作者:vivo 互联网大数据团队- Quan Limin
本文是vivo互联网大数据团队《vivo Pulsar万亿级消息处理实践》系列文章第1篇。
文章以Pulsar client模块中的Producer为解析对象,通过对Producer数据发送原理进行逐层分析,以及分享参数调优实战案例,帮助读者理解与使用好Producer,并体会到Producer对消息中间件系统稳定性以及处理性能所起到的关键作用。
一、Pulsar 简要介绍
![图片]()
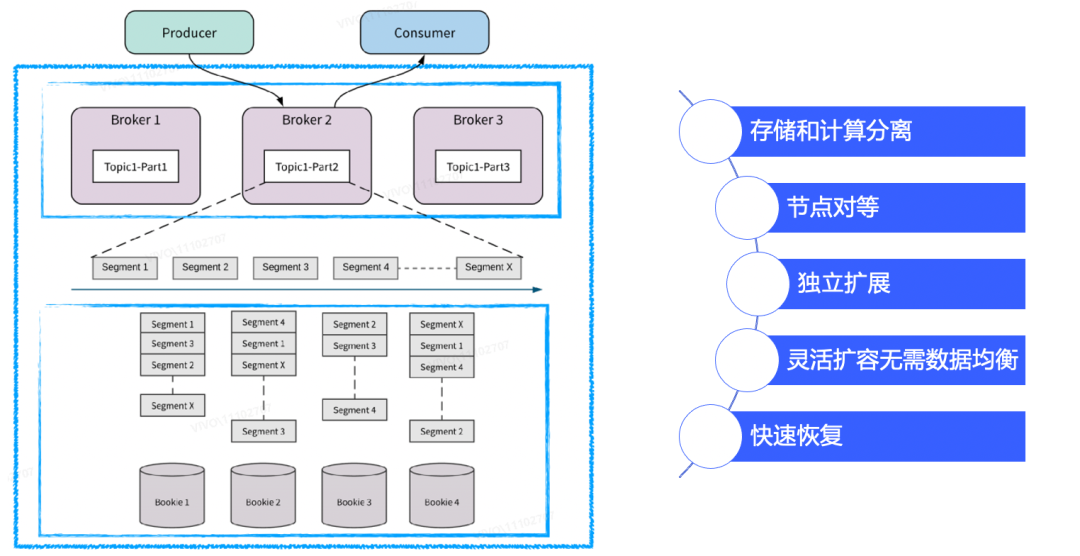
Pulsar是新一代的云原生消息中间件,由Apache软件基金会孵化和开源。它的设计目的是为了满足现代数据处理和计算应用程序对可扩展性、可靠性和高性能的需求,具备存储与计算分离、节点对等、独立扩展、实时均衡、节点故障快速恢复等特性。
Pulsar由四个核心模块组成:broker、bookKeeper和client(Producer和Consumer)、zk(元数据管理和节点协调)。broker接受来自Producer的消息,将消息路由到对应的topic;bookKeeper用于数据持久化存储和数据复制;Consumer消费topic上的数据。Pulsar支持多种编程语言和协议(如Java、C++、Go、Python等),可以运行在云、本地和混合环境中,扩展性好,支持多租户和跨数据中心复制等特性。因此,Pulsar被广泛应用于云计算、大数据、物联网等领域的实时消息传递和处理应用中。
二、Pulsar Producer解析
首先需要了解Producer的数据发送流程,这里以“开启压缩、batch发送消息给partitioned topic“这样的一个线上常规场景为例,解析数据的发送的关键环节。
tips:
在Pulsar中有无分区(Non-Partitioned)Topic 和有分区 (Partitioned) 的 Topic之分,Partitioned topic最小分区数为1,为满足任务的拓展性,在线上一般使用Partitioned topic。
2.1 消息生产与发送的详细流程
![图片]()
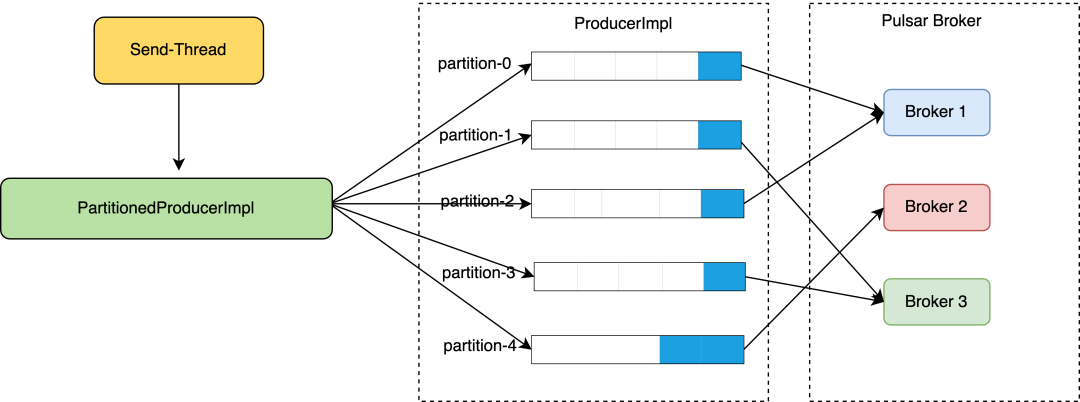
Producer发送数据主要分为12个步骤:
① 创建Producer:
partitioned topic创建的是一个Partitioned-
ProducerImpl对象,该对象包含了所有分区及其对应的ProducerImpl对象,ProducerImpl对象负责所对应分区数据的维护和发送。
② 构造消息:
一条消息被发送前首先会被封装成为一个Message对象,对象中包含了所发送的topic name、消息体、消息大小、schema类型、metadata(是否指定key等)等信息。
③ 确定目标分区:
在发送消息前需要通过路由策略决定发往哪一个分区,选择对应分区的ProducerImpl对象进行进一步处理。
④ 拦截器:
Producer可以设置自定义的拦截器,拦截器需要实现producerInterceptor接口,在消息发送前可对消息进行拦截修改。
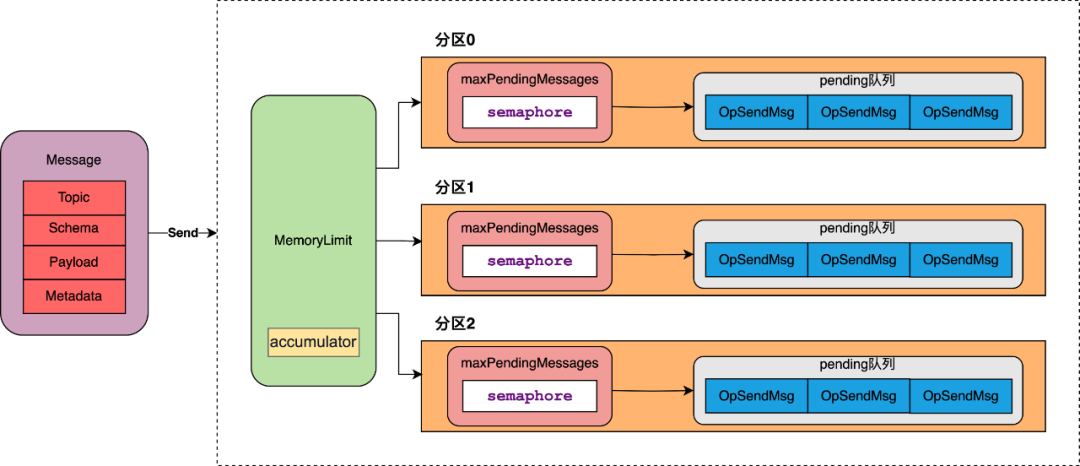
⑤ 消息堆积控制:
Producer可以处理的消息是有限的,接收新的消息时会分别进行信号量和内存使用率校验,控制接收消息的速率,防止消息无限在本地堆积。
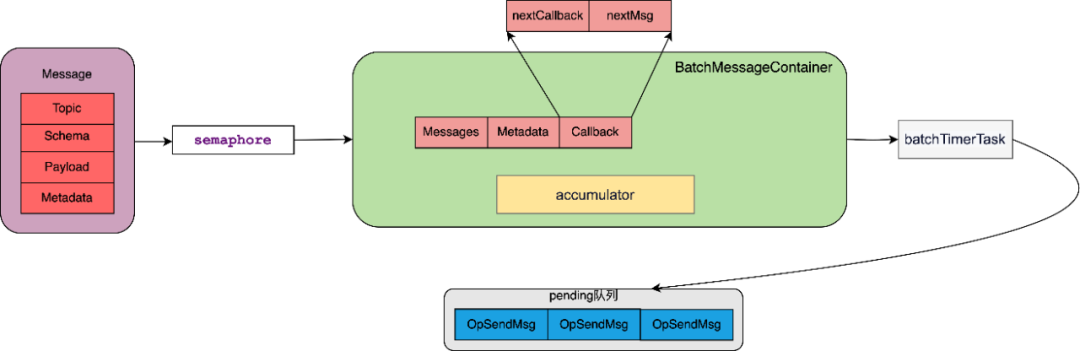
⑥ batch容器管理:
默认情况下分好区的消息不是直接被发送,而是放入了生产者的一个batch缓存容器中里面。在这个缓存里面,多条消息会被封装成为一个批次(batch)。
⑦ 消息序列化:
Pulsar 的消息需要从客户端传到服务端,涉及到网络传输,因此Producer将batch缓冲区中的所有消息逐一进行序列化。
⑧ 压缩:
Pulsar内置了多种压缩算法,在发送前会根据所选择的压缩算法对batch整体进行压缩,这将优化网络传输以提高Pulsar消息传输的性能。
