字节跳动 Seed 宣布正式推出原生全双工语音大模型 Seeduplex。相比于上一代半双工豆包端到端语音模型,Seeduplex 基于“边听边说”的全新框架设计,交互体验的自然感、顺畅度大幅提升。
赋予模型更自然的对话节奏和更出色的抗干扰能力——不再是简单的一问一答,而是能在噪声与无关人声的干扰下精准响应,做到快慢有度、收放自如。
具体来说,通过模型架构创新与训练优化,并攻克高并发下的卡顿与稳定性等工程挑战,Seeduplex 实现了业界领先的全双工语音实时交互效果,其在保持模型智能上限与超低时延的同时,重点实现了以下两项突破:
- 精准抗干扰:模型具备持续的“倾听”能力,从而能更好地理解用户所处的声学环境,准确忽略背景噪音和无关对话。在复杂场景下,相比半双工模型,其误回复率和误打断率减少了一半。
- 动态判停:模型能联合语音和语义特征,综合判断用户意图,可实现更自然的对话节奏控制。面对用户的思考犹豫,模型能耐心倾听;在用户说完后,又能快速响应。相比半双工模型,其抢话比例相对下降了 40%。
目前,Seeduplex 已在豆包 App 全量上线。
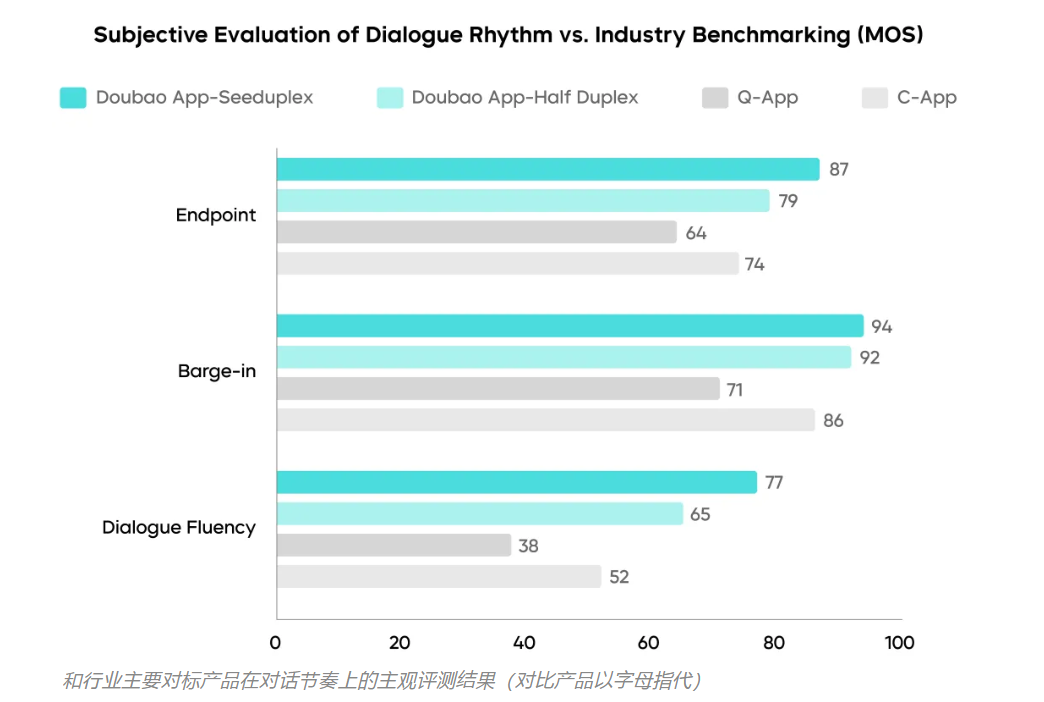
多维度评测显示,Seeduplex 在对话的流畅度和节奏感上,均显著优于传统的半双工方案及行业主流 App 的语音通话功能;在判停表现上,模型相比半双工方案提升了 8%,展现出更接近自然对话的分寸感。
为支撑模型在豆包 App 上全面上线,团队在模型框架设计、算法优化、工程性能与稳定性方面进行了大量优化:
- 模型框架设计:构建更贴合语音实时对话原生特性的模型架构,使模型能够直接从数据中学习语音与语义的一体化表达和节奏控制,显著提升交互自然度。
- 算法与训练:依托海量语音数据进行大规模预训练,并通过多能力、多任务的后训练体系,实现对话智能、超低延迟、对话节奏控制、强抗干扰能力与指向性理解等多维能力的协同优化,使模型具有稳定、高效、自然的交互表现。
- 推理性能:通过投机采样、量化等方式极致优化性能,实现成本和延迟的平衡。
- 服务稳定性:重点解决了收音、播报卡顿等问题,确保模型可在大流量环境下连续稳定运行。
