作者:来自 Elastic Eduard Martin 及 Alexander Dávila
Elasticsearch 新手?加入我们的 Elasticsearch 入门网络研讨会。您还可以开始免费的云试用或立即在您的机器上试用 Elastic。
在本文中,我们将向您展示如何使用 Elasticsearch 中的 UBI(用户行为洞察)标准捕获和分析用户分析数据。
您可以在本文中了解有关 UBI 的更多信息。
使用 UBI 收集器收集的数据可以在 Kibana 上用于构建仪表板,从而打开了解用户在我们应用程序中的行为的窗口。在本博客中,我们将探讨如何分析 Kibana 中的 UBI 数据,以深入了解我们的应用程序是如何使用的。
演示设置
我们可以按照以下步骤轻松重现本博客中的演示:
1)克隆代码库
git clone https://github.com/Alex1795/ubi-dashboard-elasticsearch_blog.git
cd ubi-dashboard-elasticsearch_blog
2)安装所需的库:
pip install -r requirements.txt
3)运行设置脚本。确保事先设置以下环境变量:
- ES_HOST
- API_KEY
- KIBANA_HOST
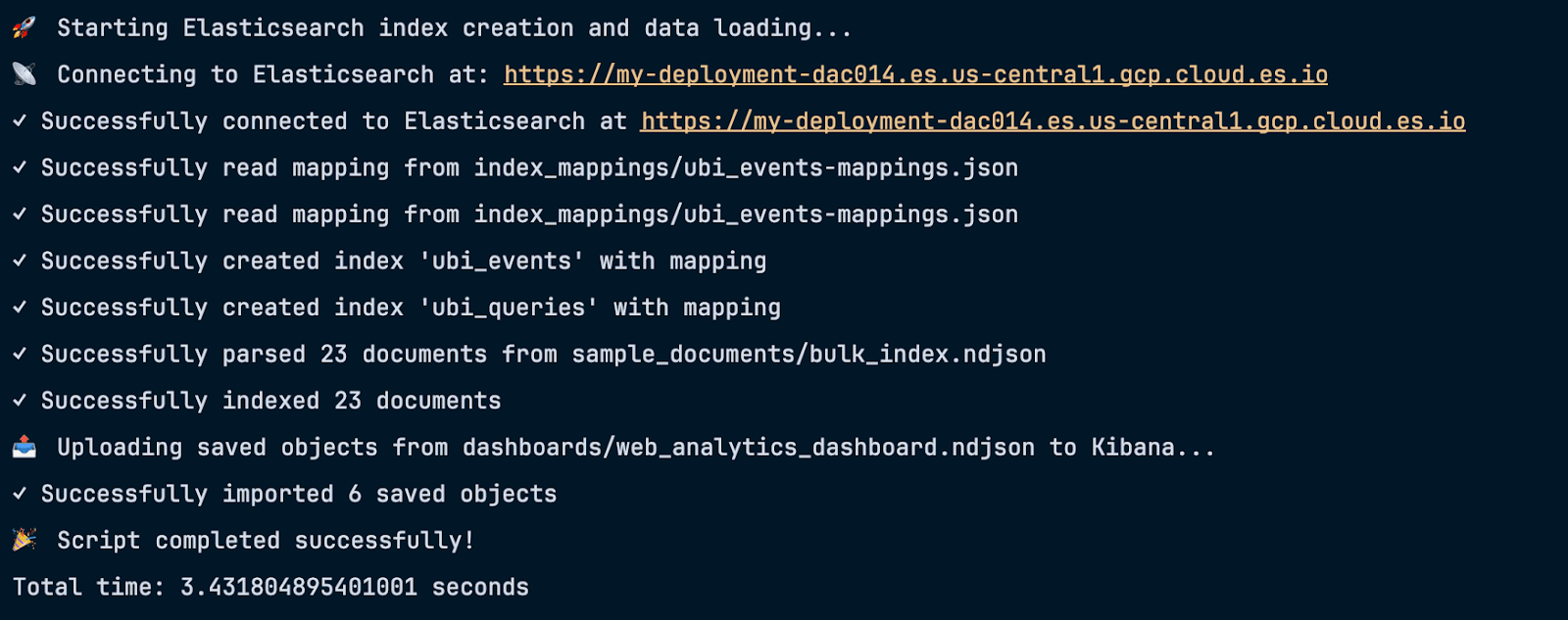
这就是你需要做的全部操作。如果一切顺利,你应该会在脚本执行中看到如下输出:
正如我们所见,脚本:
- 创建了两个具有适当映射的索引
- 向这些索引添加了 23 个文档
- 将一些已保存的对象上传到 Kibana
现在,让我们看看这个脚本在后台到底做了什么。
理解已上传的数据
首先,在创建可视化之前,我们先在 Elasticsearch 中放入一些数据。
你可以在 Kibana DevTools 中手动重现该过程,分别复制映射和示例数据,并使用 PUT <index> 和 PUT _bulk API。
ubi_events 索引
