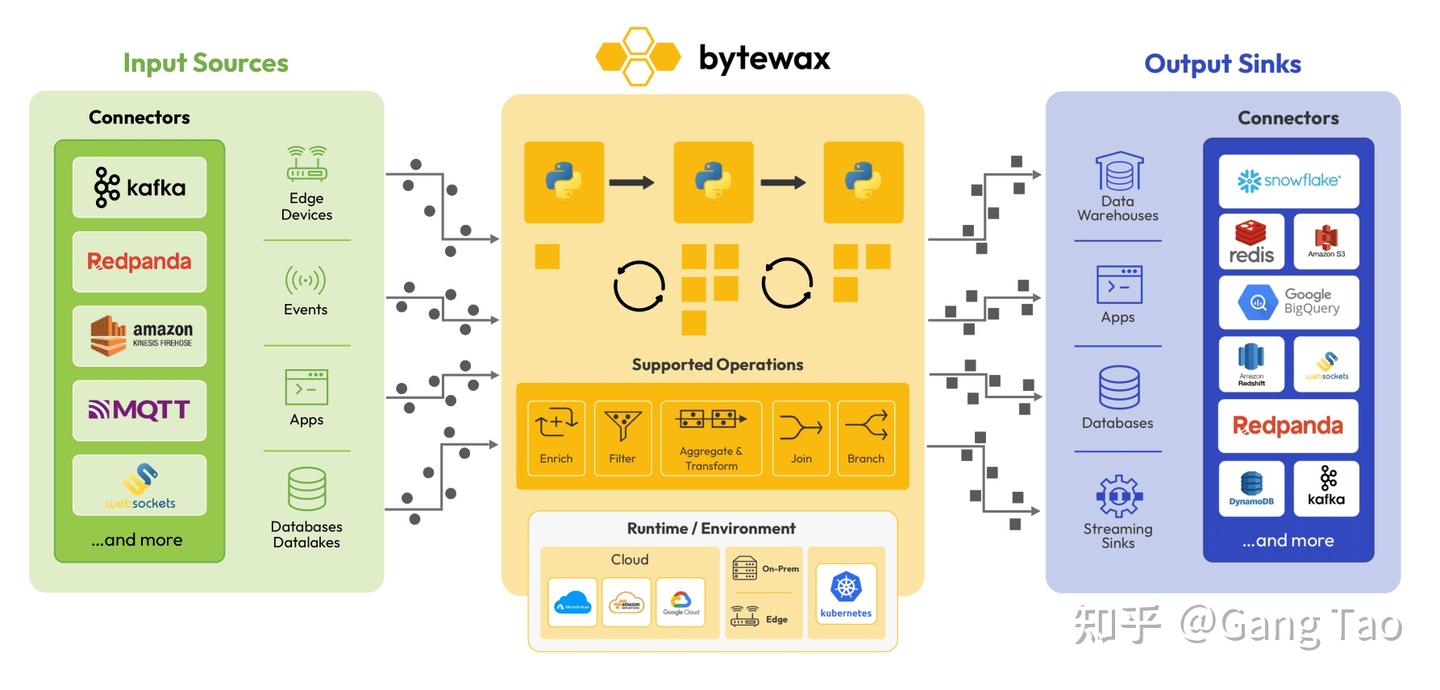
Bytewax 是一个开源的 Python 流处理框架。创建于 2022 年 2 月的Bytewax,旨在让 Python 开发者也能轻松使用有状态的流处理。通过将 Python 的易用性与 Rust 的高性能结合,Bytewax 对分布式流处理领域中 Java 虚拟机的主导地位发起挑战——根据独立基准测试,其开发速度比 Apache Flink 快 1.5 到 8 倍,同时内存消耗减少 7 到 25 倍。
项目的历史
Zander Matheson 于 2022 年 2 月创立了 Bytewax,在他担任 GitHub 和 Heroku 数据科学家期间,他发现实时机器学习基础设施存在关键缺口。问题非常根本:虽然托管 ML 模型相对简单,但为了实时推理生成特征,需要与训练时相同的复杂转换,而现有的流处理框架如 Apache Flink 和 Apache Spark 则需要 Java 或 Scala 专业知识,而大多数数据科学家并不具备这些技能。
Matheson 组建了核心团队,包括担任工程副总裁的 Dan Herrera(曾在 GitHub 设计大规模流处理系统)以及多位具有分布式系统深厚经验的开发者。该项目从一开始就以 Apache 2.0 许可证开源发布,基于 Frank McSherry 在 Rust 中实现的 Microsoft Research Timely Dataflow 架构构建(参考流处理的前世今生(十八)学院派的增量革命Materialize)。
2023 年 7 月,Bytewax 获得了微软 M12 风投基金的投资,该基金通过著名的 M12 GitHub Fund 投资,每年从 350+ 申请者中筛选 8-10 家处于 pre-seed 到 seed 阶段的开源公司。虽然具体投资金额未披露,但 M12 GitHub Fund 通常提供资金和战略支持,帮助有前景的开源基础设施项目发展。在 M12 投资之前,Bytewax 于 2021 年 5 月完成 pre-seed 融资,投资方包括 Liquid 2 Ventures、Ascend、Precursor Ventures、Array Ventures 和 8-Bit Capital,这笔资金主要用于公司成立前的初步投入。
从Bytewax推出的版本我们可以看到该项目进展的脉络
- 0.17 版本:实现状态恢复能力和 10 倍性能提升,通过优化批处理和轮询机制,将 Kafka 吞吐量从每个 worker 每秒 2,000 条提升至超过 100,000 条,同时引入基于 SQLite 的恢复存储以进行持久状态管理。
- 0.18 版本:架构成熟,支持非线性数据流(任意有向无环图)、多个同时输入源和输出汇、Kafka/Redpanda schema registry 集成、IDE 自动补全的完整类型注解,以及纯 Python 编写自定义操作符的能力。这一版本通过将操作符组合迁移到 Python 层,同时保持 Rust 引擎性能,显著扩展了框架的表达能力。
- 0.19 版本:消除了 Python 全局解释器锁(GIL)瓶颈,实现主要性能提升,增加了通过 prometheus-client 自定义指标,并改进了有状态操作符。
- 0.20 版本:引入数据流可视化器生成 Mermaid 图表、缓存与增强操作符,以及通过 Python 接口定义自定义窗口。
但是在没有任何官方声明的情况下,Matheson加入了Confluent ( 他在linkedin发文更新),Dan Herrera加入了Netflix,最后的开源版本v0.21.1发布于2024年11月25日发布之后,就没有新版本发布。waxctl CLI工具(曾经对部署管道至关重要)在2025年3月20日被归档,现已变为只读状态。也就是说这个项目嘎然而止了。
