感受野是卷积神经网络里面最重要的概念之一,为了更好地理解卷积神经网络结构,甚至自己设计卷积神经网络,对于感受野的理解必不可少。
一、定义
感受野被定义为卷积神经网络特征所能看到输入图像的区域,换句话说特征输出受感受野区域内的像素点的影响。
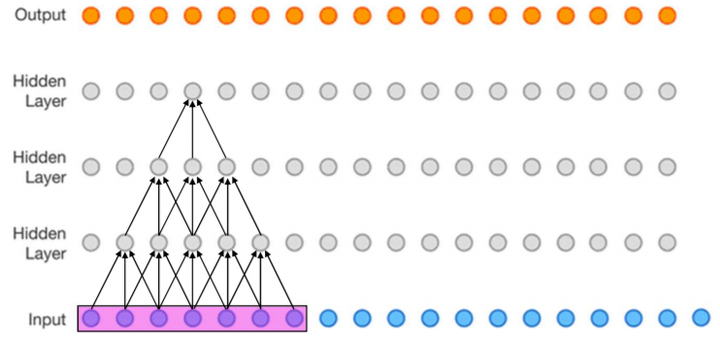
比如下图(该图为了方便,将二维简化为一维),这个三层的神经卷积神经网络,每一层卷积核的 ![kernel\_size=3]() ,
, ![stride=1]() ,那么最上层特征所对应的感受野就为如图所示的7x7。
,那么最上层特征所对应的感受野就为如图所示的7x7。
![v2-0d5f2bd822621d3689a105cc17e75111_hd.j]()
感受野示例[1]
二、计算方式
![RF_{l+1}=RF_{l}+(kernel\_size_{l+1}-1)\times feature\_stride_{l}]()
其中 ![RF]() 表示特征感受野大小,
表示特征感受野大小, ![l]() 表示层数,
表示层数, ![feature\_stride_l=\prod_{i=1}^{l}stride_i]() ,
, ![l=0]() 表示输入层,
表示输入层, ![RF_{0}=1]() ,
, ![feature\_stride_0=1]() 。
。
![RF_{1}=RF_{0}+(kernel\_size_{1}-1)\times feature\_stride_{0}=1+(3-1)\times 1=3]()
![v2-59143068c39a7e0e245d8560e9d38ab6_hd.j]()
第1层感受野[1]
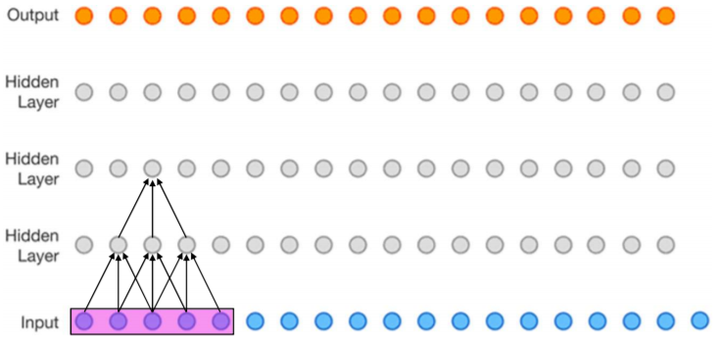
![RF_{2}=RF_{1}+(kernel\_size_{2}-1)\times feature\_stride_{1}=3+(3-1)\times 1=5]()
![v2-4763bc767d0296e74a6827d457eb1360_hd.j]()
第2层感受野[1]
![RF_{3}=RF_{2}+(kernel\_size_{3}-1)\times feature\_stride_{2}=5+(3-1)\times 1=7]()
![v2-0d5f2bd822621d3689a105cc17e75111_hd.j]()
第3层感受野[1]
如果有dilated conv的话,计算公式为
![RF_{l+1}=RF_{l}+(kernel\_size_{l+1}-1)\times feature\_stride_{l}\times (dilation_{l+1})]()
三、更上一层楼
上文所述的是理论感受野,而特征的有效感受野(实际起作用的感受野)实际上是远小于理论感受野的,如下图所示。具体数学分析比较复杂,不再赘述,感兴趣的话可以参考论文[2]。
![v2-635e3507b91af40f21667cf60913cbd0_hd.j]()
有效感受野示例[2]