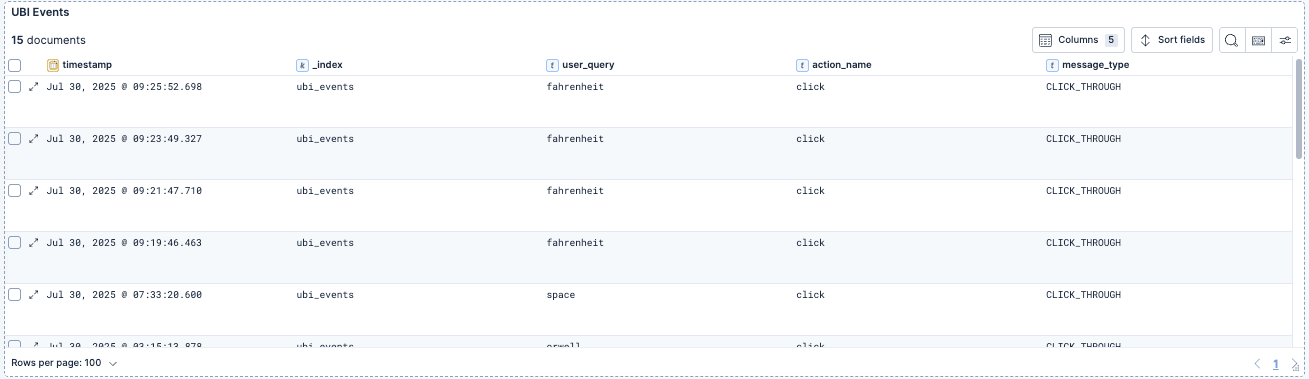
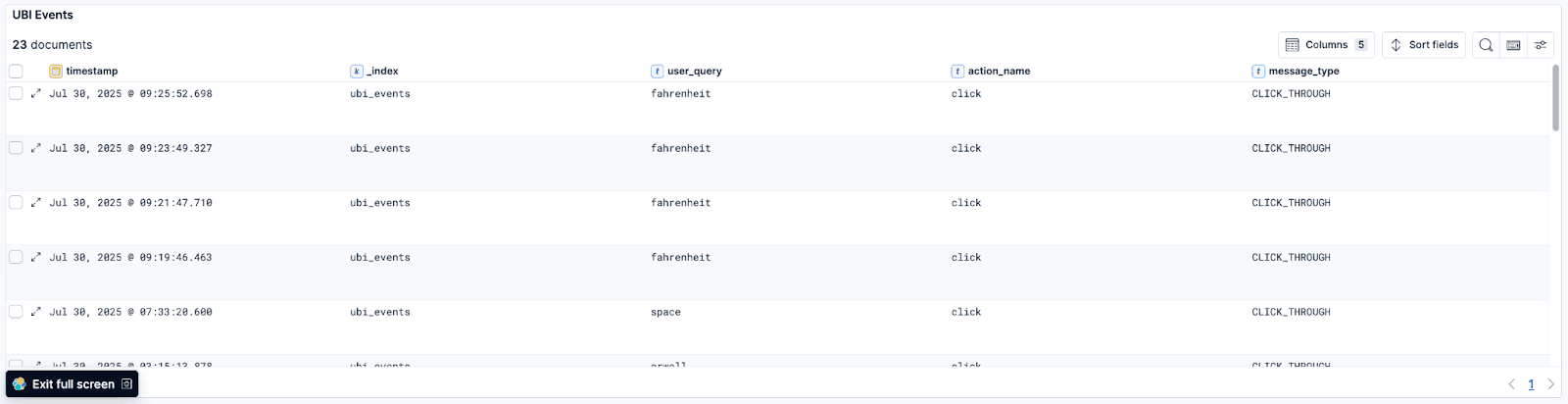
用户操作数据,每次点击都会生成文档(本例中),包括:
- application:生成事件的客户端应用程序("search-ui")
- action_name:执行的用户操作类型("click")
- query_id:将该事件链接到相应的搜索查询会话
- client_id:生成的唯一 ID,用于表示用户或会话,不泄露个人数据。它代替使用可识别数据(如电子邮件或用户名)生成。这种方法具有隐私优势,例如安全分析能力和安全数据共享,同时仍能实现会话连续性、行为分析或 A/B 测试等重要功能。
- timestamp:事件发生的 ISO 8601 格式时间戳
- message_type:事件类别,用于处理("CLICK_THROUGH")
- message:事件发生的人类可读描述("Clicked Fahrenheit 451")
- user_query:导致该事件的原始搜索词("fahrenheit")
- event_attributes:包含详细事件上下文的嵌套对象:
- object.device:用户使用的设备类型("mobile")
- object.object_id:点击项的唯一标识
- object.description:点击项的详细信息(书名、日期、作者)
- object.position.ordinal:搜索结果中项的排名位置(第 1 位)
- object.position.page_depth:项所在的结果页(第 1 页)
- object.user.ip:用户 IP 地址
- object.user.city/region/country:地理位置信息
- object.user.location:精确的经纬度坐标
示例文档:
{
"application": "search-ui",
"action_name": "click",
