用户多,不代表你服务器访问量大,访问量大不一定你服务器压力大!我们换成专业点的问题,高并发下怎么优化能避免服务器压力过大?
1,整个架构:可采用分布式架构,利用微服务架构拆分服务部署在不同的服务节点,避免单节点宕机引起的服务不可用!
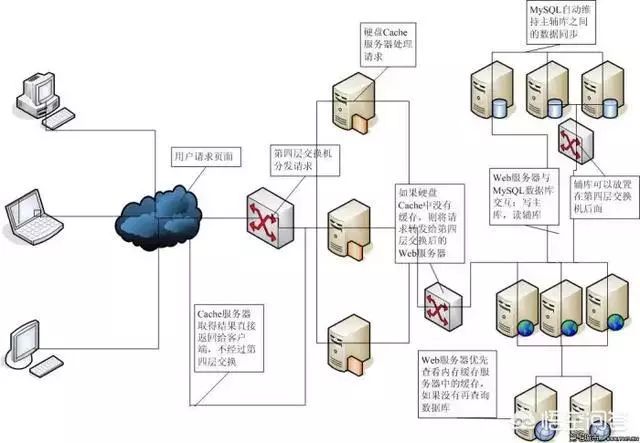
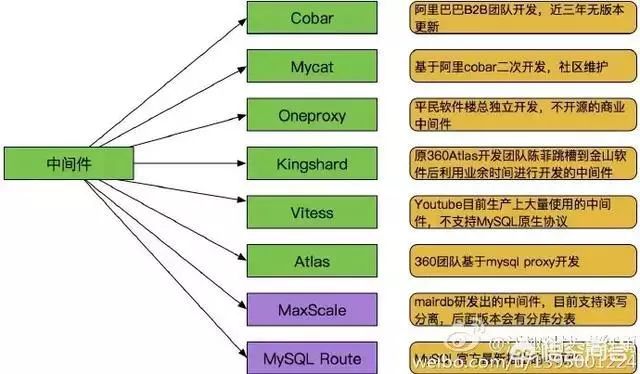
2,数据库:采用主从复制,读写分离,甚至是分库分表,表数据根据查询方式的不同采用不同的索引比如b tree,hash,关键字段加索引,sql避免复合函数,避免组合排序等,避免使用非索引字段作为条件分组,排序等!减少交互次数,一定不要用select *!
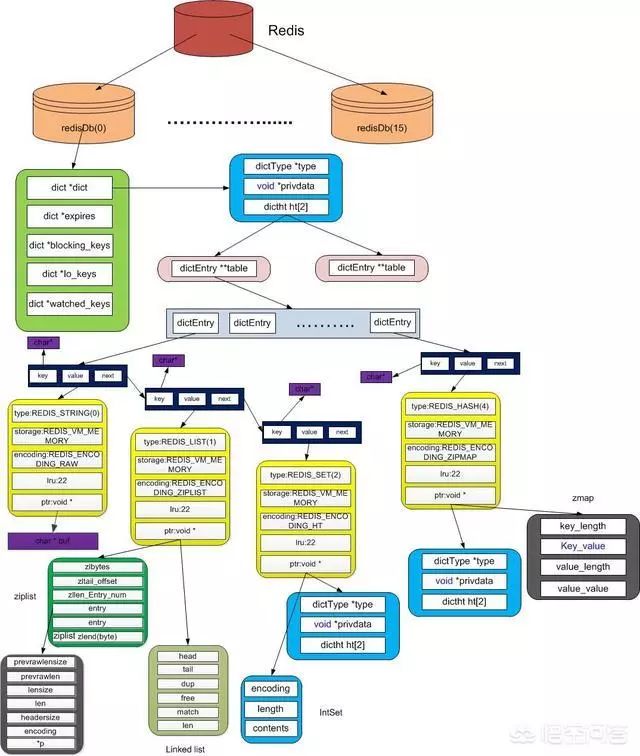
3,加缓存:使用诸如memcache,redis,ehcache等缓存数据库定义表,结果表等等,数据库的中间数据放缓存,避免多次访问修改表数据!登录信息session等放缓存实现共享!诸如商品分类,省市区,年龄分类等不常改变的数据,放缓存,不要放数据库!
同时要避免缓存雪崩和穿透等问题的出现导致缓存崩溃!
4,增量统计:不要实时统计大量的数据,应该采用晚间定时任务统计,增量统计等方式提前进行统计,避免实时统计的内存,CPU压力!
5,加图片服务器:图片等大文件,一定要单独经过文件服务器,避免IO速度对动态数据的影响!保证系统不会因为文件而崩溃!
6,HTML文件,枚举,静态的方法返回值等静态化处理,放入缓存!
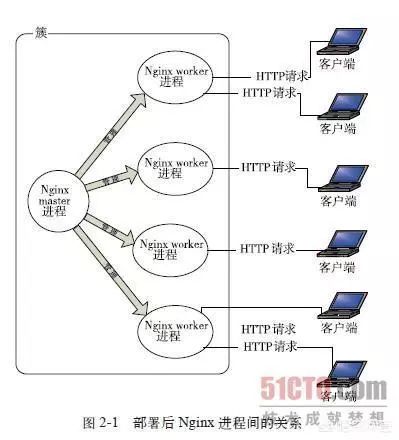
7,负载均衡:使用nginx等对访问量过大的服务采用负载均衡,实现服务集群,提高服务的最大并发数,防止压力过大导致单个服务的崩溃!
8,加入搜索引擎:对于sql中常出现的like,in等语句,使用lucence或者solr中间件,将必要的,依赖模糊搜索的字段和数据使用搜索引擎进行存储,提升搜索速度!#注意:全量数据和增量数据进行定时任务更新!
9,使用消息中间件:对服务之间的数据传输,使用诸如rabbit mq,kafka等等分布式消息队列异步传输,防止同步传输数据的阻塞和数据丢失!
10,抛弃tomcat:做web开发,接触最早的应用服务器就是tomcat了,但是tomcat的单个最大并发量只能不到1w!采取netty等actor模型的高性能应用服务器!
11,多线程:现在的服务器都是多核心处理模式,如果代码采用单线程,同步方式处理,极大的浪费了CPU使用效率和执行时间!
12,避免阻塞:避免bio,blockingqueue等常常引起长久阻塞的技术,而改为nio等异步处理机制!
13,CDN加速:如果访问量实在过大,可根据请求来源采用CDN分流技术,避免大流量完成系统崩溃!
14,避免低效代码:不要频繁创建对象,引用,少用同步锁,不要创建大量线程,不要多层for循环!
当然还有更多的细节优化技术!
欢迎工作一到五年的Java工程师朋友们加入Java架构开发:860113481
群内提供免费的Java架构学习资料(里面有高可用、高并发、高性能及分布式、Jvm性能调优、Spring源码,MyBatis,Netty,Redis,Kafka,Mysql,Zookeeper,Tomcat,Docker,Dubbo,Nginx等多个知识点的架构资料)合理利用自己每一分每一秒的时间来学习提升自己,不要再用"没有时间“来掩饰自己思想上的懒惰!趁年轻,使劲拼,给未来的自己一个交代!