Linux运维工程师笔试题第十三套
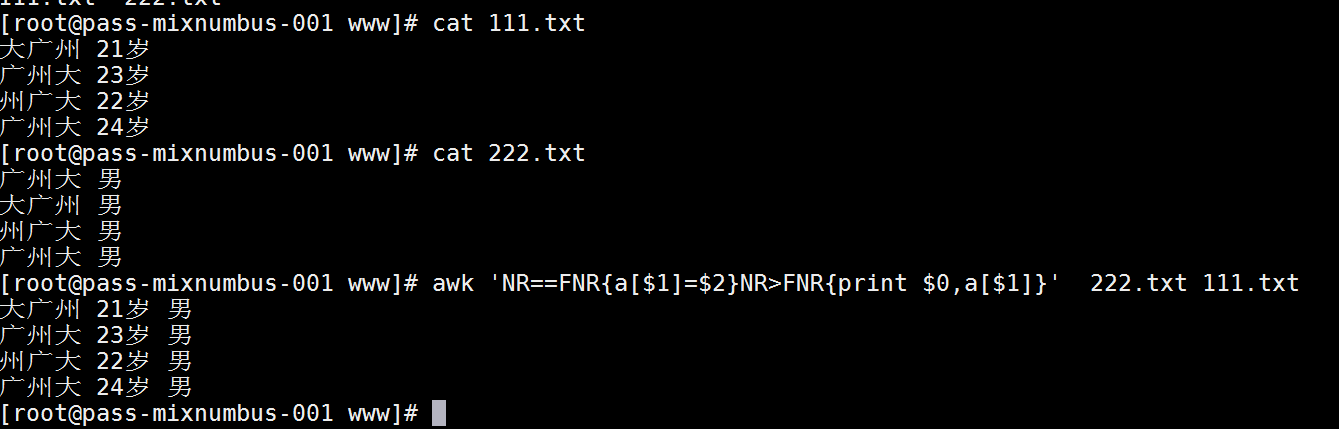
这套题的出处是http://blog.51cto.com/nolinux/1670406 ,看到了周末闲着没事就做一做,答案都是我结合自己的工作得到的,不一定百分百准确,现在拿出来跟各位分享一番。 1、请写出五种系统性能分析工具,并简述其作用和特点 [我的答案] top、free、vmstat、iostat、perf等等等等,如果你想装逼,可以回答fio,blktrace,oprofile。 具体的作用和特点这里不多说了,但是我着重要推荐vmstat,很实用很棒的一个命令。可以去移步看看https://rorschachchan.github.io/2018/01/03/从vmstat命令里看服务器瓶颈/这篇文章。 2、请写出web服务器的调优要点 [我的答案]以nginx为例,个人总结有如下几个要点: 1)尽可能的少用http,因为http是有开销的; 2)尽可能的使用CDN; 3)添加Expire/Cache-Control头,这个头是缓存用的,可以缓存图片和flash那样不轻易更改的文件,减少访问时间; 4)启动gzip压缩,这个没啥好说的了; 5)尽可能少的重定向,重定向是需要时间的,增加一次重定向就会多一次web需求; 6)如果可以,把ajax也做缓存; 7)减少dns查询,很多网页会有外站的广告,这些广告也是会启动dns查询的,所以如果不缺钱,减少这种广告; 8)调好服务器里的TCP协议栈,这个无论是web服务器还是应用服务器都是必须的; 3、请写出你知道或使用过的nginx扩展模块(注意标注知道和使用) [我的答案] 随便说几个我使用过的,这玩意到时候结合工作过的情况说说吧: Nginx负载均衡模块:nginx-upstream-fair 非阻塞访问redis模块:redis2-nginx-module 分布式图片实时动态压缩:ngx-fastdfs4、请简述你了解的自动化配置管理工具特点和运行原理 [我的答案]我用的最多的就是ansible和saltstack,这俩都是python的,对于我这个半路出家的更亲切。 ansible基于SSH协议传输数据,不用装agent,配置比较简单,对windows支持惨不忍睹; saltstack使用消息队列zeroMQ传输数据,如果1000台以上的话它速度比ansible还要快,要安装agent,对windows支持同样惨不忍睹; 5、目前,有一个文件,内容如下:172.16.100.1172.16.100.2172.16.100.3172.16.100.4 请使用while和ssh命令,登录文件内的ip并执行hostname命令 [我的答案]这个还真没有什么思路,不过我觉得是要搭配“<”输入重定向的吧。 PS,为啥不用ansible...哪怕pssh也可以啊! 6、请使用awk命令将如下两份文件中名字相同的两行合并起来 A文件:大广州 21岁广州大 23岁州广大 22岁广州大 24岁 B文件:广州大 男大广州 男州广大 男广州大 男 输出效果:`大广州 21岁 男` [我的答案]#awk 'NR==FNR{a[$1]=$2}NR>FNR{print $0,a[$1]}'B文件名A文件名 PS,做完这道题,我已经不认识“广”“州”这两个字了...7、请使用绘图的方式简述TCP/IP三次握手和四次断开的交互过程 [我的答案]这种图满大街都是了,我这个灵魂画师在这里就不污染各位的眼睛,不过这里推荐各位去看一篇文章:https://mp.weixin.qq.com/s?