"query_id": "2dd48446-7ca8-4510-89f4-2ebb67ed240b",
"client_id": "8c1915fe-8ee0-4487-b801-3b1d67c25cf6",
"timestamp": "2025-07-30T14:25:52.698Z",
"message_type": "CLICK_THROUGH",
"message": "Clicked Fahrenheit 451",
"user_query": "fahrenheit",
"event_attributes": {
"object": {
"device": "mobile",
"object_id": "ZwoTM5gBPJ218VOaBpj4",
"description": "Fahrenheit 451(1953-10-15) by Ray Bradbury",
"position": {
"ordinal": 1,
"page_depth": 1
},
"user": {
"ip": "192.168.1.100",
"city": "New York",
"region": "New York",
"country": "United States",
"location": {
"lat": 40.7128,
"lon": -74.006
}
}
}
}
}
你可以在此处下载索引映射
ubi_queries 索引
搜索数据包括与用户执行的每个搜索相关的数据:
- query_response_id:此特定查询响应实例的唯一标识
- user_query:用户输入的原始搜索词("fahrenheit")
- query_id:搜索查询会话的唯一标识
- query_response_object_ids:作为搜索结果返回的对象 ID 数组(["3", "9"])
- query:完整的 Elasticsearch 查询对象(JSON 格式),包括搜索参数、搜索字段、结果数量、排序和元数据
