9 月 18 日,在华为全联接大会 2025 期间,以“鲲鹏,为更先进的数智世界而计算”为主题的鲲鹏计算产业峰会在上海世博中心成功举办,集聚政企客户、行业伙伴和学术界领军人物。
峰会现场,华为正式宣布鲲鹏全链路开发与加速工具全面开源,涵盖鲲鹏应用使能套件 BoostKit 、鲲鹏统一并行加速库 KUPL 以及 GCC for openEuler 、LLVM for openEuler 以及高性能图编译器 ANNC 三大编译器,标志着鲲鹏计算产业从基础软件开源迈进全栈技术开放的新阶段——在始终践行“硬件开放、软件开源”的策略下,协同生态伙伴释放更多元算力的最大价值。
全栈工具开源,构筑技术创新基座
在通用计算领域,鲲鹏以突破性创新和持续开源开放,引领通用算力迈入全新阶段。
在今年的鲲鹏计算产业峰会上,进一步开源了鲲鹏应用使能套件 BoostKit 、鲲鹏统一并行加速库 KUPL ,以及三款新编译器 GCC for openEuler 、LLVM for openEuler 和高性能图编译器 ANNC ,助力开发者灵活自主地应用创新。
其中,鲲鹏应用使能套件 BoostKit 面向大数据、数据库、分布式存储、虚拟化、云手机等多个主流场景,提供软硬协同调优的加速软件包与参考实现,其集成的 WAAS 负载感知加速系统可自动配置全栈最优参数,使能伙伴实现极致性能。
目前,鲲鹏BoostKit 生态开源开放地图已正式上线鲲鹏官网,并收录了超 25 款鲲鹏使能套件,开发者可以直接点击“获取源码”查看并下载。
![]()
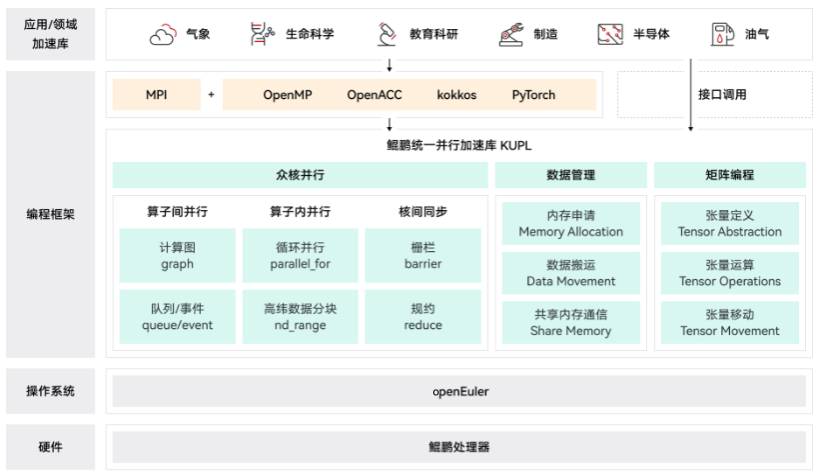
同期即将开源的鲲鹏统一并行加速库( KUPL )则是基于鲲鹏处理器深度优化的并行加速库,包括多线程编程、数据管理、矩阵编程三类基础与拓展功能,结合鲲鹏处理器硬件特性,提供优化的调度与同步算法、异步数据搬运等差异化能力,从高性能、高易用角度为鲲鹏平台应用加速提供助力。
![]()
其关键特性包括:
众核并行
- 算子间并行,提供基于 graph 、queue 的任务依赖描述能力,实现算子动态负载均衡运行
- 算子内并行,实现面向多维度数据的自动任务拆分与并发执行功能
数据管理
矩阵编程
- 简化Matrix computation编程,实现矩阵分块、矩阵乘、矩阵读取与保存能力
除此之外,鲲鹏本次还一并开源了三大新编译器, GCC for openEuler 、LLVM for openEuler 以及高性能图编译器 ANNC ,对 openEuler 操作系统“编译工具链生态”做出关键补位——既覆盖了传统通用计算场景,又瞄准了 AI 与图计算等新兴领域,形成了从基础编译到高性能场景优化的全链路支撑,进一步夯实了鲲鹏架构在 IT 生态中的底层工具基础。
- GCC for openEuler :针对鲲鹏架构深度优化,并严格兼容上游 GCC 最新稳定版本的语法规则和编译接口,大幅降低企业“换架构”的开发成本;
- LLVM for openEuler :一套模块化、可扩展的编译器框架,凭借“前端 - 中间表示( IR )- 后端” 的解耦设计,支持 C/C++、Rust、Go、Swift 等更多元的编程语言,便于开发者根据场景定制编译流程;
- 高性能图编译器 ANNC :专门针对“计算图”场景的高性能优化器,在 AI 与图计算成为企业数字化核心能力的当下,ANNC 弥补了鲲鹏生态在“专用编译”领域的空白。
至此,鲲鹏软件的全面开源,构筑起了鲲鹏从“硬件提供者”向“生态基础设施建设者”升级的关键一步,吸引更多企业与开发者加入鲲鹏生态。
六年开源之路,生态版图持续扩张
回溯鲲鹏开源历程,一步一个脚印稳扎稳打,始终坚持让鲲鹏更易用、更好用!
