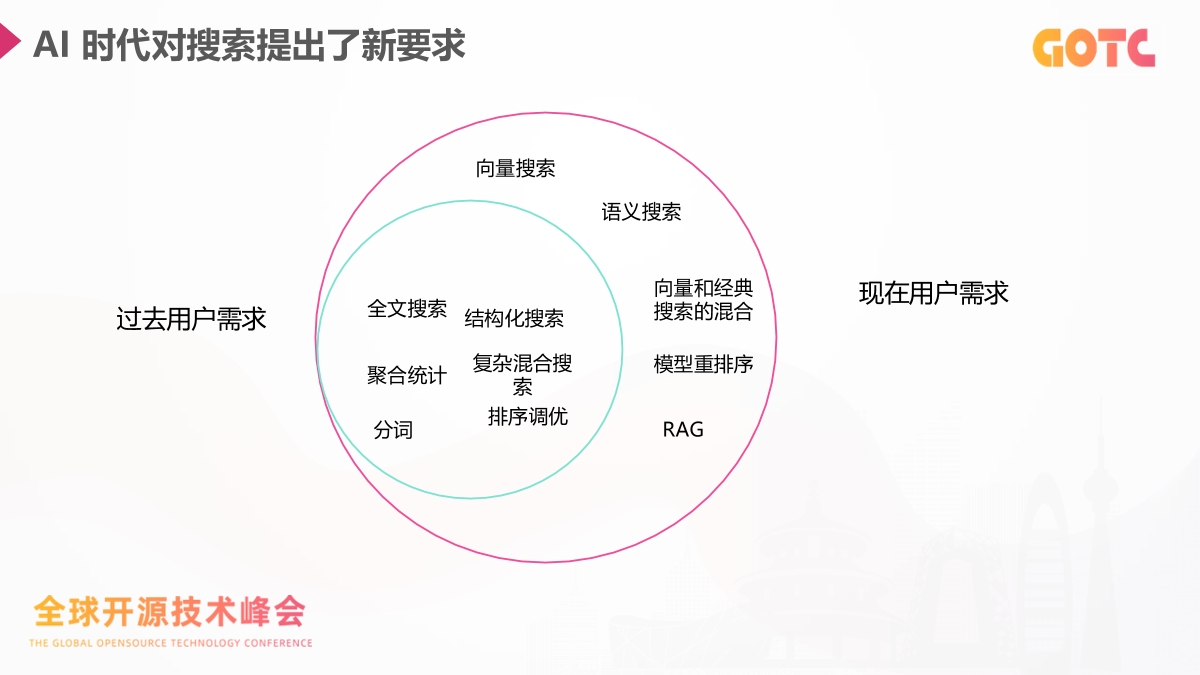
在生成式 AI 已经深入业务的今天,搜索系统的角色正在发生很明显的变化。用户对搜索的期望不再局限于关键词匹配,而是希望系统具备语义理解、多模态处理以及实时推理能力。传统的全文检索依旧是基础,但很难覆盖这些新需求,搜索逐渐成为 AI 应用的核心底座。
Elastic 中国首席布道师刘晓国在 GOTC 2025 全球开源技术峰会的演讲提到了一个更实际的问题:在现有技术栈中,如何用向量搜索、混合搜索、RAG 和 Agentic 技术,构建面向未来的搜索体验。
![]()
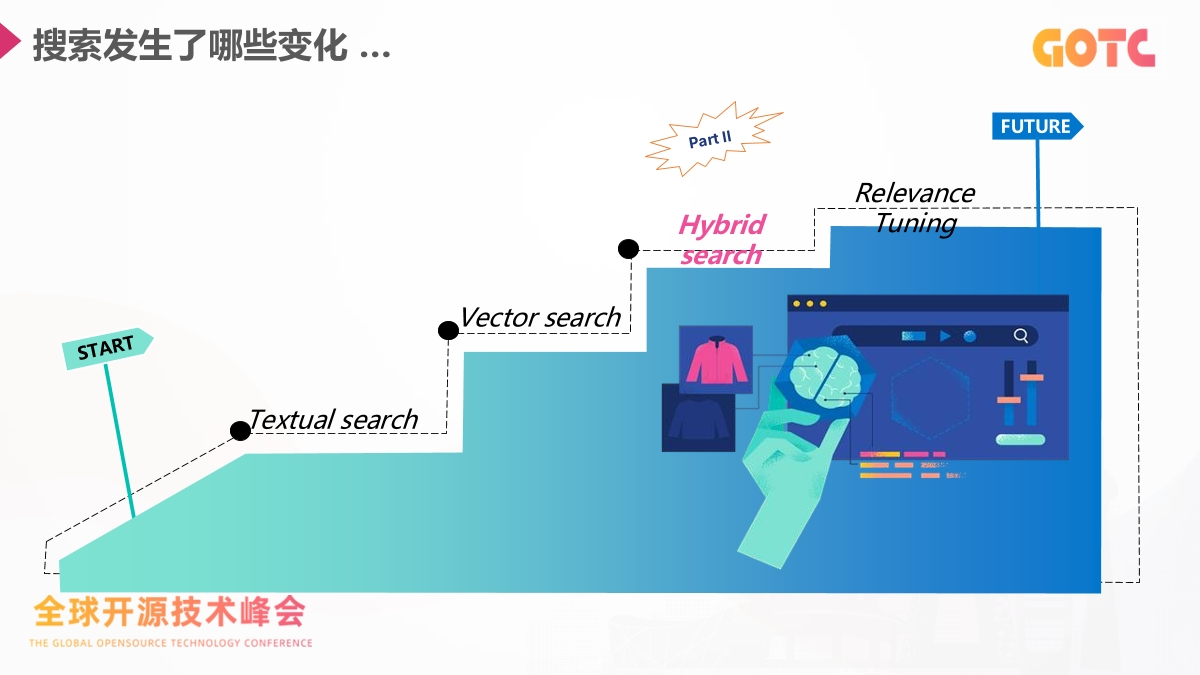
随着用户行为不断变化,搜索系统面对的挑战和过去已经不一样。词法检索继续发挥作用,但复杂的查询方式需要新的方法。语义搜索、跨模态检索、模型重排序以及 RAG 结构正在成为主流。核心难题集中在两点:系统是否理解用户的真实意图,以及模型是否能访问企业内部的实时数据。向量搜索和混合搜索为这两个问题提供了关键能力。
![]()
混合搜索通过结合 BM25、向量相似度和 RRF 这样的排序方法,让语义召回和关键词匹配形成互补,使得结果更稳定。本次分享也对构建搜索系统的流程进行了完整拆解:先加载 embedding 模型,再在数据写入时生成向量,查询时同时使用 match 和 kNN,并且支持过滤条件。从 8.7+ 开始,query_vector_builder 可以在查询时自动生成向量,让整个流程更加直接。
在底层能力上,向量引擎的更新同样是重点内容。硬件加速覆盖 CPU 指令集和 GPU/CAGRA,向量压缩带来 int8 和 int4 的成本优势,新向量存储格式如 DiskBBQ 提升了存储与检索的效率,并且在高并发下通过线程协同来降低延迟、提升吞吐。这些能力让百万级到十亿级规模的向量检索能够在实际业务中稳定落地。