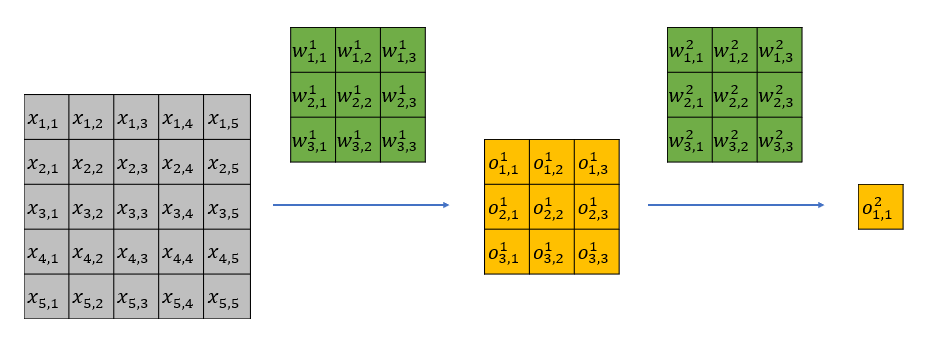
下面我从直观上解释一下有效感受野背后的原因。以一个两层 ![kernel\_size=3]() ,
, ![stride=1]() 的网络为例,该网络的理论感受野为5,计算流程可以参加下图。其中
的网络为例,该网络的理论感受野为5,计算流程可以参加下图。其中 ![x]() 为输入,
为输入, ![w]() 为卷积权重,
为卷积权重, ![o]() 为经过卷积后的输出特征。
为经过卷积后的输出特征。
很容易可以发现, ![x_{1,1}]() 只影响第一层feature map中的
只影响第一层feature map中的 ![o_{1,1}^1]() ;而
;而 ![x_{3,3}]() 会影响第一层feature map中的所有特征,即
会影响第一层feature map中的所有特征,即 ![o_{1,1}^1,o_{1,2}^1,o_{1,3}^1,o_{2,1}^1,o_{2,2}^1,o_{2,3}^1,o_{3,1}^1,o_{3,2}^1,o_{3,3}^1]() 。
。
第一层的输出全部会影响第二层的 ![o_{1,1}^2]() 。
。
于是 ![x_{1,1}]() 只能通过
只能通过 ![o_{1,1}^1]() 来影响
来影响 ![o_{1,1}^2]() ;而
;而 ![x_{3,3}]() 能通过
能通过 ![o_{1,1}^1,o_{1,2}^1,o_{1,3}^1,o_{2,1}^1,o_{2,2}^1,o_{2,3}^1,o_{3,1}^1,o_{3,2}^1,o_{3,3}^1]() 来影响
来影响 ![o_{1,1}^2]() 。显而易见,虽然
。显而易见,虽然 ![x_{1,1}]() 和
和 ![x_{3,3}]() 都位于第二层特征感受野内,但是二者对最后的特征
都位于第二层特征感受野内,但是二者对最后的特征 ![o_{1,1}^2]() 的影响却大不相同,输入中越靠感受野中间的元素对特征的贡献越大。
的影响却大不相同,输入中越靠感受野中间的元素对特征的贡献越大。
![v2-0cc04fa062844f53ea707c67094c9645_hd.j]()
两层3x3 conv计算流程图
四、应用
Xudong Cao写过一篇叫《A practical theory for designing very deep convolutional neural networks》的technical report,里面讲设计基于深度卷积神经网络的图像分类器时,为了保证得到不错的效果,需要满足两个条件:
Firstly, for each convolutional layer, its capacity of learning more complex patterns should be guaranteed; Secondly,
the receptive field of the top most layer should be no larger than the image region.
