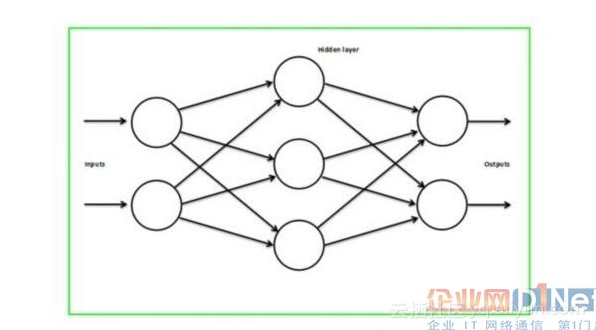
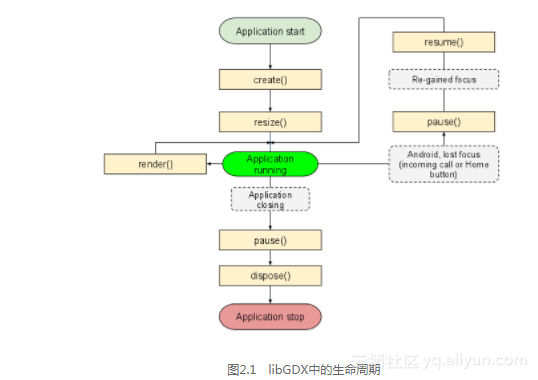
Manifest.xml 入门基础 (五)<Activity>标签
<activity android:allowTaskReparenting=["true" | "false"] android:alwaysRetainTaskState=["true" | "false"] android:clearTaskOnLaunch=["true" | "false"] android:configChanges=["mcc", "mnc", "locale", "touchscreen", "keyboard", "keyboardHidden", "navigation", "orientation", "screenLayout", "fontScale", "uiMode"] android:enabled=["true" | "false"] android:excludeFromRecents=["true" | "false"] android:exported=["true" | "false"] android:finishOnTaskLaunch=["true" | "false"] android:icon="drawable resource" android:label="string resource" android:launchMode=["multiple" | "singleTop" | "singleTask" | "singleInstance"] android:multiprocess=["true" | "false"] android:name="string" android:noHistory=["true" | "false"] android:permission="string" android:process="string" android:screenOrientation=["unspecified" | "user" | "behind" | "landscape" | "portrait" | "sensor" | "nosensor"] android:stateNotNeeded=["true" | "false"] android:taskAffinity="string" android:theme="resource or theme" android:windowSoftInputMode=["stateUnspecified", "stateUnchanged", "stateHidden", "stateAlwaysHidden", "stateVisible", "stateAlwaysVisible", "adjustUnspecified", "adjustResize", "adjustPan"] > </activity> A、android:alwaysRetainTaskState 是否保留状态不变, 比如切换回home, 再从新打开,activity处于最后的状态。比如一个浏览器拥有很多状态(当打开了多个TAB的时候),用户并不希望丢失这些状态时,此时可将此属性设置为true B、android:clearTaskOnLaunch 比如 P 是 activity, Q 是被P 触发的 activity, 然后返回Home, 重新启动 P,是否显示 Q C、android:configChanges 当配置list发生修改时, 是否调用 onConfigurationChanged() 方法 比如 “locale|navigation|orientation”. 这个我用过,主要用来看手机方向改变的. android手机在旋转后,layout会重新布局, 如何做到呢?正常情况下. 如果手机旋转了.当前Activity后杀掉,然后根据方向重新加载这个Activity. 就会从onCreate开始重新加载.如果你设置了 这个选项, 当手机旋转后,当前Activity之后调用onConfigurationChanged() 方法. 而不跑onCreate方法等. D、android:excludeFromRecents 是否可被显示在最近打开的activity列表里,默认是false E、android:finishOnTaskLaunch 当用户重新启动这个任务的时候,是否关闭已打开的activity,默认是false如果这个属性和allowTaskReparenting都是true,这个属性就是王牌。Activity的亲和力将被忽略。该Activity已经被摧毁并非re-parented F、android:launchMode(Activity加载模式) 在多Activity开发中,有可能是自己应用之间的Activity跳转,或者夹带其他应用的可复用Activity。可能会希望跳转到原来某个Activity实例,而不是产生大量重复的Activity。