⑨ 构建消息发送对象:
无论是开启batch的批次消息,还是关闭batch的单条消息,都会被包装为一个OpSendMsg对象,OpSendMsg也是Producer发送和pulsar broker接收处理的最小单位。
⑩ pending队列:
所有构建好的OpSendMsg在发送前都会被放入pendingMessages队列中,消息处理完成后才会从队列中移除。
⑪ 消息传输:
Pulsar 使用netty将消息异步的从客户端发送到服务端,Broker节点将在收到消息后对其进行确认,并将其存储在指定主题的持久存储中。
⑫ 响应处理:
Pulsar Broker 在收到消息时会返回一个响应,如果写入成功,消息将会从pendingMessages队列中移除。如果写入失败,会返回一个错误,生产者在收到可重试错误之后会尝试重新发送消息,直到重试成功或超时。
2.2 关键环节原理分析
接下来会对上述流程中关键环节的设计和原理作进一步的剖析,帮助读者更好的理解Producer。
2.2.1 创建Producer
![图片]()
在Pulsar中,PartitionedProducerImpl用于将多个ProducerImpl对象包装成为一个逻辑生产者,以便向Partitioned Topic发送消息时能够批量操作。其中,PartitionedProducerImpl.producers成员变量维护了每个分区及其对应的ProducerImpl对象,该设计主要有以下3个好处:
① 每个分区对应一个单独的生产者:
在Pulsar中,Partitioned Topic按照分区(Partition)将多个 ProducerImpl 对象进行分配,以便能够同时发往多个 Broker 节点,因此对于每个分区,需要拥有一个单独的生产者以便进行发送操作。在 PartitionedProducerImpl 类中,需要为每个分区维护一个 ProducerImpl 对象,以便在消息被分配好“目标分区”后可以调用对应的ProducerImpl进行处理。
②简化代码逻辑:
在PartitionedProducerImpl中,将每个分区及其对应的ProducerImpl对象维护在一个HashMap中,能够更加方便的维护并管理不同分区的生产者,使得代码逻辑更加清晰简明。
③ 提高容错性:
当某个分区的ProducerImpl对象无法工作时,可以选择其他可用的ProducerImpl对象,从而保证系统整体的可用性。由于将不同分区的ProducerImpl对象分别进行维护,因此具备更加灵活的容错处理策略。
在线上实践中我们也基于该设计,在PartitionedProducerImpl层做了进一步优化,通过感知下一层每个ProducerImpl的阻塞状态(信号量的使用情况)来决定新的消息发送,避免将消息持续发往阻塞较为严重的分区,规避了topic被某一个分区阻塞而影响到整体发送性能的情况,也提高了线上系统的稳定性,具体的实现可以详见这篇文章《构建下一代万亿级云原生消息架构:Apache Pulsar 在 vivo 的探索与实践》。
关键代码:
//对每一个分区都创建一个ProducerImpl对象
private void start(List<Integer> indexList) {
AtomicReference<Throwable> createFail = new AtomicReference<Throwable>();
AtomicInteger completed = new AtomicInteger();
for (int partitionIndex : indexList) {
createProducer(partitionIndex).producerCreatedFuture().handle((prod, createException) -> {
.......
});
}
}
private ProducerImpl<T> createProducer(final int partitionIndex) {
