一、GcPDF 产品简介
GcPDF(GrapeCity Documents for PDF)是葡萄城(GrapeCity)推出的一款功能强大的 .NET PDF 开发组件,旨在为开发人员提供高效、灵活的 PDF 文档处理解决方案。无论是创建全新 PDF 文档、编辑现有 PDF 内容,还是进行 PDF 转换、批注、签名、表单处理等操作,GcPDF 均能通过简洁易用的 API 实现,广泛适用于企业级报表生成、文档管理系统、电子合同签署、金融票据处理等各类业务场景。
作为 .NET 生态下的成熟 PDF 组件,GcPDF 具备跨平台特性,支持 .NET Framework、.NET Core、.NET 5+ 及以上版本,可在 Windows、Linux、macOS 等操作系统中稳定运行,同时兼顾高性能与低内存占用,能轻松应对大规模 PDF 文档的批量处理需求,帮助开发团队快速构建专业的 PDF 相关应用。
二、GcPDF V8.2 新特性:AI 驱动的 PDF 处理
V8.2 版本新增了功能强大的软件包 GcPDF AI ,该软件包旨在展示 GcPDF 如何与 AI 服务集成,进而优化 PDF 文档工作流程。借助此特性,开发人员可利用 OpenAI 或 Azure OpenAI 直接从 PDF 中生成摘要、创建大纲树,并提取结构化表格数据。
支持的场景
目前,GcPDFAI 支持以下三种由 AI 驱动的 PDF 处理功能:
-
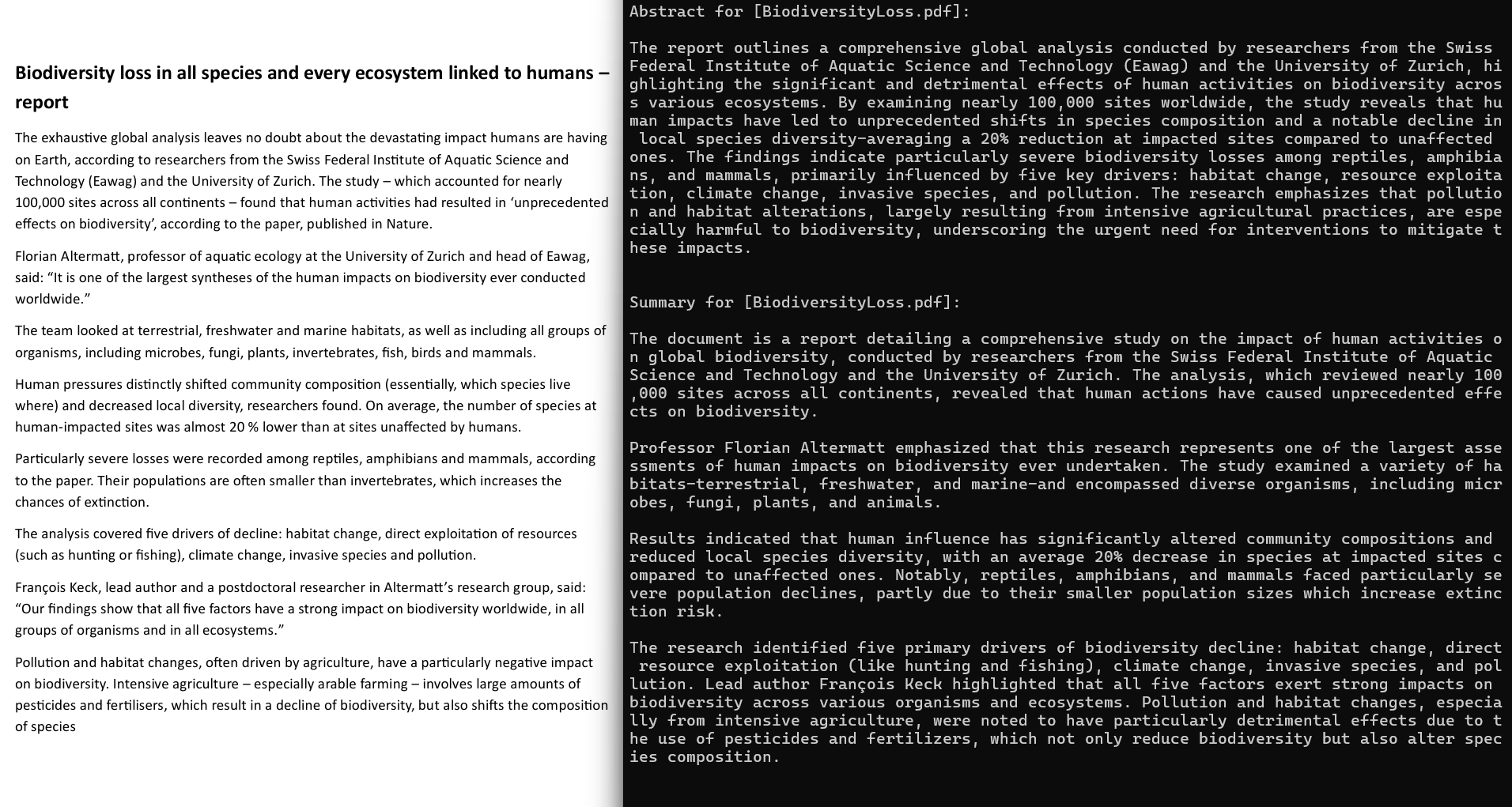
生成文档摘要 - 快速生成任意 PDF 文档的简短或详细摘要。
-
可在 C# 或 VB 语言中通过编程方式,利用 GcPDFAI 生成 PDF 文档摘要。
![]()
-
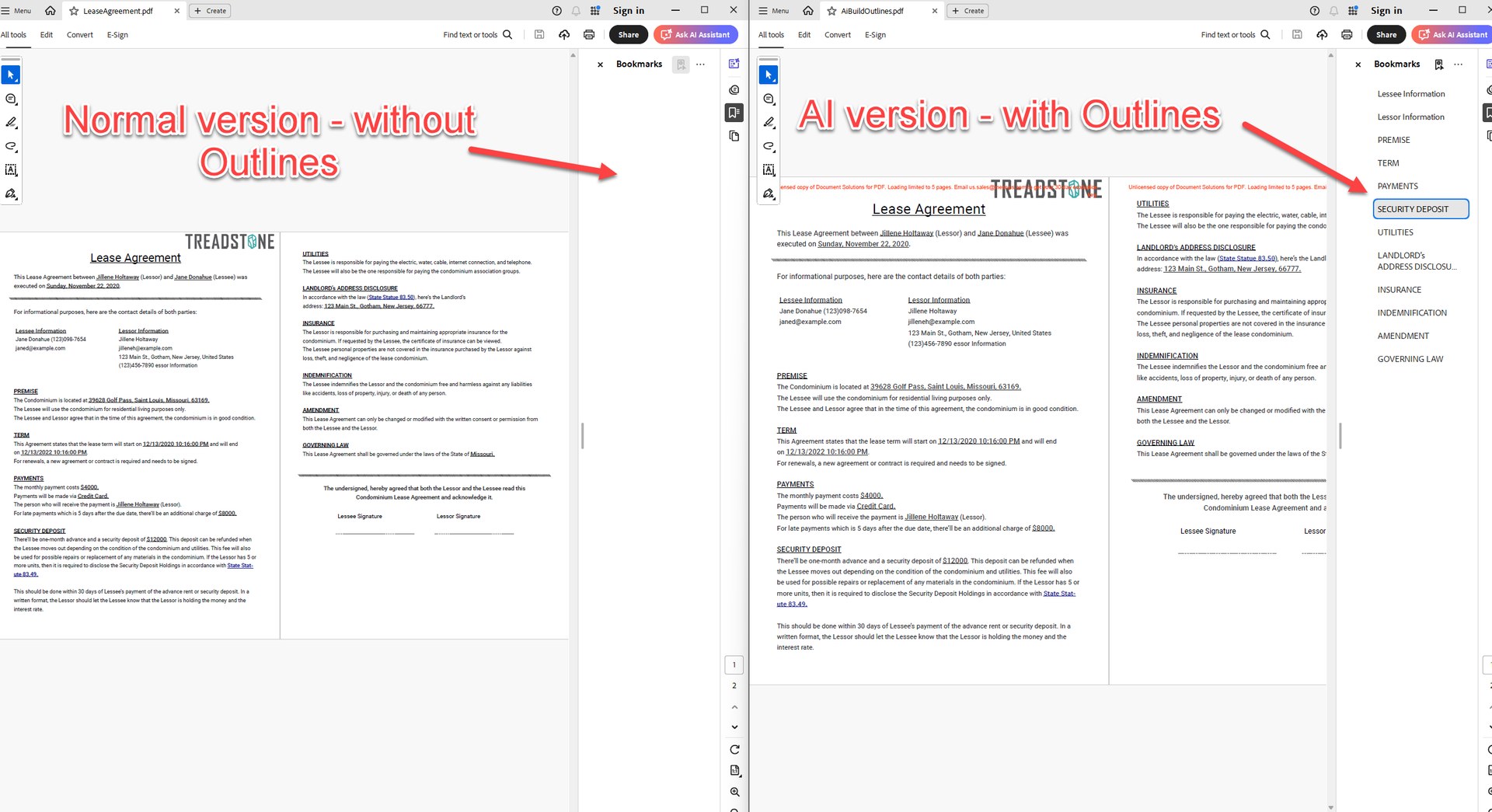
构建文档大纲树 - 自动生成结构化目录,并包含嵌套大纲层级。
-
借助 .NET PDF API 中集成的 AI 功能,自动生成结构化目录。
![]()
-
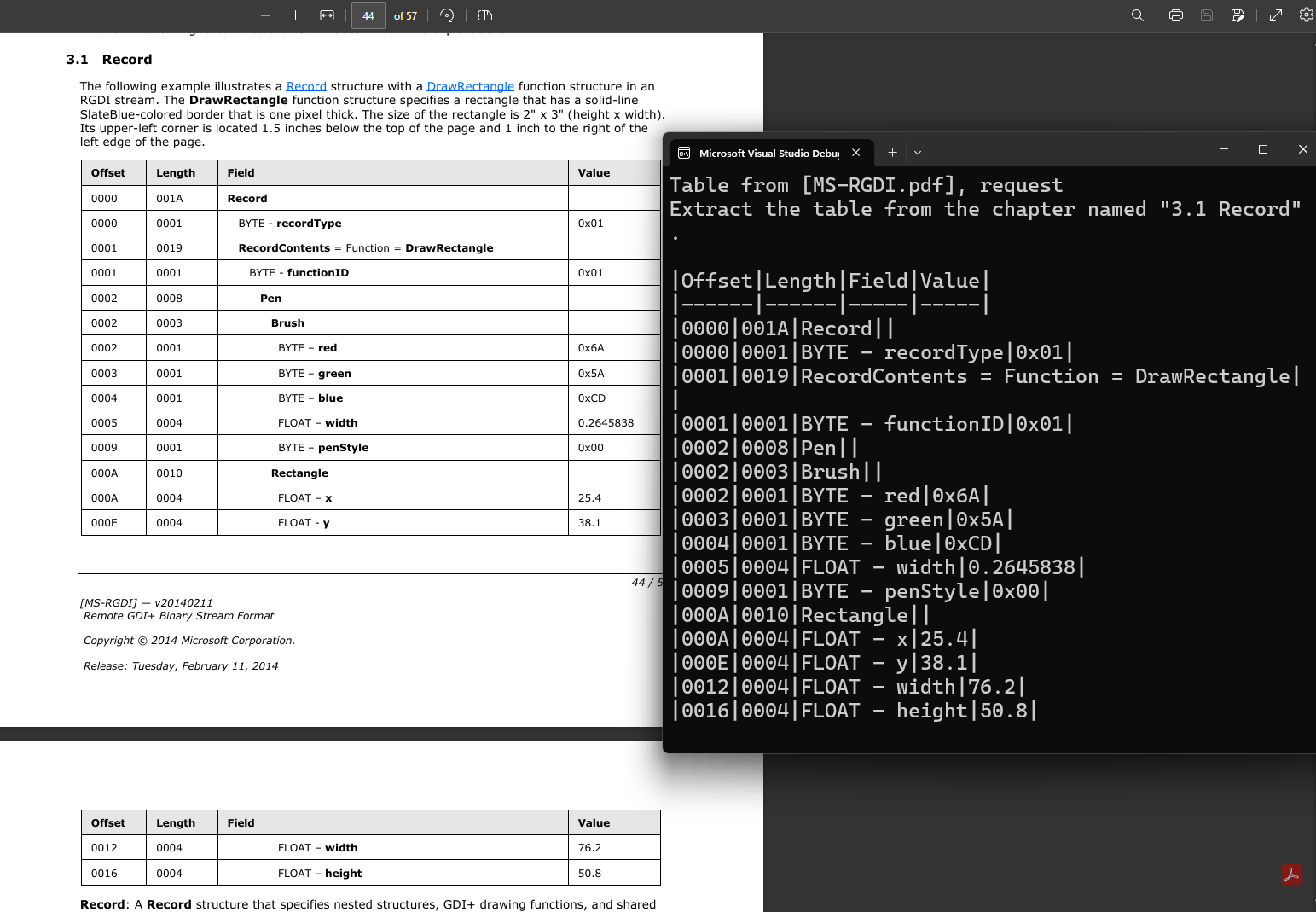
从文档中提取表格 - 通过自然语言提示,从 PDF 中识别并提取表格数据。
-
利用 PDF API 的 AI 功能从 PDF 中提取表格。
![]()
上述功能均基于 OpenAI Chat API 构建,支持通过两种方式连接:一是通过官方 OpenAI .NET 客户端库,二是通过 Azure OpenAI 服务。
API 概述
该新软件包包含两个主要类,二者均继承自同一个用于实现核心功能的基类:
- OpenAIDocumentAssistant:通过官方 .NET 客户端库连接至 OpenAI REST API。
- AzureOpenAIDocumentAssistant:通过 Azure.AI.OpenAI 软件包连接至 Azure OpenAI 服务。
这两个类均派生自 OpenAIDocumentAssistantBase 基类,该基类实现了两项关键逻辑:一是通过 Page.GetText() 方法提取文本,二是将内容发送至 AI 服务进行处理。其中,pageRange 参数允许开发人员将请求范围限定在 PDF 的特定章节。
以下代码示例展示了如何在 GcPDF 中实现人工智能驱动的功能:
支持的平台
- OpenAI REST API(通过官方 .NET 客户端连接)
- Azure OpenAI 服务(通过 Azure.AI.OpenAI 软件包连接)