这需要为Activity配置特定的加载模式,而不是使用默认的加载模式 Activity有四种加载模式: standard、singleTop、singleTask、singleInstance(其中前两个是一组、后两个是一组),默认为standard standard:就是intent将发送给新的实例,所以每次跳转都会生成新的activity。 singleTop:也是发送新的实例,但不同standard的一点是,在请求的Activity正好位于栈顶时(配置成singleTop的Activity),不会构造新的实例 singleTask:和后面的singleInstance都只创建一个实例,当intent到来,需要创建设置为singleTask的Activity的时候,系统会检查栈里面是否已经有该Activity的实例。如果有直接将intent发送给它。 singleInstance:首先说明一下task这个概念,Task可以认为是一个栈,可放入多个Activity。比如启动一个应用,那么Android就创建了一个Task,然后启动这个应用的入口Activity,那在它的界面上调用其他的Activity也只是在这个task里面。那如果在多个task中共享一个Activity的话怎么办呢。举个例来说,如果开启一个导游服务类的应用程序,里面有个Activity是开启GOOGLE地图的,当按下home键退回到主菜单又启动GOOGLE地图的应用时,显示的就是刚才的地图,实际上是同一个Activity,实际上这就引入了singleInstance。singleInstance模式就是将该Activity单独放入一个栈中,这样这个栈中只有这一个Activity,不同应用的intent都由这个Activity接收和展示,这样就做到了共享。当然前提是这些应用都没有被销毁,所以刚才是按下的HOME键,如果按下了返回键,则无效。 G、android:multiprocess 是否允许多进程,默认是false 在实际开发中,CP有以下两种用法: 1)和应用在一个APK包里 这种情况下和应用在同一进程中。process name和uid都一样。 2)单独在一个APK包里。 这种情况下,如果在AndroidManifest.xml文件里声明了和某个进程同属一个进程,如: package="com.android.providers.telephony" android:sharedUserId="android.uid.phone"> android:allowClearUserData="false" android:label="Dialer Storage" android:icon="@drawable/ic_launcher_phone"> android:authorities="telephony" android:multiprocess="true" 这个里面通过android:sharedUserId=”android.uid.phone”和android:process=”com.android.phone”声明了该CP是和phone进程同属一个进程,拥有同样的process name和uid. 如果没有上述声明,那么该CP是在独立的进程中,拥有属于自己的process name和uid. 以上两种用法可以总结为: 1)CP和某个进程同属一个进程 这种情况下,当该进程启动时,会搜索属于该进程的所有CP,并加载。 2)CP属于独立的一个进程。 这种情况下,只有需要用到该CP时,才会去加载。 那么,当一个进程想要操作一个CP时,先需要获取该CP的对象,系统是如何处理呢: 1)如果该CP属于当前主叫进程,因为在进程启动时就已经加载过了,所以系统会直接返回该CP的对象。 2)如果该CP不属于当前主叫进程,那么系统会进行相关处理(由ActivityManagerService进行,以下简称为AMS): 所有已加载的CP信息都已保存在AMS中。当需要获取某个CP的对象时,AMS会先判断该CP是否已被加载 —-如果已被加载,该CP和当前主叫进程不属一个进程,但是该CP设置了multiprocess的属性(如上例中的android:multiprocess=”true”),并且该CP属于系统级CP,那么就在当前主叫进程内部新生成该CP的对象。否则就需要通过IPC机制进行调用。 —-如果还未被加载,该CP和当前主叫进程不属一个进程,但是该CP设置了multiprocess的属性(如上例中的android:multiprocess=”true”),并且该CP属于系统级CP,那么就在当前主叫进程内部新生成该CP的对象。否则就需要先创建该CP所在的进程,然后再通过IPC机制进行调用。 H、android:noHistory 当用户从Activity上离开并且它在屏幕上不再可见时,Activity是否从Activity stack中清除并结束。默认是false。