- client_id:生成的唯一 ID,用于表示用户或会话,不泄露个人数据。它代替使用可识别数据(如电子邮件或用户名)生成。这种方法具有隐私优势,例如安全分析能力和安全数据共享,同时仍能实现会话连续性、行为分析或 A/B 测试等重要功能。
- timestamp:查询执行时的 Unix 毫秒时间戳(1753885225098)
示例文档:
{
"query_response_id": "03e8af3e-8725-49d9-99ad-36bf2a8e96d1",
"user_query": "fahrenheit",
"query_id": "f8b2f5bc-cb3c-49d4-86bc-19212a782ba7",
"query_response_object_ids": [
"3",
"9"
],
"query": """{"from":0,"size":20,"query":{"multi_match":{"query":"fahrenheit","fields":["author^1.0","name^1.0"]}},"_source":{"includes":["name","author","image_url","url","price","release_date"],"excludes":[]},"sort":[{"_score":{"order":"desc"}}],"ext":{"query_id":"f8b2f5bc-cb3c-49d4-86bc-19212a782ba7","user_query":"fahrenheit","client_id":"8c1915fe-8ee0-4487-b801-3b1d67c25cf6","object_id_field":null,"query_attributes":{}}}""",
"client_id": "8c1915fe-8ee0-4487-b801-3b1d67c25cf6",
"timestamp": 1753885225098
}
你可以在此处下载索引映射。
示例数据
