Python环境搭建—安利Python小白的Python和Pycharm安装详细教程
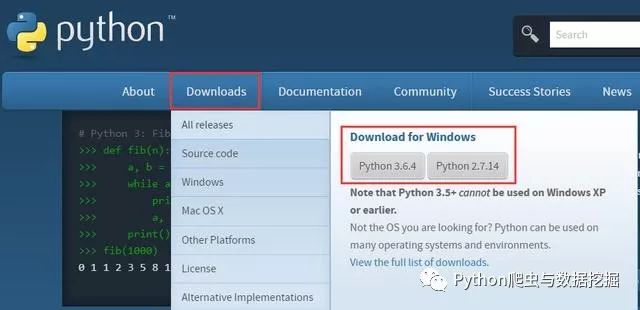
人生苦短,我用Python。众所周知,Python目前越来越火,学习Python的小伙伴也越来越多。最近看到群里的小伙伴经常碰到不会安装Python或者不知道去哪下载Python安装包等系列问题,为了方便大家学习Python,小编整理了一套Python和Pycharm安装详细教程,只要大家按照这个步骤来,就可以轻松的搞定Python和Pycharm的安装了。 Python具有跨平台性,它几乎可以在任何平台下运行,如:Windows/Unix/Linux等操作平台上。大部分的小伙伴用的是Windows,在此小编就以Windows平台为例,详解Python和Pycharm安装过程。注意:前方多图高能预警~~ 一、Python安装过程 工欲善其事,必先利其器。首先我们先来安装Python,在这里安利一下:其实在没有安装Python之前也可以安装Pycharm的,两者并没有什么冲突关系。但是话说回来,如果没有Python编译器,那么Pycharm其实只是个驱壳,即便你编好程序之后,也并不能运行。举个栗子,Python相当于子弹,Pycharm相当于手枪,如果手枪没有子弹的话,那它就没有走火的可能性。从逻辑上来讲,还是应该先安装Python的,具体流程如下: 1、首先进入Python的官网:https://www.python.org,之后选择下图框框内的文件进行下载: 当然你也可以直接进入网址:https://www.python.org/downloads/,选择对应的Windows安装包,进行文件下载即可,如下图所示: 2、下载Python。其中Python2和Python3版本都可以下载,两者是兼容的。在这里,小编以Python3版本的安装为例,下载后如下图所示: 3、安装Python。双击python-3.6.4.exe文件,之后按照框框内的指示进行选择,记得勾选两个框框,然后选择Customize installation进入到下一步: 4、之后进入以下的界面,默认即可,直接选择下一步: 5、之后进入下图界面,点击Browse可以进行自定义安装路径,千万要记得自己把它安装在哪个盘下面,当然你也可以直接点击Install进行默认安装,点击Install后便可以完成安装了。本例中,小编把它安装在C盘,之后点击Install,稍等片刻之后,便可以实现Python的安装了。(注意:要记得Python的安装路径) 在安装过程中如果弹出任何提示的话,选择确定或者允许操作就可以了。 6、安装完成之后在开始菜单中输入cmd命令,进入命令行窗口,然后在窗口中输入python进行验证。如果出现下面两张图的提示,就说明Python安装成功了。 如果你看到提示符>>>,就表示我们已经在Python交互式环境中了,此时你可以输入任何Python代码,回车后会立刻得到执行结果。现在,输入exit()并回车,就可以退出Python交互式环境(直接关掉命令行窗口也可以)。 7、如果出现下图的提示,则说明安装失败了: 出现这个错误的原因是因为你在安装的时候漏掉了勾选Add python.exe to Path这个选项,此时就要手动把刚刚安装所在的路径添加到Path中。如果你不知道怎么修改环境变量,建议把Python安装程序重新运行一遍,记得勾上Add python.exe to Path这个选项就可以顺利安装了。 接下来我们安装开发环境Pycharm,至于为神马选择Pycharm,可以戳这篇文章(企业级开发大佬告诉你学习Python需要用什么开发工具)。 二、Pycharm安装过程 1、首先去Pycharm官网,或者直接输入网址:http://www.jetbrains.com/pycharm/download/#section=windows,下载PyCharm安装包,根据自己电脑的操作系统进行选择,对于windows系统选择下图的框框所包含的安装包。 2、选择Windows系统的专业版,将其下载到本地,如下图所示: 3、双击下载的安装包,进行安装,然后会弹出界面: 4、选择安装目录,Pycharm需要的内存较多,建议将其安装在D盘或者E盘,不建议放在系统盘C盘: 5、点击Next,进入下图的界面: Create Desktop Shortcut创建桌面快捷方式,一个32位,一个64位,小编的电脑是64位系统,所以选择64位。 勾选Create Associations是否关联文件,选择以后打开.py文件就会用PyCharm打开。 6、点击Next,进入下图: 默认安装即可,直接点击Install。 7、耐心的等待两分钟左右,如下图: 8、之后就会得到下面的安装完成的界面: 9、点击Finish,Pycharm安装完成。接下来对Pycharm进行配置,双击运行桌面上的Pycharm图标,进入下图界面: 选择Do not import settings,之后选择OK,进入下一步。 10、选择Accept,进入下一步: 11、进入激活界面,选择第二个License server,如下图所示: 之后在License server address中随意输入下面两个注册码中的任意一个即可,Pycharm新注册码1:http://idea.liyang.io或pycharm新注册码2:http://xidea.online,之后点击OK,便可以激活Pycharm了。 12、Pycharm激活后 13、激活之后会自动跳转到下图界面,选择IDE主题与编辑区主题: 建议选择Darcula主题,该主题更有利于保护眼睛,而且看上去也非常不错~~~ 14、选择OK之后进入下图界面: 选择Yes即可,更换IDE主题。 15、之后进入下图界面: 16、点击Create New Project,进入如下图的界面: 自定义项目存储路径,IDE默认会关联Python解释器。选择好存储路径后,点击create。 17、IDE提供的提示,直接close即可,不用理会。 18、进入的界面如下图所示,鼠标右击图中箭头指向的地方,然后选择New,最后选择python file,在弹出的框中填写文件名(任意填写),本例填写:helloworld。 19、之后得到下图,然后点击OK即可: 20、文件创建成功后便进入如下的界面,便可以编写自己的程序了。 这个界面是Pycharm默认的界面,大家完全可以自己去setting中设置自己喜欢的背景和字体大小、格式等等。 在这里我就不一一赘述了,起码到这里我相信大家已经实现了Pycharm的安装了。 为了给大家创建一个学习Python的氛围,小编为大家建立了一个Python学习群: 181125776,里面有Python和Pycharm等开发工具的安装包和安装教程,可以免费分享给大家,让我们一起为学习Python而奋斗吧~~ 21、安利Pycharm中的部分快捷键 1、Ctrl + Enter:在下方新建行但不移动光标; 2、Shift + Enter:在下方新建行并移到新行行首; 3、Ctrl + /:注释(取消注释)选择的行; 4、Ctrl+d:对光标所在行的代码进行复制。 最后小编祝大家能够顺利的完成Python和Pycharm的安装,^_^祝大家周末愉快^_^