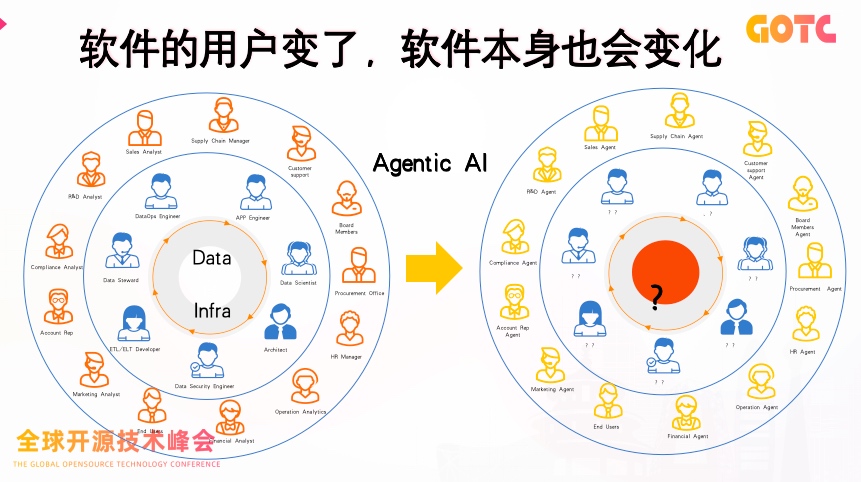
在软件世界中,用户的形态正在发生变化。
过去,软件的使用者是工程师、分析师或运维人员;而如今,他们正在被一群"数字化身"------Agent 所取代。AI 不再只是一个算法模型,而是逐渐演变为能理解业务语境、自动执行任务、并进行协同决策的智能体。
随着大模型技术的快速成熟,这场以 "Agent 化" 为核心的软件革命,正推动企业数据系统从传统的自动化,走向真正的智能化。
![]()
在这一趋势中,数据基础设施的智能升级成为关键。
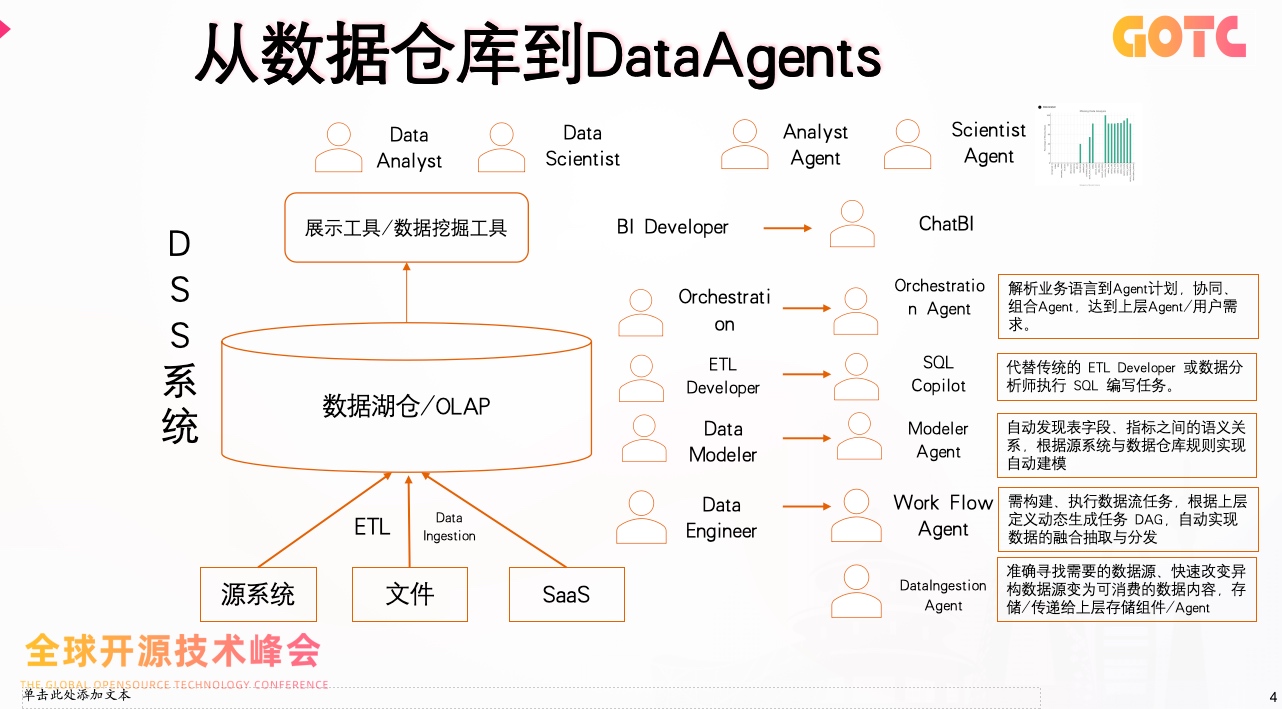
从数据到智能:DataAgents 的崛起
如果说 ChatGPT 带来了"文本的智能理解",那么 DataAgent 的出现,则代表了"数据的智能行动"。
在全球范围内,多个头部数据平台都已率先迈出这一步:
- 海外案例①:Snowflake Cortex 让"问数据"变成一场自然的对话
Snowflake Cortex 内置 LLM 服务,实现自然语言至 SQL 转化,自动生成查询并解释结果,并深度整合 Snowsight UI,让"问数据"重新变成一场自然的对话。
这带来了全新的数据分析体验,LLM 作为数据操作入口,恢复数据分析的对话式体验,对 WhaleStudio 来说是个很重要的启示:对话驱动任务生成,自然语言建模入口。
- 海外案例②:Databricks AI Assistant
Databricks AI Assistant 则让工程师在写 SQL 或 PySpark 时,获得代码补全、性能优化建议与错误修复提示。通过智能融合,仿佛 IDE 中多了一个懂上下文的智能合作者。
- 海外案例③:MotherDuck Agent
