建了一个fanout交换机和一个队列。现在我们需要告诉exchange向指定队列发送消息。exchange和队列之间的关系称为绑定。 //指定的队列,与指定的交换机关联起来 //成为绑定 -- binding //第三个参数时 routingKey, 由于是fanout交换机, 这里忽略 routingKey ch.queueBind(queueName, "logs", ""); 现在, logs交换机将会向我们指定的队列添加消息 列出绑定关系: rabbitmqctl list_bindings 完成代码实现 生产者 生产者发出日志消息,看起来与前一教程没有太大不同。最重要的更改是,我们现在希望将消息发布到logs交换机,而不是无名的日志交换机。我们需要在发送时提供一个routingKey,但是对于fanout交换机类型,该值会被忽略。 package rabbitmq.publishsubscribe; import java.util.Scanner; import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection; import com.rabbitmq.client.ConnectionFactory; public class Test1 { public static void main(String[] args) throws Exception { ConnectionFactory f = new ConnectionFactory(); f.setHost("192.168.64.140"); f.setPort(5672); f.setUsername("admin"); f.setPassword("admin"); Connection c = f.newConnection(); Channel ch = c.createChannel(); //定义名字为logs的交换机,交换机类型为fanout //这一步是必须的,因为禁止发布到不存在的交换。 ch.exchangeDeclare("logs", "fanout"); while (true) { System.out.print("输入消息: "); String msg = new Scanner(System.in).nextLine(); if ("exit".equals(msg)) { break; } //第一个参数,向指定的交换机发送消息 //第二个参数,不指定队列,由消费者向交换机绑定队列 //如果还没有队列绑定到交换器,消息就会丢失, //但这对我们来说没有问题;即使没有消费者接收,我们也可以安全地丢弃这些信息。 ch.basicPublish("logs", "", null, msg.getBytes("UTF-8")); System.out.println("消息已发送: "+msg); } c.close(); } } 消费者 如果还没有队列绑定到交换器,消息就会丢失,但这对我们来说没有问题;如果还没有消费者在听,我们可以安全地丢弃这些信息。 package rabbitmq.publishsubscribe; import java.io.IOException; import com.rabbitmq.client.CancelCallback; import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection; import com.rabbitmq.client.ConnectionFactory; import com.rabbitmq.client.DeliverCallback; import com.rabbitmq.client.Delivery; public class Test2 { public static void main(String[] args) throws Exception { ConnectionFactory f = new ConnectionFactory(); f.setHost("192.168.64.140"); f.setUsername("admin"); f.setPassword("admin"); Connection c = f.newConnection(); Channel ch = c.createChannel(); //定义名字为 logs 的交换机, 它的类型是 fanout ch.exchangeDeclare("logs", "fanout"); //自动生成对列名, //非持久,独占,自动删除 String queueName = ch.queueDeclare().getQueue(); //把该队列,绑定到 logs 交换机 //对于 fanout 类型的交换机, routingKey会被忽略,不允许null值 ch.queueBind(queueName, "logs", ""); System.out.println("等待接收数据"); //收到消息后用来处理消息的回调对象 DeliverCallback callback = new DeliverCallback() { @Override public void handle(String consumerTag, Delivery message) throws IOException { String msg = new String(message.getBody(), "UTF-8"); System.out.println("收到: "+msg); } }; //消费者取消时的回调对象 CancelCallback cancel = new CancelCallback() { @Override public void handle(String consumerTag) throws IOException { } }; ch.basicConsume(queueName, true, callback, cancel); } } 四、路由模式 在上一小节,我们构建了一个简单的日志系统。我们能够向多个接收者广播日志消息。 在这一节,我们将向其添加一个特性—我们将只订阅所有消息中的一部分。例如,我们只接收关键错误消息并保存到日志文件(以节省磁盘空间),同时仍然能够在控制台上打印所有日志消息。 绑定 Bindings 在上一节,我们已经创建了队列与交换机的绑定。使用下面这样的代码: ch.queueBind(queueName, "logs", ""); 绑定是交换机和队列之间的关系。这可以简单地理解为:队列对来自此交换的消息感兴趣。 绑定可以使用额外的routingKey参数。为了避免与basic_publish参数混淆,我们将其称为bindingKey。这是我们如何创建一个键绑定: ch.queueBind(queueName, EXCHANGE_NAME, "black"); bindingKey的含义取决于交换机类型。我们前面使用的fanout交换机完全忽略它。 直连交换机 Direct exchange 上一节中的日志系统向所有消费者广播所有消息。我们希望扩展它,允许根据消息的严重性过滤消息。例如,我们希望将日志消息写入磁盘的程序只接收关键error,而不是在warning或info日志消息上浪费磁盘空间。 前面我们使用的是fanout交换机,这并没有给我们太多的灵活性——它只能进行简单的广播。 我们将用直连交换机(Direct exchange)代替。