继开源 LingBot-Depth、LingBot-VLA 及 LingBot-World 后,蚂蚁灵波科技宣布开源具身世界模型 LingBot-VA。目前,LingBot-VA 的模型权重、推理代码已全面开源。
根据介绍,LingBot-World 通过在仿真或真实数据中学习世界的动态规律,构建一个可预测的“内部世界”。首次提出自回归视频-动作世界建模框架,将大规模视频生成模型的能力与机器人控制深度融合,模型在生成“下一步世界状态”的同时,直接推演并输出对应的动作序列,使机器人能够像人一样“边推演、边行动”。
LingBot-VA 的核心思想,是构建一个统一的、自回归的视频-动作生成模型。在每一个时间步,模型不仅要根据历史信息预测出下一帧的视频画面(Video),还要同步生成驱动机器人执行该画面的动作指令(Action)。
核心架构与机制
-
Mixture-of-Transformers (MoT) 架构:采用 MoT 架构,实现了视频处理与动作控制两种模态的深度融合与协同处理。
-
闭环推演机制:为了避免模型在连续生成中偏离物理现实(即“幻觉”),LingBot-VA 在每一步生成时,都会将真实世界传感器(如摄像头)的实时反馈纳入考量,形成一个“预测-执行-感知-修正”的闭环,确保持续生成的画面与动作始终与物理现实对齐。
-
异步推理与持久化:为了突破大规模视频模型在机器人端侧部署的算力瓶颈,设计了异步推理管线,将动作预测与电机执行并行化处理。同时,引入基于记忆缓存的持久化机制与噪声历史增强策略,使得模型在推理时仅需更少的生成步骤,即可输出稳定、精确的动作指令。
这一系列设计,使得 LingBot-VA 在拥有大模型深刻理解能力的同时,也具备了在真实机器人上进行低延迟控制的响应速度。
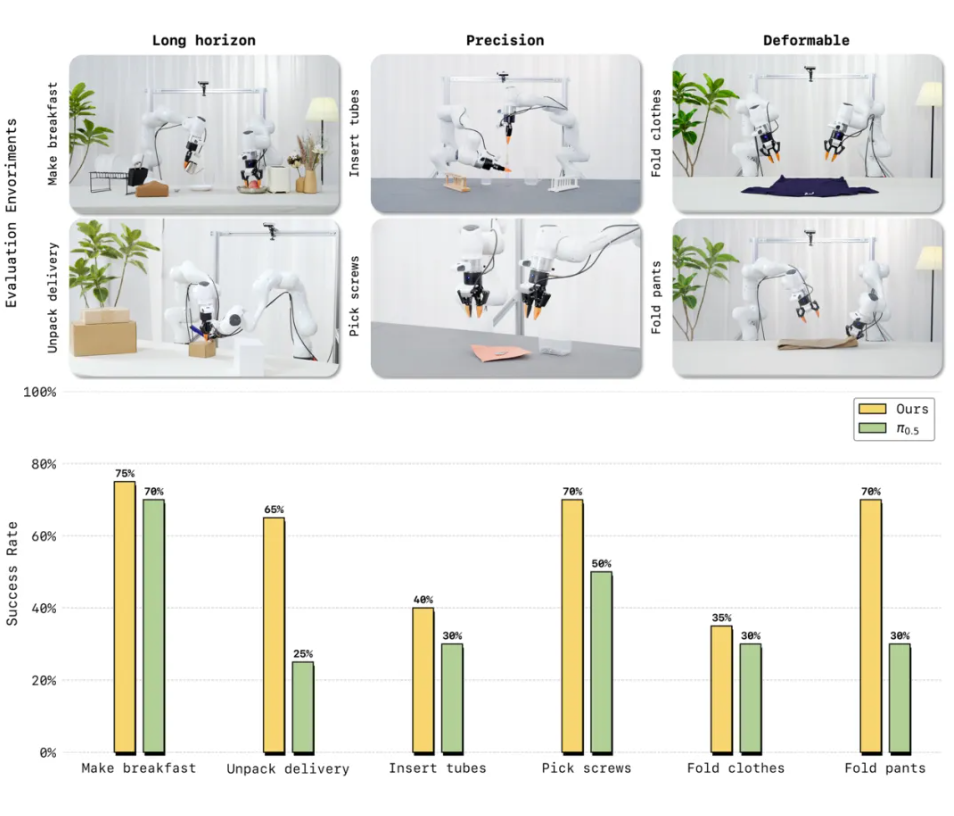
在多项真实机器人评测中,LingBot-VA 展现出对复杂物理交互的强适应能力。面对长时序任务(制作早餐、拾取螺丝)、高精度任务(插入试管、拆快递)以及柔性与关节物体操控(叠衣物、叠裤子)这三大类六项高难度挑战,仅需 30~50 条真机演示数据即可完成适配,且任务成功率相较业界强基线 Pi0.5 平均提升20%。
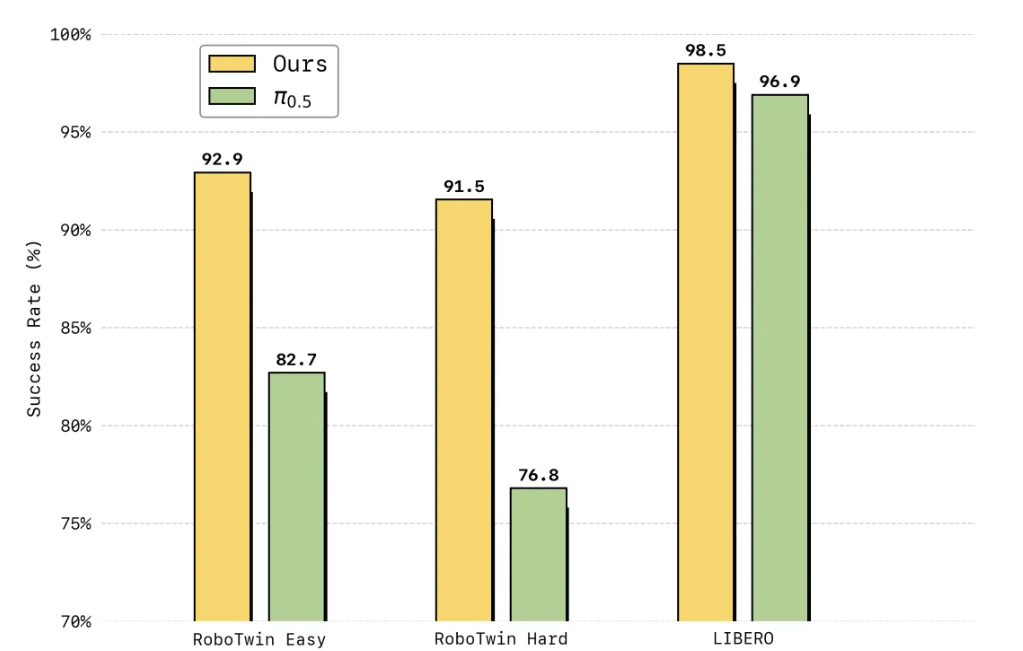
在仿真评测中,LingBot-VA 在高难度双臂协同操作基准 RoboTwin 2.0 上首次将成功率提升至超过 90%,在长时序终身学习基准 LIBERO 上达到 98.5% 平均成功率,均刷新了行业纪录。