MotherDuck Agent 以轻量化语义查询与自动数据探索为核心,将分析从复杂系统迁移到云端 Agent,自动生成报告、图表与洞察。这对 WhaleStudio 来说也很有借鉴意义,将来可以计划融合语义生成与图形拖拽操作,SaaS 化加 AI 赋能,帮助用户零门槛获取数据洞察,引领数据分析新趋势。
- 海外案例④:Dataherald
Dataherald 的创新在于把 LLM 用作"企业数据库翻译器",让业务人员通过自然语言提问,实时获得可验证的 SQL 与结果解释。这种强调准确性和上下文验证,解释可追溯的特点,也启发 WhaleStudio 可以朝着优化"问题到任务"流程的方向,建立数据追溯机制。
这些案例的共同点在于:
它们都让数据变得"可交互"、让洞察更"实时"。
![]()
可以看到,DataAgent 的出现,使得数据分析不再是技术部门的专属,而是企业每一个角色都可以参与的智能对话过程。它让"数据能力"成为企业的新型生产力。
DataAgent:让数据系统拥有"理解力"
看了这么多案例,我们再回过头来深度理解下,Data Agent 到底是什么?
与传统的数据中台或 RAG 技术不同,DataAgent 并非一个独立模块,而是一组协同工作的智能体体系。
它由多个 Agent 组成,覆盖 DataFlow、ETL、Data Ingestion、SQL Copilot 等不同层面,通过编排协调机制形成自学习、自优化的执行网络。
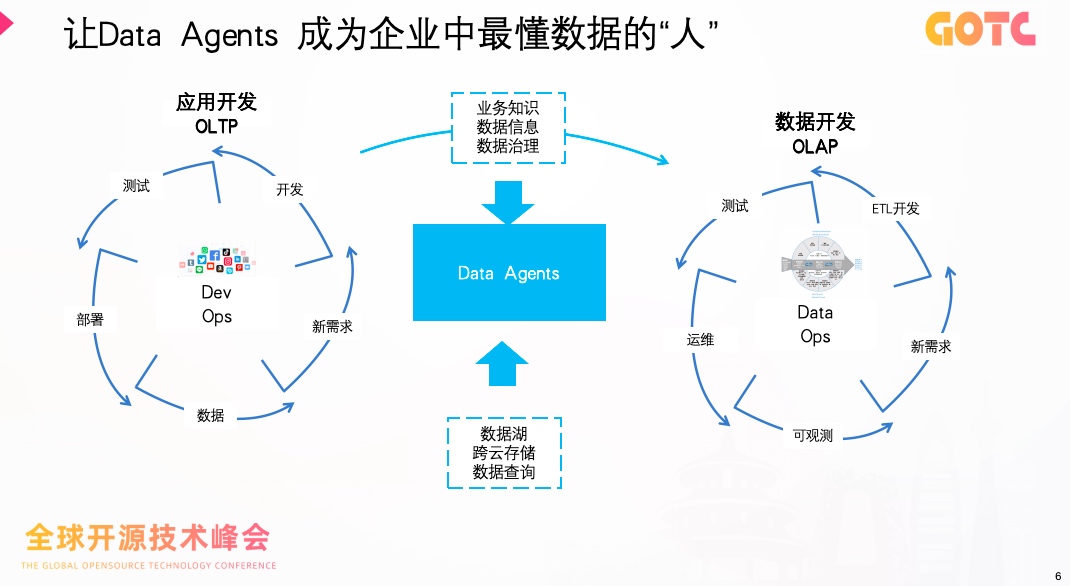
简单来说,Data Agents 可以成为企业中最懂数据的"人"。
DataAgent 让大模型理解数据,也让数据反过来理解业务。
![]()
这种双向理解,使企业能够在数据流转的每一个环节中嵌入智能判断。无论是调度、抽取还是监控,系统都不再只是被动执行规则,而能主动识别模式、优化执行路径,并基于上下文作出决策。
这正是"从自动化到智能化"的根本跃迁。
从使用场景看 DataAgent 的真实价值
DataAgent 的潜力不仅在概念层面,更体现在实际落地场景。