它背后的路由算法很简单——消息传递到bindingKey与routingKey完全匹配的队列。为了说明这一点,请考虑以下设置 其中我们可以看到直连交换机X,它绑定了两个队列。第一个队列用绑定键orange绑定,第二个队列有两个绑定,一个绑定black,另一个绑定键green。 这样设置,使用路由键orange发布到交换器的消息将被路由到队列Q1。带有black或green路由键的消息将转到Q2。而所有其他消息都将被丢弃。 多重绑定 Multiple bindings 使用相同的bindingKey绑定多个队列是完全允许的。如图所示,可以使用binding key black将X与Q1和Q2绑定。在这种情况下,直连交换机的行为类似于fanout,并将消息广播给所有匹配的队列。一条路由键为black的消息将同时发送到Q1和Q2。 发送日志 我们将在日志系统中使用这个模型。我们把消息发送到一个Direct交换机,而不是fanout。我们将提供日志级别作为routingKey。这样,接收程序将能够选择它希望接收的级别。让我们首先来看发出日志。 和前面一样,我们首先需要创建一个exchange: //参数1: 交换机名 //参数2: 交换机类型 ch.exchangeDeclare("direct_logs", "direct"); 接着来看发送消息的代码 //参数1: 交换机名 //参数2: routingKey, 路由键,这里我们用日志级别,如"error","info","warning" //参数3: 其他配置属性 //参数4: 发布的消息数据 ch.basicPublish("direct_logs", "error", null, message.getBytes()); 订阅 接收消息的工作原理与前面章节一样,但有一个例外——我们将为感兴趣的每个日志级别创建一个新的绑定, 示例代码如下: ch.queueBind(queueName, "logs", "info"); ch.queueBind(queueName, "logs", "warning"); 最终代码实现 生产者 package rabbitmq.routing; import java.util.Random; import java.util.Scanner; import com.rabbitmq.client.BuiltinExchangeType; import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection; import com.rabbitmq.client.ConnectionFactory; public class Test1 { public static void main(String[] args) throws Exception { String[] a = {"warning", "info", "error"}; ConnectionFactory f = new ConnectionFactory(); f.setHost("192.168.64.140"); f.setPort(5672); f.setUsername("admin"); f.setPassword("admin"); Connection c = f.newConnection(); Channel ch = c.createChannel(); //参数1: 交换机名 //参数2: 交换机类型 ch.exchangeDeclare("direct_logs", BuiltinExchangeType.DIRECT); while (true) { System.out.print("输入消息: "); String msg = new Scanner(System.in).nextLine(); if ("exit".equals(msg)) { break; } //随机产生日志级别 String level = a[new Random().nextInt(a.length)]; //参数1: 交换机名 //参数2: routingKey, 路由键,这里我们用日志级别,如"error","info","warning" //参数3: 其他配置属性 //参数4: 发布的消息数据 ch.basicPublish("direct_logs", level, null, msg.getBytes()); System.out.println("消息已发送: "+level+" - "+msg); } c.close(); } } 消费者 package rabbitmq.routing; import java.io.IOException; import java.util.Scanner; import com.rabbitmq.client.BuiltinExchangeType; import com.rabbitmq.client.CancelCallback; import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection; import com.rabbitmq.client.ConnectionFactory; import com.rabbitmq.client.DeliverCallback; import com.rabbitmq.client.Delivery; public class Test2 { public static void main(String[] args) throws Exception { ConnectionFactory f = new ConnectionFactory(); f.setHost("192.168.64.140"); f.setUsername("admin"); f.setPassword("admin"); Connection c = f.newConnection(); Channel ch = c.createChannel(); //定义名字为 direct_logs 的交换机, 它的类型是 "direct" ch.exchangeDeclare("direct_logs", BuiltinExchangeType.DIRECT); //自动生成对列名, //非持久,独占,自动删除 String queueName = ch.queueDeclare().getQueue(); System.out.println("输入接收的日志级别,用空格隔开:"); String[] a = new Scanner(System.in).nextLine().split("\\s"); //把该队列,绑定到 direct_logs 交换机 //允许使用多个 bindingKey for (String level : a) { ch.queueBind(queueName, "direct_logs", level); } System.out.println("等待接收数据"); //收到消息后用来处理消息的回调对象 DeliverCallback callback = new DeliverCallback() { @Override public void handle(String consumerTag, Delivery message) throws IOException { String msg = new String(message.getBody(), "UTF-8"); String routingKey = message.getEnvelope().getRoutingKey(); System.out.println("收到: "+routingKey+" - "+msg); } }; //消费者取消时的回调对象 CancelCallback cancel = new CancelCallback() { @Override public void handle(String consumerTag) throws IOException { } }; ch.basicConsume(queueName, true, callback, cancel); } } 五、主题模式 在上一小节,我们改进了日志系统。