我们可以使用 _bulk API 在两个索引中索引一些示例数据。
这将在 ubi_queries 索引中创建 6 个文档,在 ubi_events 索引中创建 16 个文档。
仪表板对象
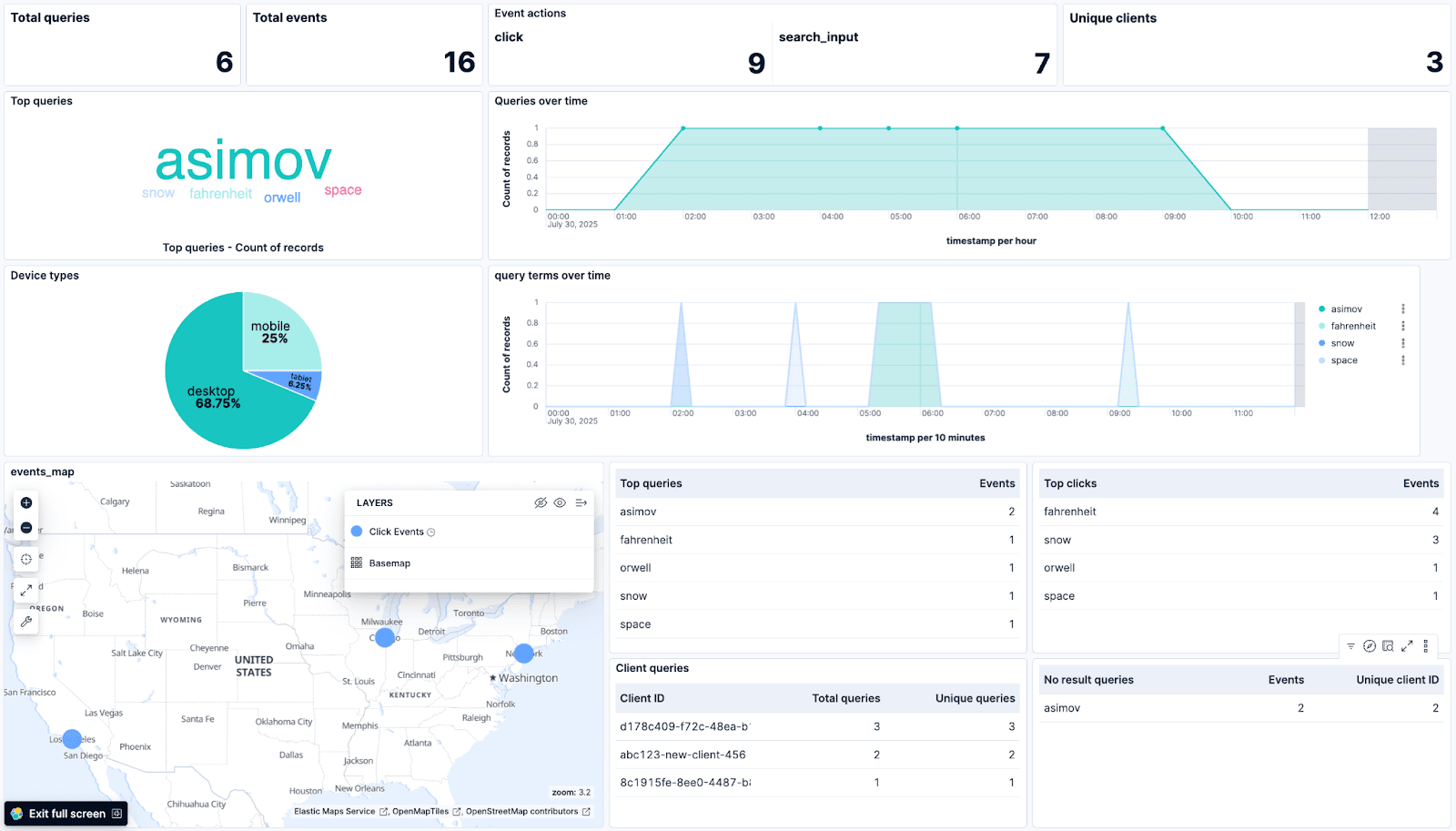
在详细介绍本示例中使用的可视化之前,你可以下载完整示例仪表板的 Saved Object 并将其导入到你的 Kibana 实例中。该仪表板展示了最常搜索的词、搜索和事件发生的时间,以及它们的来源(在地图上)。
可视化洞察
我们将创建一个 Kibana 仪表板,使用 Kibana Lens 分析最常见的指标。有关可用可视化的参考,请访问此页面。
ubi_events
我们将从一些使用 Lens 创建的简单指标(Metric)可视化开始:
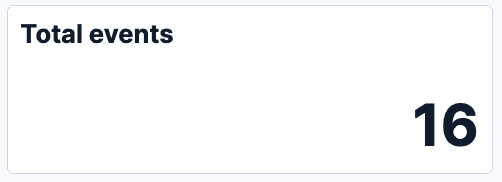
- Total events:统计在时间范围内触发了多少事件。使用索引中文档的简单计数,在字段列表中表示为 # Records。
Event actions:按 action_name 统计操作次数。这是对文档的简单计数,按 action_name.keyword 拆分。在我们的示例数据中,有两种操作类型:
- click:当用户点击书籍链接时生成
- search_input:当用户在搜索框输入文本时生成(防抖 300ms)
现在介绍表格可视化:
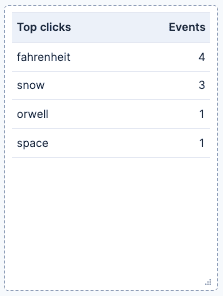
- Top clicks:一个表格,按事件来源的查询统计事件数量。它在 user_query.keyword 上使用 Top values 函数。这可以让我们看到哪些查询在网页上产生更多交互。
最后,其他一些可视化:
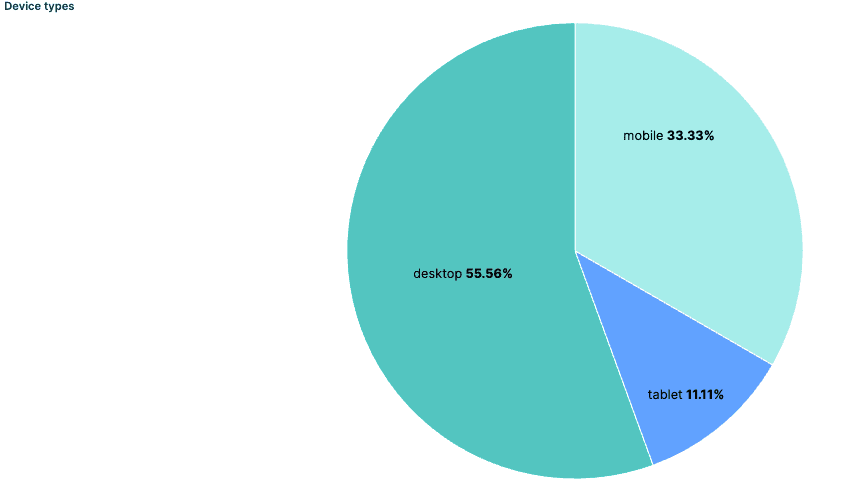