在任务生成方面,它能将 SQL 语句自动转化为可编辑的工作流(Workflow),支持CTE、Join、Insert等复杂操作,让技术与业务在同一视图中协作。
它还能进行 Drag&Drop 调整,用户通过拖拽方式微调节点,灵活管理调度依赖与数据流向,实现自动化与可控性平衡。
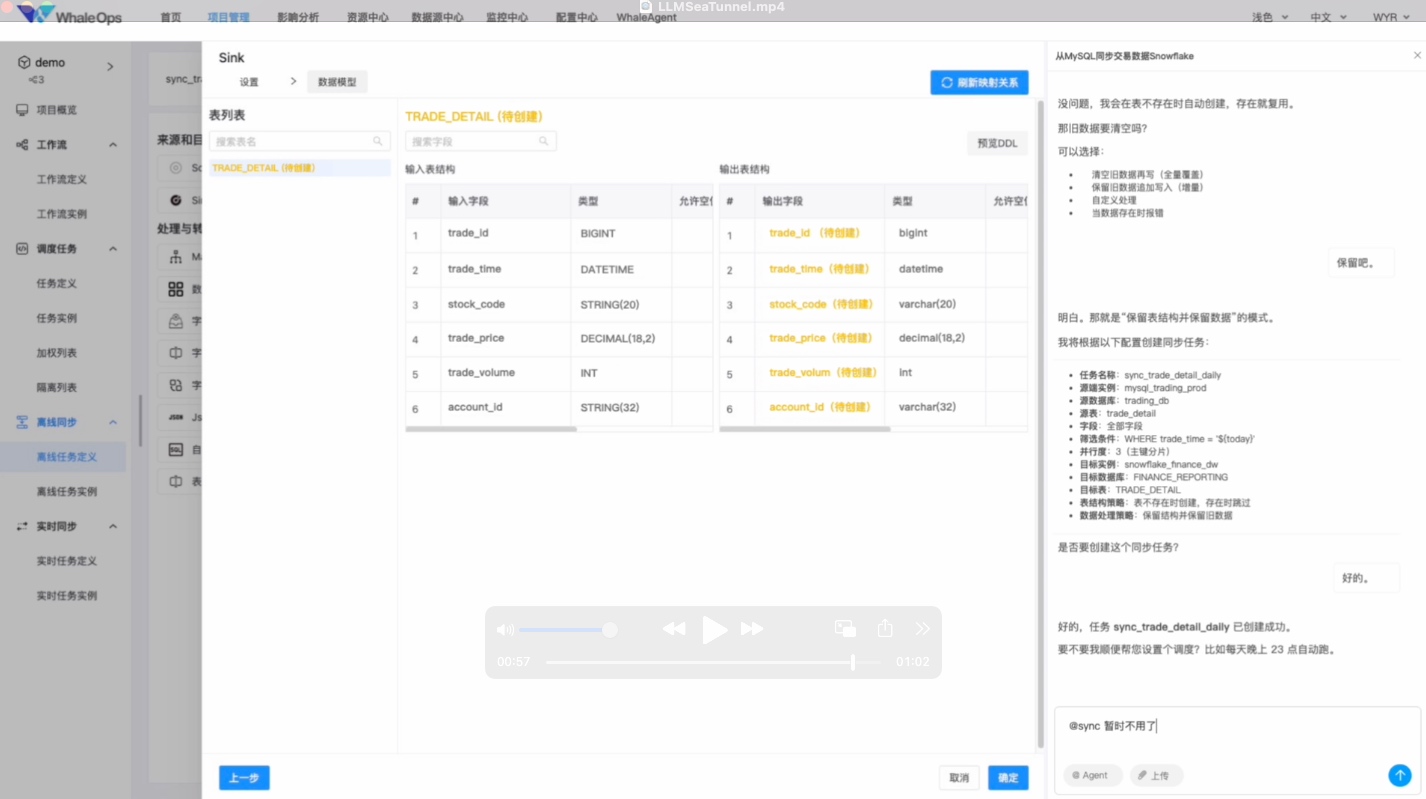
- 对话式任务生成(Prompt → Sync Task)
在数据同步中,它能将自然语言 Prompt 自动生成 WhaleTunnel 配置文件,智能推断字段映射与增量策略,自动生成配置后,进入图形界面,直观验证与微调 DAG,实现 Prompt 到数据同步任务的平滑过渡。
同时,在开发与运维阶段,DataAgent 还能充当多种角色:
- Q&A Agent 实现深度问答,提供直观配置示例,引导用户精准操作;
- Pipeline Debug Agent 自动识别性能瓶颈,给出参数调优建议;
- Workflow Error Agent 智能定位错误节点并推荐修复方案;
- SQL Code Assistant Agent 像智能 IDE 一样自动补全与校验 SQL;
- Task Lineage & Recovery Agent 自动分析血缘与重跑路径,保障一致性;
- Data Quality Agent 则监测异常与漂移,生成修复 SQL。
这些场景的本质,是让系统不再需要被"操作",而能主动地"协作"与"学习"。
它不只是提高效率,而是在重构企业的数据生产方式。
DataAgent×WhaleTunnel:让集成更智能,让洞察更实时
当智能 Agent 与数据集成框架结合,数据基础设施的形态将被彻底改变。
白鲸开源WhaleTunnel 新一代实时多源数据同步引擎支持上百种数据源与跨云环境,性能较传统方案提升可达 30 倍。