其中第二个条件就是对卷积神经网络最高层网络特征感受野大小的限制。
现在流行的目标检测网络大部分都是基于anchor的,比如SSD系列,v2以后的yolo,还有faster rcnn系列。
基于anchor的目标检测网络会预设一组大小不同的anchor,比如32x32、64x64、128x128、256x256,这么多anchor,我们应该放置在哪几层比较合适呢?这个时候感受野的大小是一个重要的考虑因素。
放置anchor层的特征感受野应该跟anchor大小相匹配,感受野比anchor大太多不好,小太多也不好。如果感受野比anchor小很多,就好比只给你一只脚,让你说出这是什么鸟一样。如果感受野比anchor大很多,则好比给你一张世界地图,让你指出故宫在哪儿一样。
《S3FD: Single Shot Scale-invariant Face Detector》这篇人脸检测器论文就是依据感受野来设计anchor的大小的一个例子,文中的原话是
we design anchor scales based on
the effective receptive field
《FaceBoxes: A CPU Real-time Face Detector with High Accuracy》这篇论文在设计多尺度anchor的时候,依据同样是感受野,文章的一个贡献为
We introduce the Multiple Scale Convolutional Layers
(MSCL) to handle various scales of face via
enriching
receptive fields and discretizing anchors over layers
引用:
[1]convolutional nerual networks
[2]Understanding the Effective Receptive Field in Deep Convolutional Neural Networks
推荐阅读:
关注SIGAICN公众号,回复文章获取码,即可获得全文链接
[1] 机器学习-波澜壮阔40年 【获取码】SIGAI0413.
[2] 学好机器学习需要哪些数学知识?【获取码】SIGAI0417.
[3] 人脸识别算法演化史 【获取码】SIGAI0420.
[4] 基于深度学习的目标检测算法综述 【获取码】SIGAI0424.
[5] 卷积神经网络为什么能够称霸计算机视觉领域?【获取码】SIGAI0426.
[6] 用一张图理解SVM的脉络 【获取码】SIGAI0428.
[7] 人脸检测算法综述 【获取码】SIGAI0503.
[8] 理解神经网络的激活函数 【获取码】SIGAI0505.
[9] 深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读 【获取码】SIGAI0508.
[10] 理解梯度下降法 【获取码】SIGAI0511.
[11] 循环神经网络综述—语音识别与自然语言处理的利器 【获取码】SIGAI0515.
[12] 理解凸优化 【获取码】SIGAI0518.
[13] 【实验】理解SVM的核函数和参数 【获取码】SIGAI0522.
[14] 【SIGAI综述】行人检测算法 【获取码】SIGAI0525.
[15] 机器学习在自动驾驶中的应用—以百度阿波罗平台为例(上)【获取码】SIGAI0529.
[16] 理解牛顿法 SIGAI 2018.5.31
[17] 【群话题精华】5月集锦—机器学习和深度学习中一些值得思考的问题 【获取码】SIGAI0601.
[18] 大话Adaboost算法 【获取码】SIGAI0602.
[19] FlowNet到FlowNet2.0:基于卷积神经网络的光流预测算法 【获取码】SIGAI0604.
[20] 理解主成分分析(PCA)【获取码】SIGAI0606.
[21] 人体骨骼关键点检测综述 【获取码】SIGAI0608.
[22] 理解决策树 【获取码】SIGAI0611.
[23] 用一句话总结常用的机器学习算法 【获取码】SIGAI0613.
[24] 目标检测算法之YOLO 【获取码】SIGAI0615.
[25] 理解过拟合 【获取码】SIGAI0618.
[26] 理解计算:从√2到AlphaGo ——第1季 从√2谈起 【获取码】SIGAI0620.
[27] 场景文本检测——CTPN算法介绍 【获取码】SIGAI0622.
[28] 卷积神经网络的压缩和加速 【获取码】SIGAI0625.
[29] k近邻算法 【获取码】SIGAI0627.
[30] 自然场景文本检测识别技术综述 【获取码】SIGAI0629.
[31] 理解计算:从√2到AlphaGo ——第2季 神经计算的历史背景 【获取码】SIGAI0702.
[32] 机器学习算法地图 【获取码】SIGAI0704.
[33]反向传播算法推导-全连接神经网络【获取码】SIGAI0706.
[34]生成式对抗网络模型综述【获取码】SIGAI0709.
[35]怎样成为一名优秀的算法工程师【获取码】SIGAI0711.
[36] 理解计算:从√2到AlphaGo ——第3季 神经网络的数学模型【获取码】SIGAI0702.
[37] 人脸检测算法之S3FD 【获取码】SIGAI6
[38]基于深度负相关学习的人群计数方法 【获取码】SIGAI0718
[39] 流形学习概述 【获取码】SIGAI0723
 感受野示例[1]
感受野示例[1]
 第1层感受野[1]
第1层感受野[1]
 第2层感受野[1]
第2层感受野[1]
 有效感受野示例[2]
有效感受野示例[2]
 两层3x3 conv计算流程图
两层3x3 conv计算流程图