- Device types:此可视化按事件来源设备类型拆分事件百分比。设备可分为三类:Desktop、mobile 或 tablet。该可视化是一个饼图,使用 event_attributes.object.device.keyword 的 Top values,可让我们了解用户使用的设备类型。如果检测到某一类型设备上的事件突然异常下降,这可能表明应用的近期更改导致该设备访问时出现错误,从而触发警报。
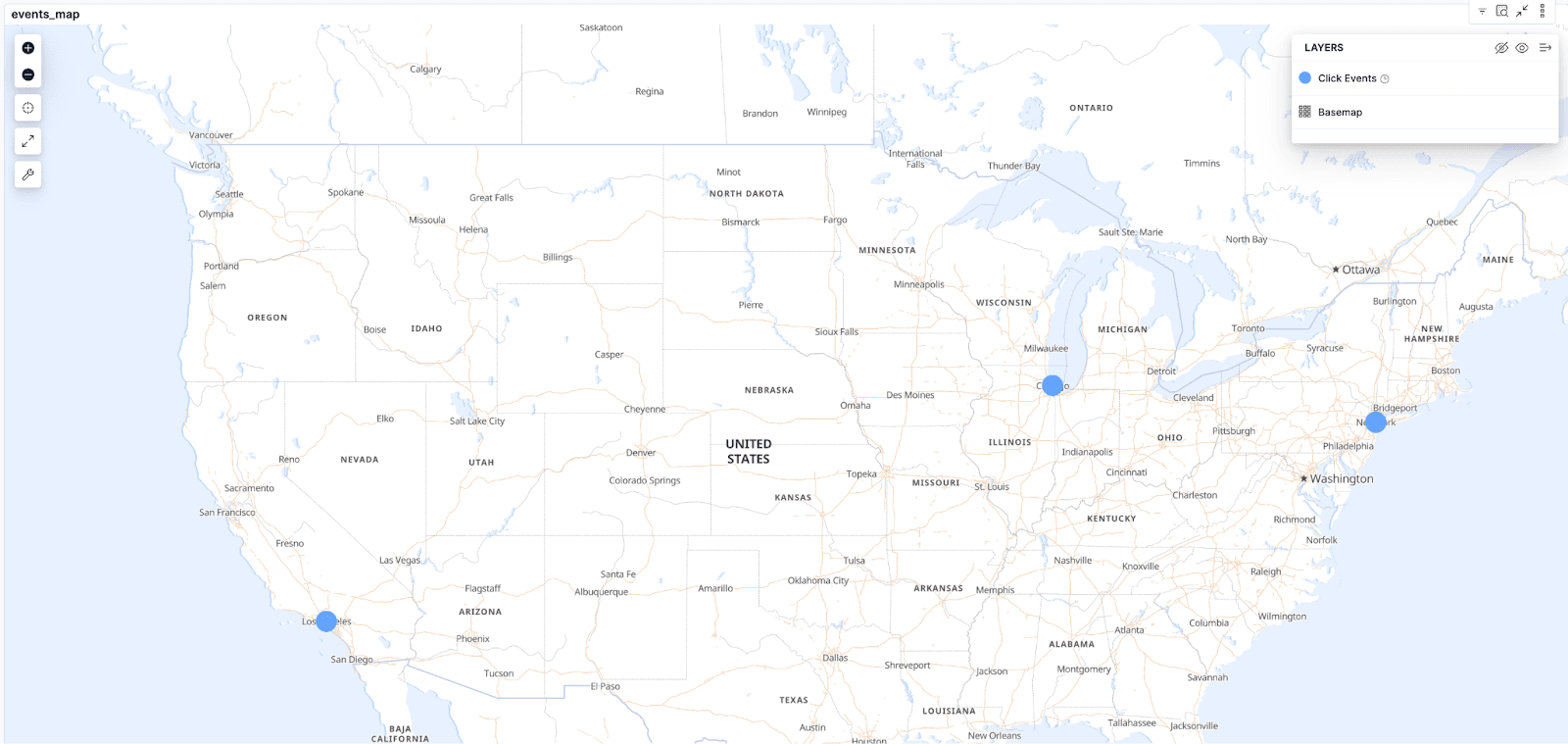
- Events map:一个地图可视化,显示事件来源位置,让我们看到用户的地理分布。目前,它显示单个文档的来源,但也可以用于查看用户密度,例如通过热力图。
当与不同过滤器一起使用时,这个可视化可以提供非常有趣的洞察。例如,我们可以看到不同搜索词的来源或大部分点击的来源位置。这对于制定本地化策略或了解各地市场差异非常有用。地图使用的是 event_attributes.object.user.location 的位置数据。
- UBI Events:一个保存的搜索,包含最新的 UBI events 文档
ubi_queries
这里我们有来自该索引的可视化:
- Total queries:对索引的简单文档计数,用于显示总共收到多少查询。这展示了整体情况,并回答了在选定时间窗口内我们总共收到多少查询的问题。
- Unique clients:对字段 client_id 进行 unique_count,以显示有多少不同的客户使用了我们的网站。
- Top queries (标签云):一个前 5 个搜索次数最多的词的标签云。这个可视化使用字段 user_query.keyword,让我们可以轻松看到用户最常搜索的主要词语。
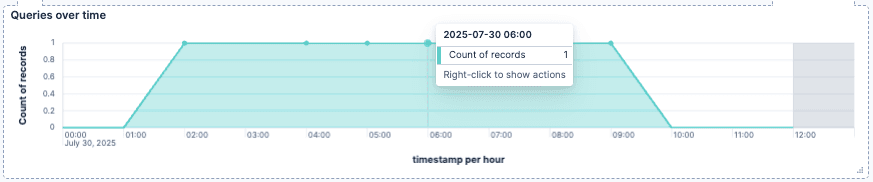
- 随时间的查询:一个每小时查询数的折线图,使用字段 timestamp 的水平轴上的简单计数指标。
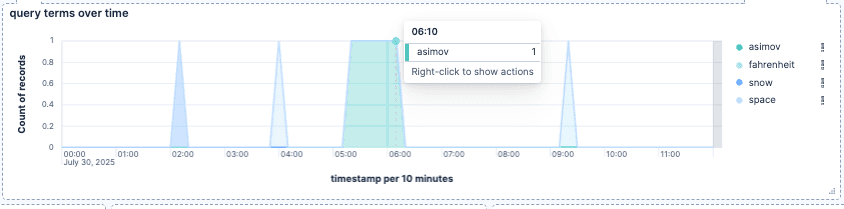
- 随时间的查询词:与上一个类似,但按 user_query.keyword 分解。这个图表可以显示随时间搜索的不同词的数量。