从这个结果来看,应该是倍Confluent收入麾下了。
无论如何,让我们还是来看看这个创新性的流数据处理项目。
开发者体验
Bytewax 使用声明式的数据流 API,开发者可以通过简洁、Python 风格的语法构建操作符的有向无环图(DAG)。其基本模式包括创建 Dataflow 对象、定义输入源、链式调用转换操作符,以及指定输出接收器:
from bytewax.dataflow import Dataflow
from bytewax import operators as op
from bytewax.testing import TestingSource
flow = Dataflow("quickstart")
inp = op.input("inp", flow, TestingSource([1, 2, 3, 4, 5]))
# 转换:筛选偶数并乘以 10
filtered = op.filter("keep_even", inp, lambda x: x % 2 == 0)
results = op.map("multiply_by_10", filtered, lambda x: x * 10)
op.inspect("print_results", results)
该 API 支持方法链调用,实现流畅的代码风格,例如 stream.then(op.map, "add_one", add_one)。每个操作都需要一个唯一的字符串步骤 ID,用于调试、日志记录和状态恢复——这种设计以略微增加代码冗长为代价,但显著提高了运维可见性。
操作符是流处理的基本单位。
- 无状态操作符(Stateless Operators)如
map(一对一转换)、filter(基于条件筛选)、flat_map(一对多转换)、branch(流拆分)和 merge(流合并),在处理数据时不在元素间保持内存状态。
- 有状态操作符(Stateful Operators)如
reduce(基于 key 的累积)、stateful_map(通过 Python 类实现自定义状态逻辑)、fold_window(时间窗口聚合)、count_final(有界流的计数)、join(多流连接),会维护分布式状态,并按 key 在工作节点间分区。
- 窗口操作符支持滚动窗口(tumbling)、滑动窗口(sliding)和会话窗口(session),可选择事件时间或处理时间语义。
collect_window 在时间边界内收集数据项,而 fold_window 执行增量聚合:
from datetime import timedelta
from bytewax.operators.windowing import EventClock, SessionWindower, collect_window
clock = EventClock(lambda e: e.timestamp, wait_for_system_duration=timedelta(0))
windower = SessionWindower(gap=timedelta(minutes=5))
windowed = collect_window("sessions", keyed_stream, clock=clock, windower=windower)
架构设计
Bytewax 的架构使用了 PyO3,它支持Python和Rust的互操作。提供了外部函数接口(FFI)能力,同时允许在 Rust 中嵌入 Python。双向集成使得 Python 层可以调用 Rust 运行时函数,而 Rust 引擎则在数据流中执行用户提供的 Python 转换逻辑——这一技术兼顾了 Python 的表达力与接近原生的性能。