return producers.computeIfAbsent(partitionIndex, (idx) -> {
String partitionName = TopicName.get(topic).getPartition(idx).toString();
return client.newProducerImpl(partitionName, idx,
conf, schema, interceptors, new CompletableFuture<>());
});
}
2.2.2 确定目标分区
在发送消息前需要决定发往哪一个分区,确定好分区后便调用对应分区的ProducerImpl对象进一步处理,目标分区的确定主要跟“路由策略”和“是否指定key”有关:
**(1)如果消息没有指定key:**则按照三种路由策略的效果选择分区进行发送,三种路由策略如下:
如果消息没有指定Key,Producer会随机选择一个 Partition,然后把所有的消息都发送到这个 Partition上。
生产者将以轮询方式在所有 Partition之间发布消息,以实现最大吞吐量。需要注意的是如果开启了batch发送,则轮询将会以批为单位进行消息发送,批次发送时每隔partitionSwitchMs会轮询一个 Partition。如果关闭了批量发送,那么每条消息发送都会轮询一个Partition。(partitionSwitchMs至少为一个batchingMaxPublishDelay时间)。
使用用户自定义的消息路由实现,根据自定义的 Router实现决定消息要发往哪个分区。用户自定义的 Router可以通过 messageRoute参数设置。自定义的 Router需要实现 MessageRouter接口的 choosePartition方法。
**(2)如果消息指定key:**则会对Key做哈希处理,然后找到对应的 Partition,把key所对应的消息都发送到同一个分区:
对消息的Key进行哈希处理后如何找到对应的 Partition的?即使用Key的哈希值对总的 Partition数取模:N=(Key的哈希值%总的 Partition数),得到的N就是第N个 Partition,Producer可以通过设置 hashingscheme来使用不同的哈希算法 ,现在已经支持 JavastringHash和 Murmur3_32Hash两种哈希算法,前者直接调用String.hash.Code(),后者使用Murmur3。
路由策略的关键代码如下:
//SinglePartition路由策略:
public int choosePartition(Message<?> msg, TopicMetadata metadata) {
// If the message has a key, it supersedes the single partition routing policy
if (msg.hasKey()) {
return signSafeMod(hash.makeHash(msg.getKey()), metadata.numPartitions());
}
return partitionIndex;
}
//RoundRobin路由策略:
public int choosePartition(Message<?> msg, TopicMetadata topicMetadata) {
// If the message has a key, it supersedes the round robin routing policy
if (msg.hasKey()) {
return signSafeMod(hash.makeHash(msg.getKey()), topicMetadata.numPartitions());
}
if (isBatchingEnabled) { // if batching is enabled, choose partition on `partitionSwitchMs` boundary.
