香港大学和快手可灵团队近日联合发表论文《Context as Memory: Scene-Consistent Interactive Long Video Generation with Memory Retrieval》,提出一种创新性方法:将历史生成的上下文作为“记忆”(即Context-as-Memory),通过context learning 技术学习上下文条件,从而实现对长视频前后场景一致性的有效控制。研究发现:视频生成模型能够隐式学习视频数据中的 3D 先验,无需显式 3D 建模辅助,这一理念与 Genie 3 不谋而合。
为了高效利用理论上可无限延长的历史帧序列,论文还提出了基于相机轨迹视场(FOV)的记忆检索机制(Memory Retrieval),从全部历史帧中筛选出与当前生成视频高度相关的帧作为记忆条件,大幅提升视频生成的计算效率并降低训练成本。
在数据构建上,研究团队基于 Unreal Engine 5 收集了多样化场景、带有精确相机轨迹标注的长视频,用于充分训练和测试上述技术。用户只需提供一张初始图像,即可沿设定的相机轨迹自由探索生成的虚拟世界。
根据介绍,Context as Memory可以在几十秒的时间尺度下保持原视频中的静态场景记忆力,并在不同场景有较好的泛化性。Context as Memory 方法旨在实现无需显式三维建模的场景一致的长视频生成。该方法的核心创新包括:
- 提出了 Context as Memory 方法,强调将历史生成的上下文作为记忆,无需显式3D建模即可实现场景一致的长视频生成。
- 设计了Memory Retrieval方法,采用基于视场(FOV)重叠的相机轨迹规则进行动态检索,显著减少了需要学习的上下文数量,从而提高了模型训练与推理效率。
- 实验结果表明,Context as Memory在长视频生成中的场景记忆力表现优越,显著超越了现有的SOTA方法,并且能够在未见过的开放域场景中保持记忆。
![]()
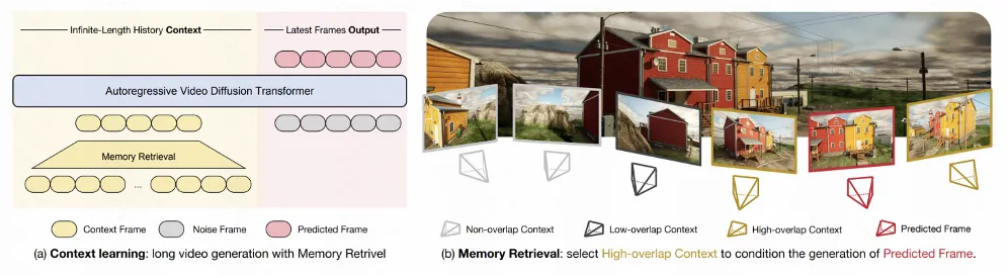
如上图(a)所示,Context-as-Memory的长视频生成是通过基于Context learning的视频自回归生成来实现的,其中,所有历史生成的视频帧作为context,它们被视为记忆力的载体。
如上图(b)所示,为了避免将所有历史帧纳入计算所带来的过高计算开销,提出了Memory Retrieval模块。该模块通过根据相机轨迹的视场(FOV)来判断预测帧与历史帧之间的重叠关系,从而动态筛选出与预测视频最相关的历史帧作为记忆条件。此方法显著减少了需要学习的上下文数量,大幅提高了模型训练和推理的效率。
在实验中,研究者将 Context-as-Memory 与最先进的方法进行了比较,结果表明,Context-as-Memory 在长视频生成的场景记忆力方面,相较于这些方法,表现出了显著的性能提升。
![]()