Bytewax的三层设计有效地分离了关注点:
- Python 层定义所有公共 API、大部分数据流操作符(以复合形式)、IO 连接器,以及使用 dataclass 和闭包的数据流定义。
- Rust 核心层集成了 Timely Dataflow 运行时,实现核心操作符(如无状态转换的
flat_map_batch、有状态操作的 stateful_flat_map),处理 PyO3 接口代码,管理 worker 与协调,并实现恢复机制。
- SQLite 存储层提供本地状态持久化、恢复分区管理和快照存储。
Bytewax 构建在 Timely Dataflow 之上该基础提供了成熟的分布式协调算法,支持低延迟流处理与高吞吐量批处理,并具备迭代计算能力——协调开销低于毫秒级。
Bytewax 继承了 Timely Dataflow 的 worker 执行模型:每个 worker 是操作系统线程,执行数据流逻辑;worker 可以组合成进程并分布在不同机器上;所有 worker 执行数据流中的所有步骤;无需独立协调器或管理进程——worker 自我协调。
协调依赖 Timely Dataflow 的机制:结合时间戳/纪元(逻辑顺序表示计算进度)、前沿(追踪仍在处理的最旧纪元)、异步消息流和必要时的同步协调,以及轻量级进度跟踪(worker 跟踪在特定纪元发射数据的能力)。该设计在 64 台机器集群中也能保持亚毫秒协调开销,实现低延迟同时保持一致性。进程内部通过共享内存通信,跨机器进程通过 TCP 连接通信,状态操作会根据 key 或交换模式路由数据,确保有状态操作的数据发送到正确的 worker。
状态分区和快照恢复:每个字符串 key 分配给一个“主” worker,确保同一 key 的所有数据在同一 worker 上处理,实现状态一致更新。非 IO 操作通过 hash 函数分布 key,各 key 状态独立,支持并行处理。状态周期性保存到固定的恢复分区,实现为分片 SQLite 数据库存储在持久化存储上。每个分区选举主 worker 写入快照;恢复时在输入数据前加载快照,实现至少一次处理语义。
设计方面存在一些关键限制:
- Key 空间粒度决定最大并行度,如果只有 10 个唯一 key,即使集群再大,最多只有 10 个 worker 能有效处理数据,因此细粒度 key 空间对高并行至关重要。
- Python 全局解释器锁(GIL)会导致同一进程内多个 worker 争抢 GIL,CPU 密集型任务建议使用多进程,I/O 密集型影响较小。
- 数据序列化与网络传输的交换开销意味着小计算任务可能无法从重新分配中获益,需要根据实际场景进行性能测试。
source https://github.com/bytewax/bytewax?tab=readme-ov-file#how-bytewax-works
总结一下
Bytewax继Faust之后又一个把流处理带到Python的开源项目,底层利用Rust保证性能,用户接口提供数据和机器学习工程师喜欢的Python,是一个非常有特色的项目。
它的优势
- 开发速度
Bytewax 最显著的优势在于开发速度。McKnight Consulting Group 的基准测试显示,相比 Apache Flink,Bytewax 的开发效率提高了 1.5 到 8 倍;在 Flink 中需要一个月完成的任务,使用 Bytewax 可在不到一周内完成。这种加速来源于 Python 对数据科学家的熟悉度、免除 JVM 学习成本,以及无需依赖基础设施即可进行快速本地迭代。
- 资源效率