- 热门查询:一个 Top values 表,显示某个词被搜索了多少次。它使用 user_query.keyword 字段。
- 客户端查询:一个 client_id 字段的 Top values 表,用来统计每个客户端的总查询数和唯一查询数。
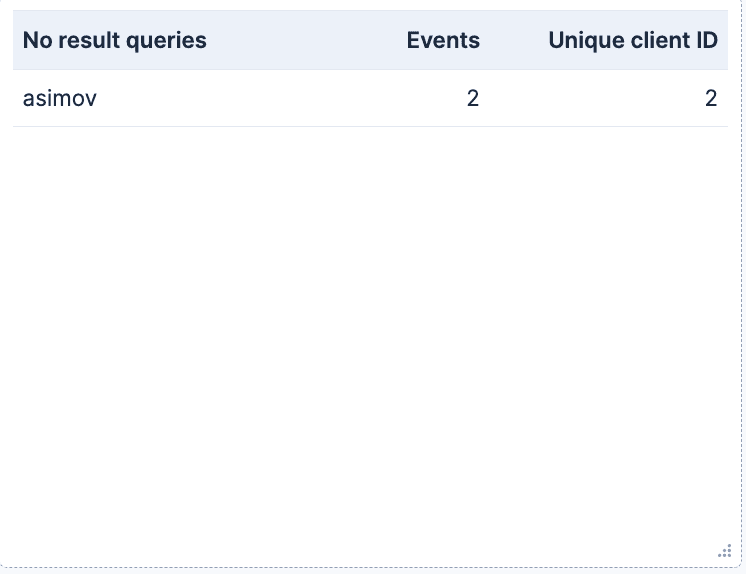
无结果查询:一个 Top value 表,显示没有匹配任何文档的 top query_terms,以及 client_id 字段的 Unique Count。 这对于确定我们网站缺少哪些产品非常有用。比如,在一家电子商务书店中,经常出现某本书名的搜索,可能会促使我们采购该书进行销售。另一方面,这也可能表明我们的搜索实现存在不足,例如用户使用了基于问题的搜索,而这类搜索更适合语义搜索方法。
在这里你可以看到完整的 dashboard:
示例数据分析
在我们的 dashboard 中,我们可以得到一些洞察:
-
- 流量来自美国的 3 个不同城市
- 我们的大多数用户通过桌面设备访问我们的网站,但也有相当数量的用户使用移动设备,甚至还有一些使用平板
- 我们可以看到最热门的查询是 “asimov”,但同时我们没有任何结果。这可能是一个很好的指标,提示我们应该优先补充哪些产品库存
为了进一步分析,我们可以使用 Kibana 的 Machine Learning 功能来理解和预测用户在我们网站上的行为。更进一步,我们还可以使用不同的可用连接器基于这些行为创建警报。
从搜索相关性的角度来看,用户行为是 LTR 等相关性工程工具的重要输入。
结论
通过 UBI 收集器收集的数据可以很容易地帮助我们更好地理解用户。生成的 dashboard 成为用户搜索行为的实时脉搏,并能指出数据缺口,从而推动我们搜索引擎的改进。
原文:https://www.elastic.co/search-labs/blog/elasticsearch-plugin-user-behavior-data-kibana