高并发业务除了需要有支撑高并发的服务器架构,还需要根据业务需求和架构体系。
.
设计出合理的开发方案,这里根据一个实践过业务场景分析开发思路,罗列出高并发接口需要注意的点,以及设计上的巧思,共勉之,望共鸣
.
业务场景
业务:今日好货
.
交互端:IOS/Andorid
.
需求点:(实际业务会复杂些,为了容易理解,这里简化需求点)
提供最新的好货商品信息列表,支持分页
.
需要时时获取最新的商品数据列表,以下情况商品信息会发生变化
● 品数据字段更新(人为编辑,热度字段更新,等)
● 不定时上新,在固定时段会有大量商品更新(目前 10点/20点上新量大)
● 商品在会在规律时间里重新排序(根据:销量,曝光量,点击量 等计算排序)
.
商品加载过程中不能出现重复商品
.
客户端和服务端需要考虑加载商品的交互体验
.
终极目标:
支持高并发下业务稳定
.
设计思路
.
前提:
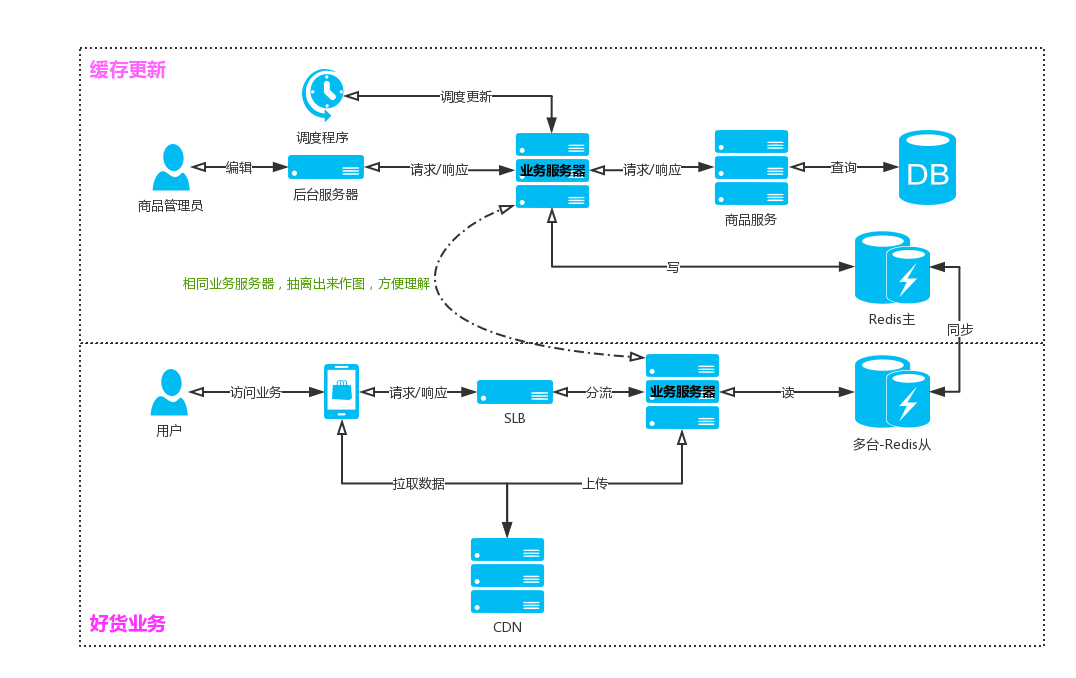
【商品服务API】:通过商品服务提供的API获取商品数据,当商品有上新、字段更新、排序有更新时,通过API都可以获取到最新的数据(db查询,支持获取未来时间里的商品数据)
.
缓存使用 Redis
.
缓存更新分析:
● 商品数据缓存到Redis:支撑高并发的查询业务,数据需要进行缓存
.
● 提供商品缓存刷新接口:商品显示需要即时性,需要时时展示最新数据,当商品发生变化的时候,我们需要刷新商品缓存数据
.
● 支持未来时间缓存提前更新:为了更好支撑即时性,尤其在固定时段商品的大量上新,缓存更新会比较慢,所以我们需要提前备好未来时间的缓存数据
.
● 缓存刷新需要注意点:缓存更新的过程中不能出现前台无数据展示的情况
.