我们没有使用只能进行广播的fanout交换机,而是使用Direct交换机,从而可以选择性接收日志。 虽然使用Direct交换机改进了我们的系统,但它仍然有局限性——它不能基于多个标准进行路由。 在我们的日志系统中,我们可能不仅希望根据级别订阅日志,还希望根据发出日志的源订阅日志。 这将给我们带来很大的灵活性——我们可能只想接收来自“cron”的关键错误,但也要接收来自“kern”的所有日志。 要在日志系统中实现这一点,我们需要了解更复杂的Topic交换机。 主题交换机 Topic exchange 发送到Topic交换机的消息,它的的routingKey,必须是由点分隔的多个单词。单词可以是任何东西,但通常是与消息相关的一些特性。几个有效的routingKey示例:“stock.usd.nyse”、“nyse.vmw”、“quick.orange.rabbit”。routingKey可以有任意多的单词,最多255个字节。 bindingKey也必须采用相同的形式。Topic交换机的逻辑与直连交换机类似——使用特定routingKey发送的消息将被传递到所有使用匹配bindingKey绑定的队列。bindingKey有两个重要的特殊点: * 可以通配单个单词。 # 可以通配零个或多个单词。 用一个例子来解释这个问题是最简单的 在本例中,我们将发送描述动物的消息。这些消息将使用由三个单词(两个点)组成的routingKey发送。routingKey中的第一个单词表示速度,第二个是颜色,第三个是物种:“<速度>.<颜色>.<物种>”。 我们创建三个绑定:Q1与bindingKey “.orange.” 绑定。和Q2是 “*.*.rabbit” 和 “lazy.#” 。 这些绑定可概括为: Q1对所有橙色的动物感兴趣。 Q2想接收关于兔子和慢速动物的所有消息。 将routingKey设置为"quick.orange.rabbit"的消息将被发送到两个队列。消息 "lazy.orange.elephant“也发送到它们两个。另外”quick.orange.fox“只会发到第一个队列,”lazy.brown.fox“只发给第二个。”lazy.pink.rabbit“将只被传递到第二个队列一次,即使它匹配两个绑定。”quick.brown.fox"不匹配任何绑定,因此将被丢弃。 如果我们违反约定,发送一个或四个单词的信息,比如"orange“或”quick.orange.male.rabbit",会发生什么?这些消息将不匹配任何绑定,并将丢失。 另外,"lazy.orange.male.rabbit",即使它有四个单词,也将匹配最后一个绑定,并将被传递到第二个队列。 最终代码实现 生产者 package rabbitmq.topic; import java.util.Random; import java.util.Scanner; import com.rabbitmq.client.BuiltinExchangeType; import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection; import com.rabbitmq.client.ConnectionFactory; public class Test1 { public static void main(String[] args) throws Exception { ConnectionFactory f = new ConnectionFactory(); f.setHost("192.168.64.140"); f.setPort(5672); f.setUsername("admin"); f.setPassword("admin"); Connection c = f.newConnection(); Channel ch = c.createChannel(); //参数1: 交换机名 //参数2: 交换机类型 ch.exchangeDeclare("topic_logs", BuiltinExchangeType.TOPIC); while (true) { System.out.print("输入消息: "); String msg = new Scanner(System.in).nextLine(); if ("exit".contentEquals(msg)) { break; } System.out.print("输入routingKey: "); String routingKey = new Scanner(System.in).nextLine(); //参数1: 交换机名 //参数2: routingKey, 路由键,这里我们用日志级别,如"error","info","warning" //参数3: 其他配置属性 //参数4: 发布的消息数据 ch.basicPublish("topic_logs", routingKey, null, msg.getBytes()); System.out.println("消息已发送: "+routingKey+" - "+msg); } c.close(); } } 消费者 package rabbitmq.topic; import java.io.IOException; import java.util.Scanner; import com.rabbitmq.client.BuiltinExchangeType; import com.rabbitmq.client.CancelCallback; import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection; import com.rabbitmq.client.ConnectionFactory; import com.rabbitmq.client.DeliverCallback; import com.rabbitmq.client.Delivery; public class Test2 { public static void main(String[] args) throws Exception { ConnectionFactory f = new ConnectionFactory(); f.setHost("192.168.64.140"); f.setUsername("admin"); f.setPassword("admin"); Connection c = f.newConnection(); Channel ch = c.createChannel(); ch.exchangeDeclare("topic_logs", BuiltinExchangeType.TOPIC); //自动生成对列名, //非持久,独占,自动删除 