相比此前上线豆包的半双工模型,Seeduplex 在用户的通话时长、留存等核心指标上均实现正向提升,整体通话满意度绝对值提升了 8.34%,用户反馈中“抢话”、“响应慢”、“误打断”等问题的提及比例明显下降。
测评结果显示,Seeduplex 在打断与判停表现上均显著优于半双工模型,并在多项关键指标上处于行业领先水平。相比豆包 App 之前使用的半双工对话框架,Seeduplex 的整体交互体验进一步提升,其判停 MOS 分提高了 8%,对话流畅度 MOS 分提升了 12%。
具体来说,Seeduplex 将判停延迟降低约 250ms 的同时,复杂场景下的 AI 抢话比例相对减少 40%;针对用户的打断需求,在响应准确率更高的前提下,Seeduplex 将打断响应的延迟进一步缩短了约 300ms;在复杂声学干扰场景下,Seeduplex 将误回复率和误打断率降低了一半。
另外,通过与原半双工模型以及行业主流 App 语音通话功能的横向对比,Seeduplex 在判停、打断响应任务上展现出明显优势,并显著提升了评测用户对整体交互节奏是否合理的对话流畅度评价。
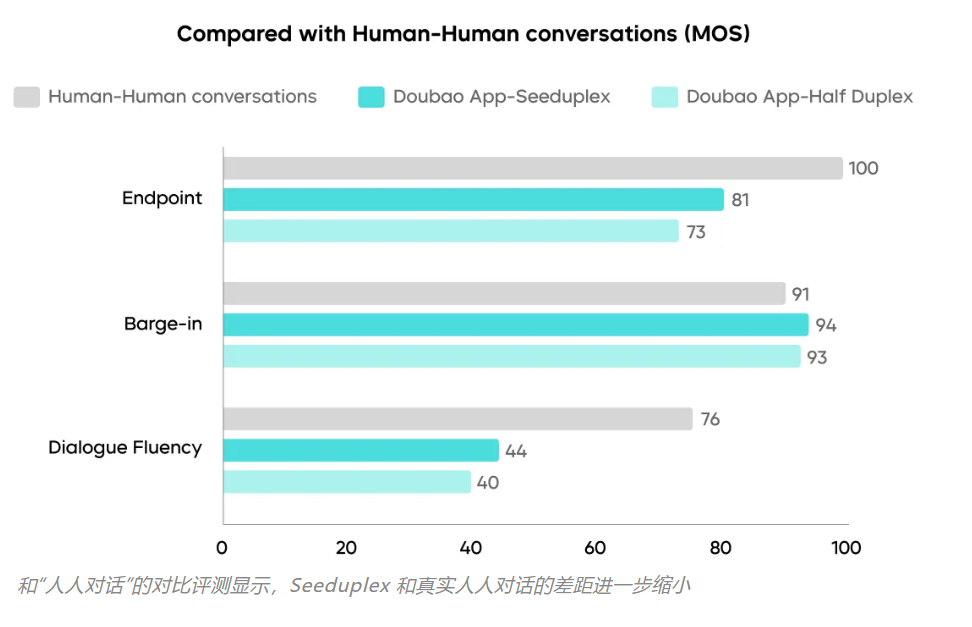
项目团队还通过组织真人对话测试,初步摸底了目前人机对话相对真实人人对话(普通人群)的水位。结果显示,以“人人对话”为基准,Seeduplex 在判停表现上相比半双工方案显著提升了 8%。而在响应打断的表现上,真实人人对话有时在响应上相对滞后,Seeduplex 则表现更稳定,略好于人人对话的平均水平。但在整体对话流畅度上,Seeduplex 和真实人人对话仍有不小差距,有待进一步提升。
接下来,其还计划在以下几个方面继续突破:
- 继续提升模型的音频理解能力,深度优化在多人对话、智能硬件等复杂交互场景中的表现。
- 通过数据 Scaling 和算法优化,持续提升模型的对话节奏多样性和控制能力。
- 在“边听边说”的基础上,引入模型主动能力,如在倾听的过程中附和用户、结合声学环境和对话语境主动交互。
- 实现更深度的多模态融合,在现有语音、文本模态的基础上引入视觉模态,实现“边听、边看、边说”的多维协同。
- 实现感知、思考、输出一体化,进一步探索“边听边想”、“边听边搜”等方案,让模型具备更深度的思考和执行能力,继续提升语音交互的流畅度。