long currentMs = clock.millis();
return signSafeMod(currentMs / partitionSwitchMs + startPtnIdx, topicMetadata.numPartitions());
} else {
return signSafeMod(PARTITION_INDEX_UPDATER.getAndIncrement(this), topicMetadata.numPartitions());
}
}
2.2.3 消息堆积控制
![图片]()
Producer不可能无限接收新的消息,如果某些分区数据发送较慢,消息就会堆积在Prouducer缓存中,导致已经阻塞的分区堆积大量的消息,又无法重新发往其他分区,同时也可能因为无限堆积的消息占用了大量的内存,使得任务频繁GC甚至OOM。
在Pulsar提供了两个核心的速率限制策略和一个阻塞时的消息处理策略:
maxPendingMessages控制每个分区某一时刻最大可处理消息数量,通过信号量的方式控制“新进入的消息”的信号量分配和“处理完成消息“的信号量释放,防止某个分区的消息严重堆积。
memoryLimit控制整个Pulsar client的消息最大占用内存大小,通过计数器方式控制“新进入的消息”有效载荷的内存分配和“处理完成消息“有效载荷的内存释放,这里需要特殊说明的是memoryLimit是client的参数,针对的是该client对象下的所有topic,因此并不建议一个Pulsar client对象new多个Producer topic ,因为很容易出现某一个topic占用内存过多,导致另一个topic无空间可分配的情况。
由blockIfQueueFull进行控制,当blockIfQueueFull为true时,代表阻塞等待,Producer会等待获取信号量;当blockIfQueueFull为false时,一旦获取不到信号量,就会立刻失败,需要注意的是如果blockIfQueueFull为false,业务需要处理好消息失败后的回调策略,否则会导致数据在Producer上“丢失”。
关键代码如下:
public void sendAsync(Message<?> message, SendCallback callback) {
......
MessageImpl<?> msg = (MessageImpl<?>) message;
MessageMetadata msgMetadata = msg.getMessageBuilder();
ByteBuf payload = msg.getDataBuffer();
int uncompressedSize = payload.readableBytes();
//对发送队列大小以及client memory进行判断是否有空间放入新的消息
if (!canEnqueueRequest(callback, message.getSequenceId(), uncompressedSize)) {
return;
}
......
}
private boolean canEnqueueRequest(SendCallback callback, long sequenceId, int payloadSize) {
try {
if (conf.isBlockIfQueueFull()) {
//当blockIfQueueFull为true时,等待获取信号量
if (semaphore.isPresent()) {
semaphore.get().acquire();
}
//分配消息有效载荷所需要的内存空间
client.getMemoryLimitController().reserveMemory(payloadSize);
} else {
//当blockIfQueueFull为false时,如果无法获取到信号量,则快速失败
if (!semaphore.map(Semaphore::tryAcquire).orElse(true)) {
callback.sendComplete(new PulsarClientException.ProducerQueueIsFullError("Producer send queue is full", sequenceId));
return false;
}
//如果没有如何的内存空间用于消息分配,则报错
if (!client.getMemoryLimitController().tryReserveMemory(payloadSize)) {
semaphore.ifPresent(Semaphore::release);
callback.sendComplete(new PulsarClientException.MemoryBufferIsFullError("Client memory buffer is full", sequenceId));
return false;
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
callback.sendComplete(new PulsarClientException(e, sequenceId));
return false;
}
return true;
}
2.2.4 消息batch容器打包
![图片]()
(1)batch关键组成信息
-
Messages: 保存消息的list,保存跟这个batch相关所有的MessageImpl对象。
-
**Metadata:**保存batch相关的元数据,如批量消息的序列号、消息发送的时间戳等信息。
-
**Callback:**保存消息回调逻辑的集合,记录了每一条消息对应的callback策略,在batch消息发送并等到服务端响应后,依次对消息的回调进行处理。
(2)batch打包条件
batch打包条件的三个关键参数:满足其一数据就会被打包发送出去。
batchingMaxPublishDelay
Pulsar使用两个模块设计来实现上面的参数控制:
- **accumulator:**在 BatchMessage-
ContainerImpl 中通过计数器的方式去控制batch的大小和条数,numMessages-
InBatch记录已经缓存的消息数量,currentBatchSizeBytes用于记录已缓存的消息的大小。当这些变量达到阈值时,BatchMessageContainerImpl 将会触发批量消息的发送。
- **batchTimerTask:**当生产者使用批量消息发送模式时,Producer将会创建一个定时器任务(batchTimerTask),并通过计时器的方式定时将BatchMessageContainer容器中的消息进行批量发送。
2.2.5 消息压缩
如果开启了消息压缩,在发送前都需要进行压缩处理。对于单条消息发送的场景,是对每一条消息进行单独压缩后进行发送;而如果开启了batch则是对整个batch进行压缩后再整个进行发送。
在线上实践中,推荐在不影响业务延迟的情况下batch越大越好,主要有两个理由:
不论Producer发送的是一条消息还是一批消息,在pulsar客户端都会被构建为一个OpSendMsg对象,同时pulsar broker接收到消息进行写入处理时,也是按照OpSendMsg为一个处理单位将消息写入磁盘,因此当消息数量一定时,batch越大,则代表需要处理的OpSendMsg越少。
压缩算法对应的压缩率并不固定,它通常取决于所要压缩的数据对象的内容和压缩算法本身,压缩的本质在于通过消除或利用数据中存在的冗余来实现数据的压缩和重构。而Pulsar是以batch来进行打包的,batch越大,压缩的目标包体越大压缩效果则可能越好,同时也能够尽可能避免单条消息因为包体较小导致越压缩后包体越大的情况出现。
以下是开启了batch情况下,构建发送消息和压缩的关键代码:
public OpSendMsg createOpSendMsg() throws IOException {
//对数据进行压缩、加密等操作
ByteBuf encryptedPayload = producer.encryptMessage(messageMetadata, getCompressedBatchMetadataAndPayload());
......