String queueName = ch.queueDeclare().getQueue(); System.out.println("输入bindingKey,用空格隔开:"); String[] a = new Scanner(System.in).nextLine().split("\\s"); //把该队列,绑定到 topic_logs 交换机 //允许使用多个 bindingKey for (String bindingKey : a) { ch.queueBind(queueName, "topic_logs", bindingKey); } System.out.println("等待接收数据"); //收到消息后用来处理消息的回调对象 DeliverCallback callback = new DeliverCallback() { @Override public void handle(String consumerTag, Delivery message) throws IOException { String msg = new String(message.getBody(), "UTF-8"); String routingKey = message.getEnvelope().getRoutingKey(); System.out.println("收到: "+routingKey+" - "+msg); } }; //消费者取消时的回调对象 CancelCallback cancel = new CancelCallback() { @Override public void handle(String consumerTag) throws IOException { } }; ch.basicConsume(queueName, true, callback, cancel); } } 六、RPC模式 客户端 在客户端定义一个RPCClient类,并定义一个call()方法,这个方法发送一个RPC请求,并等待接收响应结果 RPCClient client = new RPCClient(); String result = client.call("4"); System.out.println( "第四个斐波那契数是: " + result); 回调队列 Callback Queue 使用RabbitMQ去实现RPC很容易。一个客户端发送请求信息,并得到一个服务器端回复的响应信息。为了得到响应信息,我们需要在请求的时候发送一个“回调”队列地址。我们可以使用默认队列。下面是示例代码: //定义回调队列, //自动生成对列名,非持久,独占,自动删除 callbackQueueName = ch.queueDeclare().getQueue(); //用来设置回调队列的参数对象 BasicProperties props = new BasicProperties .Builder() .replyTo(callbackQueueName) .build(); //发送调用消息 ch.basicPublish("", "rpc_queue", props, message.getBytes()); 消息属性 Message Properties AMQP 0-9-1协议定义了消息的14个属性。大部分属性很少使用,下面是比较常用的4个: deliveryMode:将消息标记为持久化(值为2)或非持久化(任何其他值)。 contentType:用于描述mime类型。例如,对于经常使用的JSON格式,将此属性设置为:application/json。 replyTo:通常用于指定回调队列。 correlationId:将RPC响应与请求关联起来非常有用。 关联id (correlationId): 在上面的代码中,我们会为每个RPC请求创建一个回调队列。 这是非常低效的,这里还有一个更好的方法:让我们为每个客户端创建一个回调队列。 这就提出了一个新的问题,在队列中得到一个响应时,我们不清楚这个响应所对应的是哪一条请求。这时候就需要使用关联id(correlationId)。我们将为每一条请求设置唯一的的id值。稍后,当我们在回调队列里收到一条消息的时候,我们将查看它的id属性,这样我们就可以匹配对应的请求和响应。如果我们发现了一个未知的id值,我们可以安全的丢弃这条消息,因为它不属于我们的请求。 最终实现代码 RPC的工作方式是这样的: 对于RPC请求,客户端发送一条带有两个属性的消息:replyTo,设置为仅为请求创建的匿名独占队列,和correlationId,设置为每个请求的惟一id值。 请求被发送到rpc_queue队列。 RPC工作进程(即:服务器)在队列上等待请求。当一个请求出现时,它执行任务,并使用replyTo字段中的队列将结果发回客户机。 客户机在回应消息队列上等待数据。当消息出现时,它检查correlationId属性。如果匹配请求中的值,则向程序返回该响应数据。 服务器端 package rabbitmq.rpc; import java.io.IOException; import java.util.Random; import java.util.Scanner; import com.rabbitmq.client.AMQP; import com.rabbitmq.client.BuiltinExchangeType; import com.rabbitmq.client.CancelCallback; import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection; import com.rabbitmq.client.ConnectionFactory; import com.rabbitmq.client.DeliverCallback; import com.rabbitmq.client.Delivery; import com.rabbitmq.client.AMQP.BasicProperties; public class RPCServer { public static void main(String[] args) throws Exception { ConnectionFactory f = new ConnectionFactory(); f.setHost("192.168.64.140"); f.setPort(5672); f.setUsername("admin"); f.setPassword("admin"); Connection c = f.newConnection(); Channel ch = c.createChannel(); /* * 定义队列 rpc_queue, 将从它接收请求信息 * * 参数: * 1. queue, 对列名 * 2. durable, 持久化 * 3. exclusive, 排他 * 4. autoDelete, 自动删除 * 5. arguments, 其他参数属性 */ ch.queueDeclare("rpc_queue",false,false,false,null); ch.queuePurge("rpc_queue");//清除队列中的内容 ch.basicQos(1);//一次只接收一条消息 //收到请求消息后的回调对象 DeliverCallback deliverCallback = new DeliverCallback() { @Override public void handle(String consumerTag, Delivery message) throws IOException { //处理收到的数据(要求第几个斐波那契数) String msg = new String(message.getBody(), "UTF-8"); int n = Integer.parseInt(msg); //求出第n个斐波那契数 int r = fbnq(n); String response = String.valueOf(r); //设置发回响应的id, 与请求id一致, 这样客户端可以把该响应与它的请求进行对应 BasicProperties replyProps = new BasicProperties.Builder() .correlationId(message.getProperties().getCorrelationId()) .build(); /* * 发送响应消息 * 1. 