2019 年,鲲鹏以 openEuler 操作系统、openGauss 数据库开源为起点,奠定了国产自主计算生态根基;2024 年又启动了原生开发技术,打通“硬件+系统+工具”技术链路;直至 2025 年全链路工具开放开源,标志着生态建设已迈入成熟期。
从 2019 年至今,鲲鹏生态用六年时间完成“根基奠定 - 链路贯通 - 成熟落地”的跨越式发展,不仅树立了“以开源驱动产业创新”的典范,也为全球计算产业多元化发展注入了中国力量。
- 开源为核,凝聚生态合力:始终以开源技术为纽带,打破技术壁垒与企业边界,汇聚全球开发者与伙伴力量,形成 “共建共享、协同创新” 的生态模式,这是生态快速扩容的关键基础;
- 问题导向,突破关键瓶颈:每阶段战略均精准解决行业痛点 ——2019 年破 “核心软件依赖” 之困,2024 年解 “硬软协同低效” 之难,2025 年补 “工具门槛过高” 之缺,以技术突破推动生态升级;
- 自主可控,服务产业需求:始终聚焦国产计算产业自主化目标,从核心技术研发到产业闭环构建,均以满足国内关键行业需求为导向,最终实现从 “技术自主” 到 “产业自强” 的转变。
正如今年峰会上,华为鲲鹏计算业务总裁李义表示:“今年,我们进一步深化同辕开发计划,基于全新鲲鹏 DevKit 和鲲鹏 BoostKit ,通过一套代码、一条流水线构建多平台版本,面向行业场景提供出厂即用、开箱即优的行业场景化解决方案,实现平均开发效率提升 30% ,应用性能提升 30% 以上,助力用户应用在鲲鹏平台上运行更高效、更稳定。”
目前,鲲鹏已与 7000 多家伙伴合作孵化超过 20000 个解决方案,openEuler 开源操作系统累计部署超 1260 万套,openGauss 开源数据库下载量达 480 万次。未来,鲲鹏还将与更多行业伙伴继续坚定同行,共赴新程,为世界提供新选择!
多维价值释放,驱动产业协同进化
如今,鲲鹏持续开源的价值,正沿着全产业链脉络深度释放,成为驱动产业创新、升级的关键力量。
对于开发者来说,鲲鹏软件通过开放核心代码库、提供完善的开发文档与标准工具集,大幅降低开发门槛——个体开发者无需从零攻克底层技术,可直接基于成熟开源框架探索应用创新;团队则能快速复用生态内优质组件,减少重复研发成本,将精力聚焦于场景化创新,有效激发个体与团队的创新潜能。
对伙伴企业来说,鲲鹏开源生态已整合行业先进工具链,企业无需耗时搭建独立技术体系,可直接按需适配、整合工具资源,显著缩短方案从设计、构建到上市的全周期,助力企业更快响应市场需求,打造出兼具技术深度与市场竞争力的产品及解决方案。
在行业层面,鲲鹏软件开源推动软件技术走向标准化:通过统一的接口规范与开放技术框架,打破不同企业间的技术孤岛,促进跨企业技术成果互通共享,避免技术碎片化造成的资源浪费,加速整个产业从 “各自为战” 向 “协同共进” 转型。
当然,对于鲲鹏自身,开源模式不仅构建了“技术反馈、标准共建”的良性循环,能与更多开发者、企业在实际应用中,快速反哺技术迭代,同时,也在持续联合生态伙伴共建行业范式,让技术更贴合产业需求,最终实现生态的持续壮大。
![]()
此外,鲲鹏的开源策略并不限于中国市场,其产品和技术已经逐步走向全球,鲲鹏已经开始拓展其国际化战略。开源生态的繁荣,不仅增强了鲲鹏的市场竞争力,也为全球客户提供了更多样化和灵活的计算解决方案。
在未来,国产芯片的技术突破与生态建设,将决定着整个行业的竞争格局。鲲鹏的开源策略和技术自主创新,将为中国乃至全球的计算市场带来更多机遇。