__biz=MjM5NzA1MTcyMA==&mid=2651160450&idx=2&sn=1128438fa5287b6cee503880698642b2&scene=21 对原理讲的浅显易懂。 多说一句,网易招聘java的时候也问这个问题,不过他们问的是“为什么要三次握手?” 8、请根据你的理解,简述高可用服务体系的相关组件,并列举该组件的具体实现服务名字 [我的答案] 我觉得这个题是要问一些架构上的东西,以我工作环境为例: 统一配置:zookeeper、Consul、Etcd+Confd(这俩比较常见于动态管理nginx) 前端展示:nginx 消息队列:activemq、kafka 读写分离中间件:atlas 日志分析:elk 简述我就不简了,自己百度一下。9、请根据你的理解,简述负载均衡的实现方式 [我的答案]负载均衡主要分为两种,硬件(F5)和软件(NGINX、Haproxy、LVS),硬件效果比较牛逼,它是把4-7层的负载均衡功能做到一个硬件里面,但是价格昂贵最近用的越来越少了。 软件的负载均衡又分两种,四层和七层:四层是在IP/TCP协议栈上把网络包的IP地址和端口进行修改,达到转发的目的;七层就是在应用层里把HTTP请求、URL等具体的应用数据发送到具体的服务器上。四层的效率比七层的高,四层一般安排在架构的前端,七层一般就是在具体服务器的前端。 软件负载均衡比较常见的几个分配方式如下: 轮询:访问请求依序分发给后端服务器; 加权轮询:访问请求依序分发后端服务器,服务器权重越高被分发的几率也越大; 最小连接数: 将访问请求分发给当前连接数最小的一台后端服务器,服务器权重越高被分发的几率也越大;10、请根据你的理解,简述数据迁移工具和数据存储服务有哪些以及相关特点 [我的答案]由于我公司主要都放在了阿里云,数据库用过的就这么几个:mysql、redis和elasticsearch。对于Storm和Hadoop这俩我还是初学者。 mysql:关系型数据库; elasticsearch:全文检索框架,这玩意逐渐向一个数据库靠拢了; redis:键值储存数据库; mysql的数据迁移最常见的就是mysqldump,但是要注意使用不当会锁表; redis的数据迁移最稳妥的方法就是主从同步:在slave端启动redis,然后执行#slaveof master机器IP地址 6379,然后使用#info的时候查看#master_link_status如果是up那就是OK了,再执行#slaveof no one,提示OK就是OK了; Elasticsearch的数据迁移工具就是Elasticsearch-Exporter,不过我对它仅仅只是了解,用的并不多; 最后的最后,如果您觉得本文对您升职加薪有帮助,那么请不吝赞助之手,刷一下下面的二维码,赞助本人继续写更多的博文! 本文转自 苏幕遮618 51CTO博客,原文链接:http://blog.51cto.com/chenx1242/2058818