ByteBufPair cmd = producer.sendMessage(producer.producerId, messageMetadata.getSequenceId(),
messageMetadata.getHighestSequenceId(), numMessagesInBatch, messageMetadata, encryptedPayload);
//对整个batch构建一个OpSendMsg
OpSendMsg op = OpSendMsg.create(messages, cmd, messageMetadata.getSequenceId(),
messageMetadata.getHighestSequenceId(), firstCallback);
......
return op;
}
//对batch进行压缩,并将压缩后信息更新到messageMetadata中
private ByteBuf getCompressedBatchMetadataAndPayload() {
......
int uncompressedSize = batchedMessageMetadataAndPayload.readableBytes();
ByteBuf compressedPayload = compressor.encode(batchedMessageMetadataAndPayload);
batchedMessageMetadataAndPayload.release();
......
return compressedPayload;
}
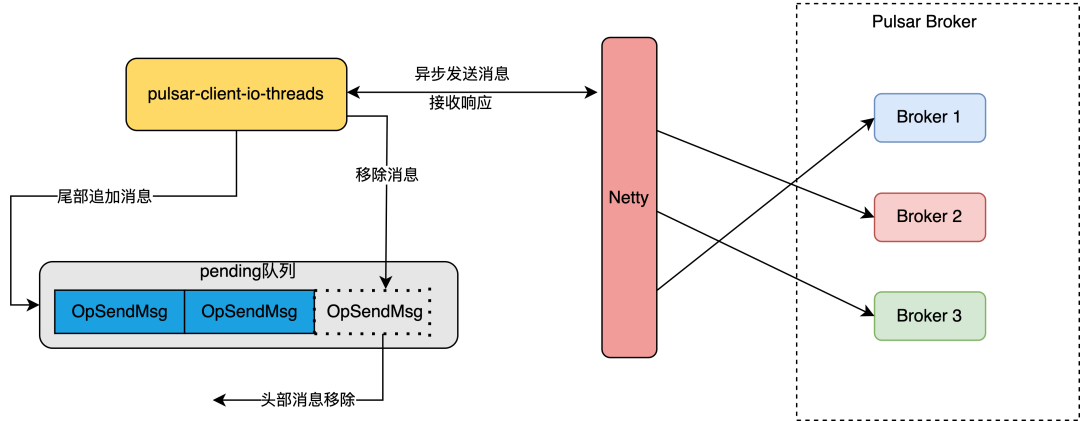
2.2.6 pending队列
![图片]()
Pulsar 中的 pendingMessages队列是客户端用来暂存“未处理完成的消息”的一个缓存队列。用于存储当Producer连接到 Broker 服务器后,还未发送或尚未得到 Broker 系统的 ACK 确认的所有生产者(Producer)的消息。在发送消息之前,Producer 首先会将消息缓存到 pendingMessages 队列中,并记录保存缓存消息的OpSendMsg对象,直到它被成功发送到了 Broker 端并收到 Broker 发送的ACK 确认之后,相关的元信息和消息信息才会从队列中移除。
需要注意的是:pending队列的本质是一个回调处理队列,而不是发送队列,消息在放入pending队列的同时就被异步发送到服务端了,所以这里需要重点理解什么是“未处理完成的消息”。
pendingMessages 队列的作用在于:对于已经发送但尚未收到 ACK 确认的消息,防止在连接出现异常时丢失消息。当连接中断时,缓存在 pendingMessages 队列中的未确认消息将被认为是需要重发的,当连接恢复时,缓存的消息将重新发送到 Broker 端,以确保生产者生产的消息不会丢失。
**总的来说,**pendingMessages 队列是 Pulsar 客户端保证消息可靠性和一致性的关键功能组件,在 Pulsar 的生产者(Producer)和消息确认的机制中担任着非常重要的角色。
关键代码如下:
add() 方法用于在追加消息时将指定元素插入队列中的队尾,remove() 用于消息在完成后移除队列头部的元素。
protected void processOpSendMsg(OpSendMsg op) {
if (op == null) {
return;
}
try {
if (op.msg != null && isBatchMessagingEnabled()) {
batchMessageAndSend();
}
//将消息放入“待处理消息队列”
pendingMessages.add(op);
......