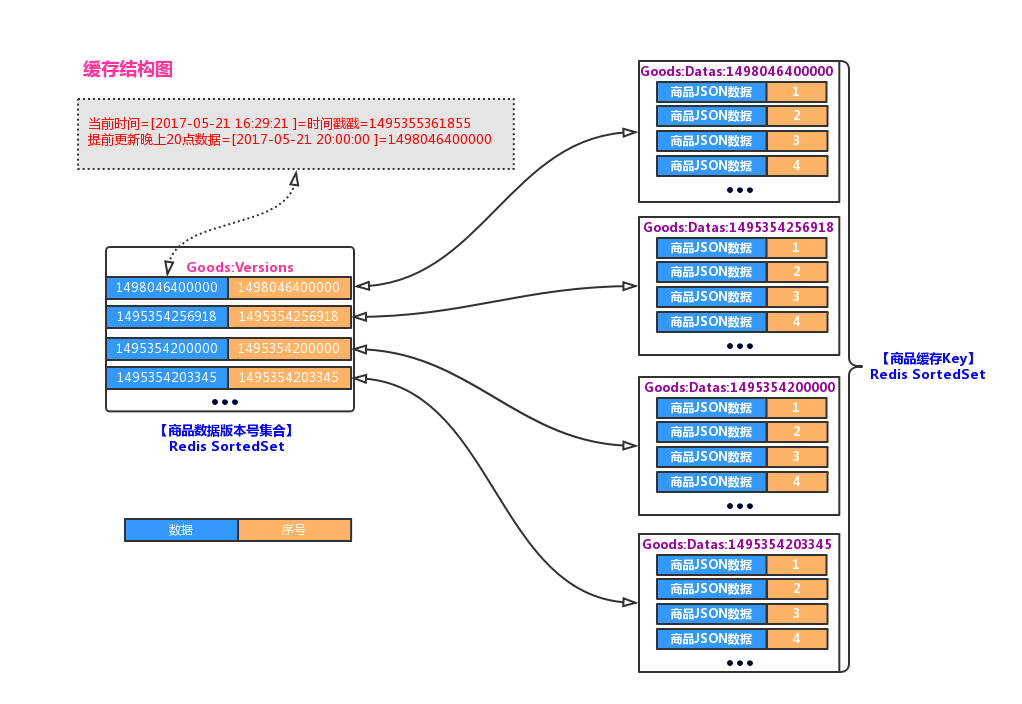
● 商品缓存支持版本号区分:每次缓存更新都要生成一个新的数据版本号缓存Key,数据存储在对应的缓存版本Key里
.
● 缓存版本Key存储到列表 :列表可以用来筛选出当前时间可以使用的最新版本号
.
商品缓存更新设计:
接口参数:updatetime【更新时间】(可空),默认等于当前时间,可以传未来时间
.
每次刷新缓存都会生成新的数据版本号作为【商品缓存Key名】,将数据存到版本号对应的缓存Key中,所以需要生成一个唯一字符串,这里我们把【更新时间】的时间戳作为缓存的Key名,为何这么设计,后面会介绍到
.
首先请求【商品服务API】获取【更新时间】对应的商品数据,接着对数据进行字段处理、排序,最后把最终商品数据更新到【商品缓存Key名】的Redis SortedSet中
.
商品缓存成功后,把【商品缓存Key名】存到【版本号集合】Redis SortedSet中,同时把【更新时间】的时间戳作为排序的值
.
【商品缓存Key名】=【更新时间】的时间戳,这个设计的目的是可以支持未来时间版本数据的提前更新,并且可以通过SortedSet排序,过滤出当前时间最新的版本号
.
缓存结构图
![]()
.
今日好货API设计:
接口参数:version:数据版本号(可空),pageindex:页码
.
响应JSON数据:Datas:商品数据集合,CurrentVersion:当前数据版本号
.
【当前最新版本号】:【版本号集合】通过SortedSet机制,获取当前时间能够使用的数据版本号,
如:取[当前时间戳]-[(当前时间-1h)时间戳]区间的版本号,排序后获取离当前时间最近的版本号作为最新版本号 <这里为何取区间,而不是直接取最新版本号,会有个容错处理,后面会说到>
.
用户在浏览商品的时候客户端请求【今日好货API】需要上传版本号和页数,如果是第一次(pageindex=1,首页),会获取【当前最新版本号】,然后返回最新商品数据
.
客户端本地缓存首页数据返回的版本号,后续翻页需要客户端上报缓存的版本号,API返回版本号对应的商品分页数据,这样设计的目的是当用户继续加载后面页数数据的时候不会出现重复的数据(数据会不定时更新,避免用户加载到重复的数据,如:商品A原来是第一页数据,数据更新后变成第二页数据)
.
当请求首页数据,客户端上报的版本号=【当前最新版本号】,就不进行数据缓存查询,直接返回空数据(数据不变),客服端无需重新渲染商品列表,同时可以避免无限下拉刷新带来的服务器压力
.
如果version参数没有上传,获取【当前最新版本号】和当前最新数据返回,数据版本号参数有上传,就获取对应版本号的分页数据
.
其他注意点:
.
版本号无限累加
【版本号集合】随着时间增长,版本号数据会不断累加,需要在每次更新的时候删除掉最近一天的版本,操作 SortedSet 过滤掉比(当前时间-1天)的时间戳小的版本号
.
容错处理
获取【当前最新版本号】的时候,操作 【版本号集合】集合,获取最近一个小时的,即操作SortedSet[当前时间戳]至[(当前时间-1h)时间戳]范围内的版本号,然后从大到小排序版本号,过滤出版本号,并且有版本号相对于的商品数据,如果不存在商品数据,就往下遍历,直到有符合规则的版本号返回
.
双11模式:
.
一级缓存
将商品数据短暂的缓存到站点服务区Cache中
.
降级方案:
.
● 资源监控,自动降级
● 开启降级方案后,客服端会从cdn中拉取商品数据
● 商品分页数据生成JSON数据文件存储到cdn中
.
架构图
![]()
.
总结
以上举例的高并发接口设计的实践方案,有些设计可能比较针对此业务场景,但是思路是有共性的,重点在于理解设计上的思路
.
高并发接口的开发需要考虑因素:
● 接口性能
● 接口的稳定
● 容错机制
● 服务端压力:竟可能减少服务端压力,可以与客户端交互配合
● 服务降级:资源高压力的情况下进行降级
.
有任何想说的请留言哦
转载请申明原文地址,谢谢合作
.
感谢你的支持,我会继续努力!~
![支付宝]()