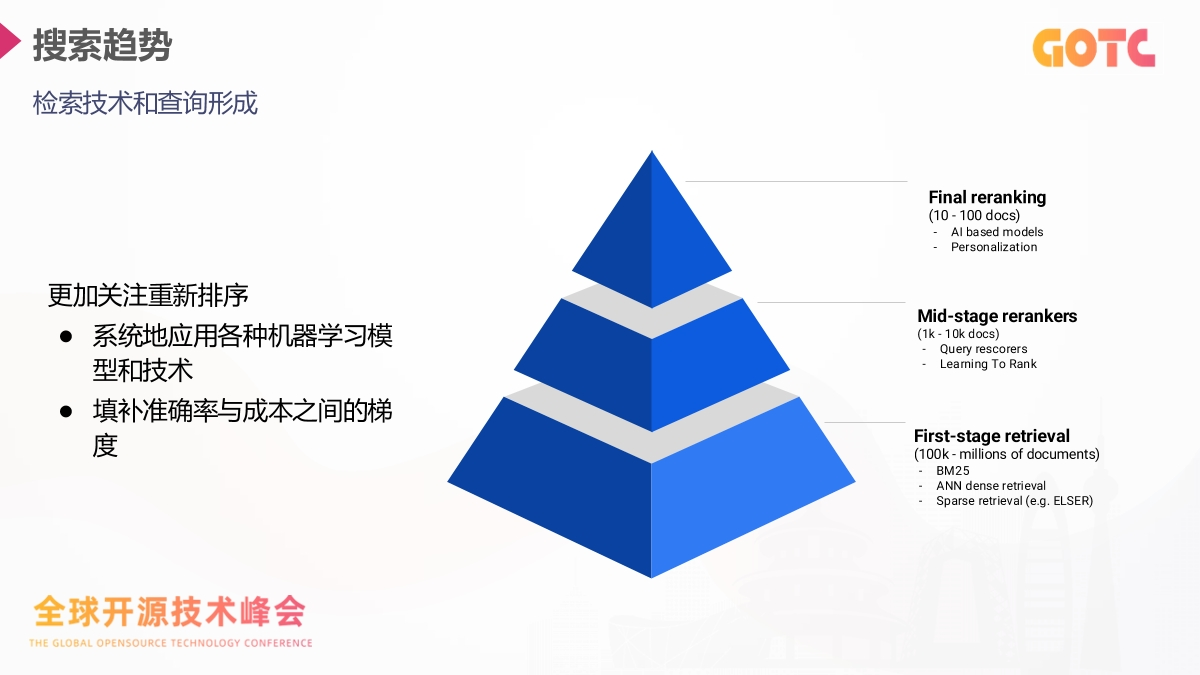
搜索趋势也在向“重排序优先”的方向演进。分享中展示了从 BM25、ANN、稀疏召回,到 Query Rescorer、LTR,再到 Cohere Rerank、Elastic Reranker 等模型重排的完整路径。系统先快速缩小候选集,再通过更强的模型提升精度,从而在成本和效果之间取得平衡。
![]()
RAG 在企业中的落地速度很快,因为大模型本身的知识是冻结的,无法反映企业实时数据,所以必须依赖检索系统来补充外部信息。在这个模式下,混合搜索天然占有优势。分享中也展示了分块策略对召回的影响,并说明了 Elasticsearch 在自动分块和语义字段类型方面提供的简化能力。进一步的发展方向是 Agentic RAG。它让系统从回答问题扩展到执行任务,包括规划、判断和自主选择工具。分享中展示的示例包括使用 MCP server、在 Kibana 中构建 Agents,以及与 Gemini Enterprise 的 A2A 协议集成,这让搜索能力不再停留在数据入口,而是延伸到完整的 AI 决策链路。
回到整体趋势,搜索的形态正在发生结构性变化。词法搜索继续提供稳定基座,向量搜索补充语义能力,混合搜索让两者协同,而重排序与 Agentic 工作流进一步提升系统的智能化水平。对于开发者和技术管理者来说,这套能力组合提供了非常明确的技术路径,让搜索从信息查找拓展到智能行为触发,并能够为未来的 AI 应用奠定基础。
完整内容查看:https://www.oschina.net/doc/485