// If we do have a connection, the message is sent immediately, otherwise we'll try again once a new
// connection is established
op.cmd.retain();
cnx.ctx().channel().eventLoop().execute(WriteInEventLoopCallback.create(this, cnx, op));
stats.updateNumMsgsSent(op.numMessagesInBatch, op.batchSizeByte);
......
}
//添加消息到pendingMessages队列
public boolean add(OpSendMsg o) {
// postpone adding to the queue while forEach iteration is in progress
//batch的计数是按照batch中消息的总量进行计数
messagesCount.addAndGet(o.numMessagesInBatch);
if (forEachDepth > 0) {
if (postponedOpSendMgs == null) {
postponedOpSendMgs = new ArrayList<>();
}
return postponedOpSendMgs.add(o);
} else {
return delegate.add(o);
}
}
//将消息从pendingMessages队列移除
public void remove() {
OpSendMsg op = delegate.remove();
if (op != null) {
messagesCount.addAndGet(-op.numMessagesInBatch);
}
}
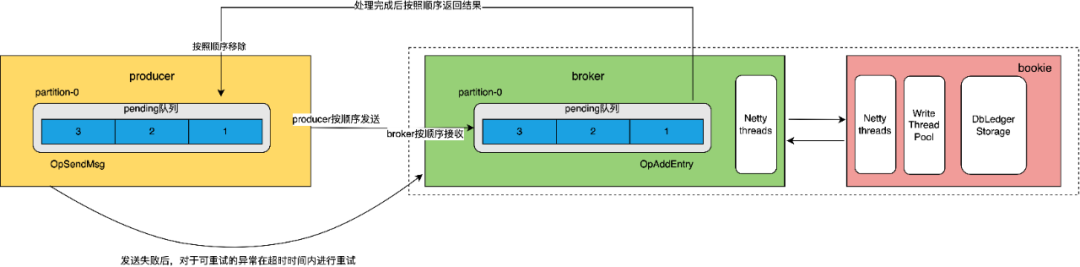
2.2.7 消息传输
![图片]()
Producer和broker都维护了分区维度的pending队列来保证消息处理的顺序性,以及实现消息重新发送、重新写入持久化存储的能力。在Producer端,消息被顺序追加到pending队列并异步发送到服务端,服务端的pending队列在接收到消息后,按照顺序追加到队列中,并按照顺序将数据写入bookie进行持久化处理,处理完成后按照顺序返回响应Producer,并将消息从broker pending和producer pending队列中移除。
另外在数据传输过程中,无论是使用Pulsar Producer的同步发送还是异步发送,在消息传输环节本质上都是使用netty将消息异步的从客户端发送到服务端,区别在于send() 方法封装了 sendAsync() 方法,使其可以在向服务器发送 Pulsar 消息时阻塞等待 Broker 的响应,直到确认消息已经被 Broker 成功处理后才会返回,常规情况下,建议使用异步的方式发送 Pulsar 消息,因为同步方式必须在 Broker 端成功接收到消息之后才会返回,因此会带来较大的性能损耗和延迟。但是在部分场景下,需要使用同步方式来保证可靠性,以防 Broker 端接收失败,可以考虑使用 send() 方法实现同步方式的方式发送 Pulsar 消息。
使用netty执行的代码:
private static final class WriteInEventLoopCallback implements Runnable {
......
@Override
public void run() {
if (log.isDebugEnabled()) {
log.debug("[{}] [{}] Sending message cnx {}, sequenceId {}", producer.topic, producer.producerName, cnx,
sequenceId);
}
try {
cnx.ctx().writeAndFlush(cmd, cnx.ctx().voidPromise());
op.updateSentTimestamp();
} finally {
recycle();
}
}
......
}
2.2.8 处理响应
![图片]()
Pulsar Producer 使用“ACK 跟踪机制”来实现对 Broker 返回的 ACK 确认消息的处理,用于检测和处理到达生产者的全部消息状态信息。
对于Producer发送的消息,Pulsar会对每个消息分配一个唯一的 sequenceId 序号,并记录该消息的创建时间(createdAt)等元数据信息。当 Broker 确认收到某个消息时,Producer 会依据返回的 ACK 序号和 Broker 返回的确认时间来判断当前 ACK 是否有效,并从已缓存的 pendingMessages 队列中找到对应的消息元数据信息,以进行确认处理,在 Broker 确认消息接收成功时,Producer 将从等待确认的消息队列中删除对应的消息元数据信息,如果 Broker 返回的 ACK 消息不符合生产者预期的消息状态信息,Producer 将会重发消息,直到重试成功或多次重试失败后抛出异常后再从队列中移除对应消息元数据信息并释放对应内存、信号量等资源。
消息重发的关键代码如下:
private void resendMessages(ClientCnx cnx, long expectedEpoch) {
cnx.ctx().channel().eventLoop().execute(() -> {
synchronized (this) {
//判断连接状态:当连接正在关闭或者已经关闭则不进行重发
if (getState() == State.Closing || getState() == State.Closed) {
// Producer was closed while reconnecting, close the connection to make sure the broker
// drops the producer on its side
cnx.channel().close();
return;
}
......