默认交换机 * 2. 由客户端指定的,用来传递响应消息的队列名 * 3. 参数(关联id) * 4. 发回的响应消息 */ ch.basicPublish("",message.getProperties().getReplyTo(), replyProps, response.getBytes("UTF-8")); //发送确认消息 ch.basicAck(message.getEnvelope().getDeliveryTag(), false); } }; // CancelCallback cancelCallback = new CancelCallback() { @Override public void handle(String consumerTag) throws IOException { } }; //消费者开始接收消息, 等待从 rpc_queue接收请求消息, 不自动确认 ch.basicConsume("rpc_queue", false, deliverCallback, cancelCallback); } protected static int fbnq(int n) { if(n == 1 || n == 2) return 1; return fbnq(n-1)+fbnq(n-2); } } 客户端 package rabbitmq.rpc; import java.io.IOException; import java.util.Scanner; import java.util.UUID; import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.BlockingQueue; import com.rabbitmq.client.BuiltinExchangeType; import com.rabbitmq.client.CancelCallback; import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection; import com.rabbitmq.client.ConnectionFactory; import com.rabbitmq.client.DeliverCallback; import com.rabbitmq.client.Delivery; import com.rabbitmq.client.AMQP.BasicProperties; public class RPCClient { Connection con; Channel ch; public RPCClient() throws Exception { ConnectionFactory f = new ConnectionFactory(); f.setHost("192.168.64.140"); f.setUsername("admin"); f.setPassword("admin"); con = f.newConnection(); ch = con.createChannel(); } public String call(String msg) throws Exception { //自动生成对列名,非持久,独占,自动删除 String replyQueueName = ch.queueDeclare().getQueue(); //生成关联id String corrId = UUID.randomUUID().toString(); //设置两个参数: //1. 请求和响应的关联id //2. 传递响应数据的queue BasicProperties props = new BasicProperties.Builder() .correlationId(corrId) .replyTo(replyQueueName) .build(); //向 rpc_queue 队列发送请求数据, 请求第n个斐波那契数 ch.basicPublish("", "rpc_queue", props, msg.getBytes("UTF-8")); //用来保存结果的阻塞集合,取数据时,没有数据会暂停等待 BlockingQueue<String> response = new ArrayBlockingQueue<String>(1); //接收响应数据的回调对象 DeliverCallback deliverCallback = new DeliverCallback() { @Override public void handle(String consumerTag, Delivery message) throws IOException { //如果响应消息的关联id,与请求的关联id相同,我们来处理这个响应数据 if (message.getProperties().getCorrelationId().contentEquals(corrId)) { //把收到的响应数据,放入阻塞集合 response.offer(new String(message.getBody(), "UTF-8")); } } }; CancelCallback cancelCallback = new CancelCallback() { @Override public void handle(String consumerTag) throws IOException { } }; //开始从队列接收响应数据 ch.basicConsume(replyQueueName, true, deliverCallback, cancelCallback); //返回保存在集合中的响应数据 return response.take(); } public static void main(String[] args) throws Exception { RPCClient client = new RPCClient(); while (true) { System.out.print("求第几个斐波那契数:"); int n = new Scanner(System.in).nextInt(); String r = client.call(""+n); System.out.println(r); } } } 七、RabbitMQ六种工作模式总结: 如果觉得我写的可以,是否可以【穿着条纹睡衣的男孩】,更多精彩会等着你哦