而当 DataAgent 赋能其中,WhaleTunnel 不再只是"数据搬运工",而是具备语义理解与自我优化能力的数据神经系统。
在设计上,DataAgent × WhaleTunnel 体现了四个核心理念:
- 交互层设计:通过自然语言与图形界面结合,让业务与数据团队协同构建任务;
- 意图解析与任务构建:基于 LLM 语义解析自动生成数据同步逻辑;
- Agent 编排与执行:各类 Agent 协同执行,实现任务自调度与自修复;
- 知识与安全治理:结合知识图谱与合规策略,确保数据可追溯、安全可信。
这种融合,让 WhaleTunnel 从"高速数据管道"进化为"智能数据中枢"------数据不仅被传输,更被理解与优化。
每一次变更、每一条日志、每一组指标,都能被 LLM 实时"翻译"为洞察。
![]()
WhaleTunnel融合DataAgents设计(内测中)
未来展望:从 DataFlow 到 DataAgents 网络
未来的企业数据架构,将不再以"ETL 流程"为中心,而是以"Data Agents 网络"为核心。
WhaleOps 正在探索这一方向:
通过 语义生成 + 拖拽操作 的模式,让每一个用户都能零门槛构建智能数据任务;
让数据流动的每一个节点,都拥有自主决策与优化能力。
当自然语言成为新的数据编排接口,当 WhaleTunnel 的数据流由智能 Agent 实时调度与解释,我们将迎来一个前所未有的时代:
数据不再只是被"使用",而是能主动"思考"。
DataAgent × SeaTunnel,让数据库变更实时"翻译"为洞察。
这是数据集成的未来,也是智能基础设施的起点。
欢迎思考与讨论
Agent 正在重塑数据世界的边界:它不仅能执行任务,更能理解意图、优化过程、生成洞察。
👉 你认为未来的企业数据平台,会如何与智能 Agent 共生? 👉 你希望哪类数据任务最先被"智能化"接管?
欢迎在评论区分享你的看法,让我们一起探索 "智能化数据基础设施" 的下一步。