//调用重发消息方法
recoverProcessOpSendMsgFrom(cnx, null, expectedEpoch);
}
});
}
// Must acquire a lock on ProducerImpl.this before calling method.
private void recoverProcessOpSendMsgFrom(ClientCnx cnx, MessageImpl from, long expectedEpoch) {
......
final boolean stripChecksum = cnx.getRemoteEndpointProtocolVersion() < brokerChecksumSupportedVersion();
Iterator<OpSendMsg> msgIterator = pendingMessages.iterator();
OpSendMsg pendingRegisteringOp = null;
while (msgIterator.hasNext()) {
OpSendMsg op = msgIterator.next();
......
op.cmd.retain();
if (log.isDebugEnabled()) {
log.debug("[{}] [{}] Re-Sending message in cnx {}, sequenceId {}", topic, producerName,
cnx.channel(), op.sequenceId);
}
//发送消息
cnx.ctx().write(op.cmd, cnx.ctx().voidPromise());
op.updateSentTimestamp();
stats.updateNumMsgsSent(op.numMessagesInBatch, op.batchSizeByte);
}
cnx.ctx().flush();
......
}
三、Pulsar 数据发送端参数调优实践
根据以上对原理解析,我们对Producer已经有了一个大致理解,下面通过一个Producer参数调优实践案例来帮助读者基于原理进一步理解客户端参数之间的联系。
3.1 调优目的
首先要清楚为什么要进行参数调优,有以下两个目的:
Pulsar client和Producer的几十个配置参数,参数多且联系紧密,需要花费较多的时间成本去理解,同时参数之间存在协同生效互相影响的情况,对普通使用者而言场景复杂理解门槛高,我们希望能够有一套较为通用的参数配置,或有公式化的参数配置方法论。
站在客户端的角度,相同时间内处理的数据量越多,则认为单机处理性能更强。作为中间件系统的提供者,我们经常认为性能提升是服务端的事情,想尽办法在pulsar的broker和bookie上去提升单机处理性能,但pulsar client作为整个消息中间件系统的核心组件,它能否发送好一份数据,对整个消息中间件系统的性能和稳定性也发挥着至关重要的作用。
3.2 调优实践
下面就围绕“参数通用模版化”和“提升单机处理性能”两个目的出发并结合上述讲解的数据发送原理,来分享一些实践经验。
3.2.1 关联与场景相关的重点参数
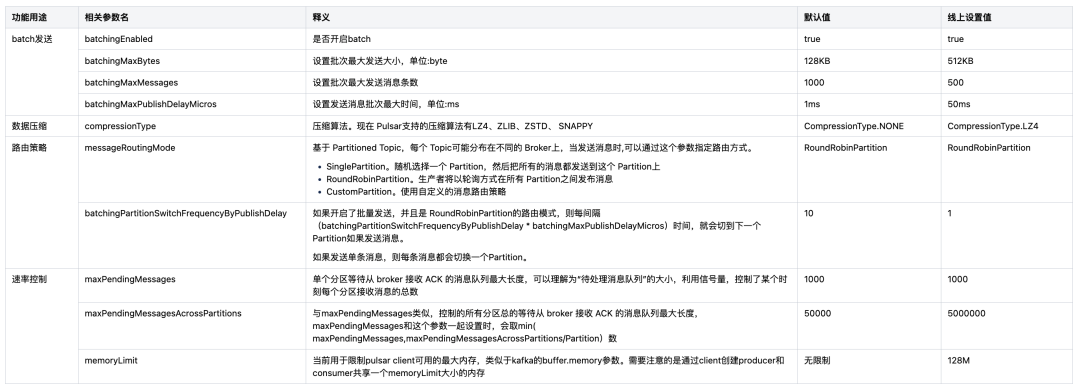
Pulsar客户端参数虽多但都提供了默认值,不需要一一调整。只需要对业务场景相关的针对性的去调整即可,如我们本次的参数调优目的是提升单机处理性能,则重点关注哪些场景哪些参数可以提升客户端的发送速率、降低服务端的压力,让服务端可以处理更多的数据,有以下四点最为关键:
消息多条批次发送,在降低客户端和服务端网络IO的同时也降低了两者的cpu的负载。这里需强调的是我们希望batch是一个均匀的、“完整”的包,如pending队列被打满,batch只能空等到延迟发送时间过后被发送,没有构建出预期中的batch,那么可以认为这个batch是一个不完整的包,这种batch包含的数据量少,对发送效率有着极大的影响。
Pulsar是IO密集型系统,常规情况下磁盘是系统的主要瓶颈,开启压缩可以有效降低网络I/O,提升处理相同数据量下的读写能力。由于压缩是针对batch的,在发送时间一定的情况下,batch越大其压缩效果也越好,代表着处理的消息量也更多。
将数据均匀地分配到多个分区中。它的基本思想是轮询将新的数据写入到不同的分区中,以均衡地分散负载。
maxPendingMessages信号量和memoryLimit限制不直接提升发送速率,但它能够有效保障我们客户端的稳定,也是控制或限制发送效率的重要参数之一。
涉及的客户端关键参数以及默认值和我们线上调优后设置的数值如下表:
![图片]()
3.2.2 结合Producer发送原理分析参数的效果
接下来我们以参数的效用角度来描述一条消息从构建到发送的过程,进一步解释参数如此设置的意义:
(1)选择分区
构建消息后,通过messageRoutingMode参数所设置的路由策略来选择分区,这里以RoundRobinPartition为路由策略,开启batch时则每间隔partitionSwitchMs时间换一个分区进行数据发送,partitionSwitchMs的值为“batchingPartitionSwitchFrequencyByPublish
-Delay、batchingMaxPublishDelayMicros”这两个Producer参数之积,也就是每batchingPartition
-SwitchFrequencyByPublishDelay个batch的最大打包时间,消息就会轮换一个分区发送。