Bytewax 在常见工作负载下比 Flink 消耗的内存少 7 到 25 倍,独立基准测试显示总拥有成本平均降低约 4.6 倍。一项成本分析显示,对于四条流水线,每年可节省 44 万美元。较低的内存占用使其能够部署在资源受限的边缘设备(如 Raspberry Pi)上,而基于 JVM 的框架每个工作负载需要数 GB 内存,无法实现。
- Python 生态系统集成
Bytewax 无需跨语言序列化或封装限制,即可无缝访问 NumPy、Pandas、scikit-learn、TensorFlow、PyTorch。数据科学家可以使用熟悉的库和模式构建实时 ML 特征工程流水线,并且同样的转换代码可用于训练和推理。
- 开发者体验
- 熟悉的操作符(map、filter、reduce)符合 Python 习惯;
- 本地开发支持即时反馈(
python -m bytewax.run);
- 本地与分布式运行代码一致,无需修改;
- 可直接使用标准 Python 调试工具
- 架构优势
- 有状态流处理,自动状态管理与容错;
- 支持事件时间与处理时间窗口,包括滚动、滑动和会话窗口;
- 支持跨多流的复杂 join 与 merge;
- 基于 SQLite 的状态恢复,支持云端备份;
- 支持状态保留的动态资源重缩放(stop-start rescaling)。
它的劣势与局限也很明显
- 生态系统成熟度不足
Bytewax 相对年轻(2022 年 2 月发布),社区规模小,相比 Flink(2014)或 Spark(2012)成熟度低,缺乏大规模企业案例,第三方工具、培训和咨询资源有限。
- 性能考量
虽然 Rust 性能优异,但部分操作可能仍无法匹配经过几十年优化的 JVM 实现。
- 企业功能缺口
相比商业 Flink 发行版,Bytewax 在监控和可观测性方面不够全面;灾难恢复、协作工具和托管部署等平台功能需要付费商业许可而非开源;支持生态小,企业咨询和支持选项有限;高级用例文档覆盖不如成熟框架。
- 技术限制
- 缺乏像 Flink SQL 或 ksqlDB 的声明式 SQL 接口,所有逻辑需用 Python 命令式编写;
- 复杂有状态操作学习曲线仍存在;
- 分布式状态管理复杂,调试困难;
我猜测,该项目的沉寂可能基于一下的原因:
- 竞争格局
Flink和Spark等成熟竞争对手大幅改进了Python API,而Arroyo等新竞争者正积极推广"无JVM的Flink"体验,这意味着Bytewax最初的独特卖点不再那么独特。
- 市场注意力转移
科技界大量的"营销资源"已转向生成式AI基础设施,留给重新审视流处理技术栈的预算和关注度大幅减少。
- 缺乏企业级完整平台
企业投资生产工作负载时期望的不仅是核心技术,还需要强大的可观测性、治理能力和无缝的云计费系统。
- 开源项目的认知问题
对于开源项目来说,6个月没有发布或博客文章会让访客认为项目已被放弃,即使背后有蓬勃发展的付费产品,认知也很重要。
即使项目不再活跃,也难掩工程师对该项目的喜爱,因为PyFlink,PySpark实在太难用了,用过的都知道。据说Zander Matheson加入Confluent后的一个重点的工作就是改进PyFlink
“铁骑踏残阳,生者如浮萍。” 科技领域的竞争其实非常惨烈,我们大多只看到哪些幸存的成功者,而我觉得哪些努力创新的失败者,更值得肯定。
Bytewax正如它的名字比特+蜡烛,悄悄地燃尽了自己,但仍然曾经照亮着流数据处理这个领域。
感谢阅读!我是Timeplus的联合创始人和CTO。Proton 是我们开源的高性能流式SQL引擎,采用C++构建,支持用标准SQL处理实时数据流,适用于实时安全和监控、实时机器学习管道、IoT分析等场景。
欢迎访问在GitHub给我们star或者加入我们的Slack社区,和我们一起讨论流数据的未来!