Activity不会留下历史痕迹 I、android:screenOrientation activity显示的模式 默认为unspecified:由系统自动判断显示方向 landscape横屏模式,宽度比高度大 portrait竖屏模式, 高度比宽度大 user模式,用户当前首选的方向 behind模式:和该Activity下面的那个Activity的方向一致(在Activity堆栈中的) sensor模式:有物理的感应器来决定。如果用户旋转设备这屏幕会横竖屏切换 nosensor模式:忽略物理感应器,这样就不会随着用户旋转设备而更改了 J、android:stateNotNeeded activity被销毁或者成功重启时是否保存状态 K、android:windowSoftInputMode activity主窗口与软键盘的交互模式,可以用来避免输入法面板遮挡问题,Android1.5后的一个新特性。 这个属性能影响两件事情: 【A】当有焦点产生时,软键盘是隐藏还是显示 【B】是否减少活动主窗口大小以便腾出空间放软键盘 各值的含义: 【A】stateUnspecified:软键盘的状态并没有指定,系统将选择一个合适的状态或依赖于主题的设置 【B】stateUnchanged:当这个activity出现时,软键盘将一直保持在上一个activity里的状态,无论是隐藏还是显示 【C】stateHidden:用户选择activity时,软键盘总是被隐藏 【D】stateAlwaysHidden:当该Activity主窗口获取焦点时,软键盘也总是被隐藏的 【E】stateVisible:软键盘通常是可见的 【F】stateAlwaysVisible:用户选择activity时,软键盘总是显示的状态 【G】adjustUnspecified:默认设置,通常由系统自行决定是隐藏还是显示 【H】adjustResize:该Activity总是调整屏幕的大小以便留出软键盘的空间 【I】adjustPan:当前窗口的内容将自动移动以便当前焦点从不被键盘覆盖和用户能总是看到输入内容的部分。 一般情况下,在新建一个activity后,为了使intent可以调用此活动,我们要在androidManifest.xml文件中添加一个<activity>标签,<activity>标签的一般格式如下: <activity android:name="my.test.intents.MainActivity" android:label="@string/app_name" > <intent-filter> <action android:name="android.intent.action.MAIN" /> <category android:name="android.intent.category.LAUNCHER" /> </intent-filter> </activity> 其中,”android:name”是活动对应的类名称,”android:label”是活动标题栏显示的内容,<intent-filter>是意图筛选器,<action>是动作名称,是指intent要执行的动作,<category>是类别名称,一般情况下,每个<intent-filter> 中都要显示指定一个默认的类别名称,即<category android:name=”android.intent.category.DEFAULT” />,但是上面的代码中没有指定默认类别名称,这是一个例外情况,因为其<intent-filter> 中的<action>是”android.intent.action.MAIN”,意思是这项活动是应用程序的入口点,这种情况下可以不加默认类别名称。 当然,除<action>和<category>以外,<intent-filter>中还有很多其他元素,在这里不详述。 上面的代码是androidManifest.xml中定义程序入口活动的例子,下面我们写一个自定义的例子: <activity android:name=".MyBrowserActivity" android:label="My Activity" > <intent-filter> <action android:name="my.test.MyBrowser"/> <category android:name="android.intent.category.DEFAULT" /> <data android:scheme="http"/> </intent-filter> </activity> 在这个<activity>标签中,我们指定活动的类为MyBrowserActivity.class,活动的标题显示为”My Activity”,<action android:name=”my.test.MyBrowser”/>意味着其他活动可以通过my.test.MyBrowser动作来调用这个活动,”my.test.MyBrowser”只是我们定义的一个动作的名称,写成包的形式是因为这样使我们更容易理解它的含义,如果我们把”my.test.MyBrowser”改成任意的内容如:”somethingelse”,同样,我们可以通过这个新的动作名称,来调用这个活动。<data> 元素指定了活动期望的数据类型,在这里,它期望的数据要以http://前缀开头。