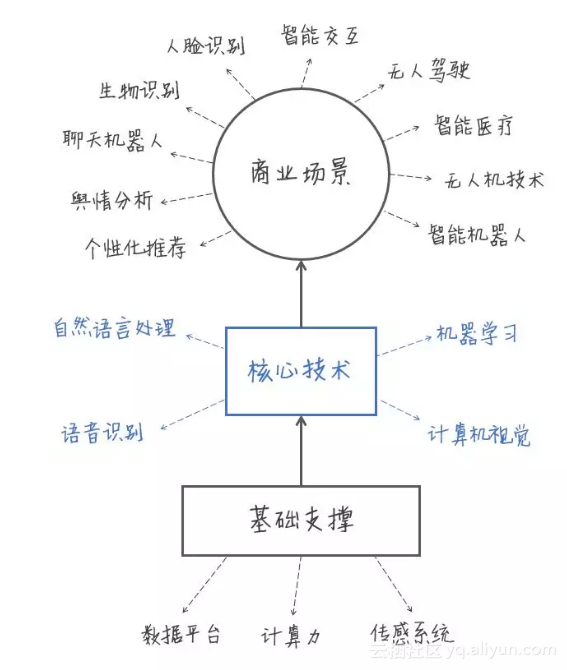
Golang 入门系列(九) 如何读取YAML,JSON,INI等配置文件
实际项目中,读取相关的系统配置文件是很常见的事情。今天就来说一说,Golang 是如何读取YAML,JSON,INI等配置文件的。 1. json使用 JSON 应该比较熟悉,它是一种轻量级的数据交换格式。层次结构简洁清晰 ,易于阅读和编写,同时也易于机器解析和生成。 1. 创建 conf.json: { "enabled": true, "path": "/usr/local" } 2. 新建config_json.go: package main import ( "encoding/json" "fmt" "os" ) type configuration struct { Enabled bool Path string } func main() { // 打开文件 file, _ := os.Open("conf.json") // 关闭文件 defer file.Close() //NewDecoder创建一个从file读取并解码json对象的*Decoder,解码器有自己的缓冲,并可能超前读取部分json数据。 decoder := json.NewDecoder(file) conf := configuration{} //Decode从输入流读取下一个json编码值并保存在v指向的值里 err := decoder.Decode(&conf) if err != nil { fmt.Println("Error:", err) } fmt.Println("path:" + conf.Path) } 启动运行后,输出如下: D:\Go_Path\go\src\configmgr>go run config_json.go path:/usr/local 2. ini的使用 INI文件格式是某些平台或软件上的配置文件的非正式标准,由节(section)和键(key)构成,比较常用于微软Windows操作系统中。这种配置文件的文件扩展名为INI。 1. 创建 conf.ini: [Section] enabled = true path = /usr/local # another comment 2.下载第三方库:go get gopkg.in/gcfg.v1 3.新建 config_ini.go: package main import ( "fmt" gcfg "gopkg.in/gcfg.v1" ) func main() { config := struct { Section struct { Enabled bool Path string } }{} err := gcfg.ReadFileInto(&config, "conf.ini") if err != nil { fmt.Println("Failed to parse config file: %s", err) } fmt.Println(config.Section.Enabled) fmt.Println(config.Section.Path) } 启动运行后,输出如下: D:\Go_Path\go\src\configmgr>go run config_ini.go true /usr/local 3. yaml使用 yaml 可能比较陌生一点,但是最近却越来越流行。也就是一种标记语言。层次结构也特别简洁清晰 ,易于阅读和编写,同时也易于机器解析和生成。 golang的标准库中暂时没有给我们提供操作yaml的标准库,但是github上有很多优秀的第三方库开源给我们使用。 1. 创建 conf.yaml: enabled: true path: /usr/local 2. 下载第三方库:go getgopkg.in/yaml.v2 3. 创建 config_yaml.go: package main import ( "fmt" "io/ioutil" "log" "gopkg.in/yaml.v2" ) type conf struct { Enabled bool `yaml:"enabled"` //yaml:yaml格式 enabled:属性的为enabled Path string `yaml:"path"` } func (c *conf) getConf() *conf { yamlFile, err := ioutil.ReadFile("conf.yaml") if err != nil { log.Printf("yamlFile.Get err #%v ", err) } err = yaml.Unmarshal(yamlFile, c) if err != nil { log.Fatalf("Unmarshal: %v", err) } return c } func main() { var c conf c.getConf() fmt.Println("path:" + c.Path) } 启动运行后,输出如下: D:\Go_Path\go\src\configmgr>go run config_yaml.go path:/usr/local 最后 以上,就把golang 读取配置文件的方法,都介绍完了。大家可以拿着代码运行起来看看。