为了能在batchingMaxPublishDelayMicros内得到一个较大的包,我们希望这个batch接收的消息是连续的,因此batchingPartitionSwitchFrequency-
ByPublishDelay不能小于1,同时也希望一个分区之间数据是较为均匀的,所以batchingPartition-
SwitchFrequencyByPublishDelay也要尽量小,否则分区对应的信号量maxPendingMessages耗尽还没有切换分区,就会导致batch必须等待一个batchingMaxPublishDelayMicros时间。因此将batchingPartitionSwitchFrequencyByPublishDelay修改成了1,保证打包了一个batch之后就切换分区,这也极大的避免了分区信号量耗尽,出现发送阻塞。
(2)消息堆积控制
maxPendingMessages作为分区的信号量,也是“pending队列”的大小,代表着每个分区能够同时处理的最大消息上限,而maxPendingMessages-
AcrossPartitions则是针对整个topic生效的,maxPendingMessages=min( maxPending-
Messages,maxPendingMessagesAcrossPartitions/Partition),由于线上分区可能会变化,有不确定性,因此就使用上而言除非有特殊的使用场景,建议将maxPendingMessagesAcrossPartitions设置的比较大,让maxPendingMessages生效即可。
除了maxPendingMessages以外,消息能否接收被放入pending队列中,还要看当前正在处理的消息体大小总和是否超过了memoryLimit参数的限制,memoryLimit控制了消息待处理队列中未压缩前的消息有效荷载总和,可以避免在消息有效荷载非常大时,还未触发maxPendingMessages限制,就导致内存占用过多出现频繁GC和oom的问题。由于memoryLimit是client级别的策略,因此也建议一个client对应一个Poducer。
总而言之maxPendingMessages控制了每个分区可以处理消息数量的上限,memoryLimit控制了所有分区可以消息占用内存的上限,两者相辅相成。
(3)消息batch容器打包
决定一个batch是否打包完成有三个条件控制,batchingMaxBytes、batchingMaxMessages、batchingMaxPublishDelayMicros满足其一即可,根据这三个参数的含义去设置值看似是容易的,但容易忽略的是batch中用来打包的消息也是受memoryLimit和maxPendingMessages制约的,应该避免出现batch中消息的数量超过memoryLimit和maxPendingMessages导致batch打包效率受影响。举个例子,当maxPendingMessages设置为500,而batchingMaxMessages设置1000时,batch就永远无法满足消息条数达到1000的条件,只能空等batchingMaxPublishDelayMicros或者batchingMaxBytes两者生效。
3.2.3 公式化模版
通过上述分析,大致了解了关键参数的生效效果,且彼此相互关联,根据这些关系就能够输出一个较为简单的参数调优模版。
假设我们发送的单条消息大小为:messageByte;分区数量为:partitionNum。
那么对应参数调整公式如下:
//业务发送速率越大,这里设置的值越大
maxPendingMessages:一般1000-2000之间
//这里值也可以设置大一些,让maxPendingMessages生效即可
maxPendingMessagesAcrossPartitions = maxPendingMessages * partitionNum
//memoryLimit的值就是打算阻塞总消息大小,这与消息体和maxPendingMessages有关
memoryLimit=(maxPendingMessages * partitionNum * messageByte)
//batch的条数不超过“待处理消息队列”大小的一半
batchingMaxMessages=maxPendingMessages/2,这样可以保证在消息发送等待ack的时候,该分区剩下一半的空间还能用来构建一个batch
//batch大小同理,batch大小不超过“待处理消息队列”消息大小的一半
batchingMaxBytes= Math.min(memoryLimit * 1024 * 1024 /partitionNum/2,1048576)
//业务能够接受的延迟大小,一般延迟时间越大,batch越大
batchingMaxPublishDelayMicros=1ms-100m皆可
//每构建一个batch就转换一个分区
batchingPartitionSwitchFrequencyByPublishDelay=1
可以看到根据上面的分析,参数之间是有一个模版化的公式,但这也不是唯一的,读者可以根据自己的业务场景进行调整。在真实使用过程中线上的消息大小以及分区数量实际上是会变化的,因此真正的参数设置还需要根据实际情况来确定,比如我们线上通常的做法是根据机器配置将memoryLimit直接设置为64M-256M,分区数量我们线上不会超过1000,那么这里就假设为1000,确定了这两个参数,其他的参数的值也就确定了。
3.2.4 效果对比
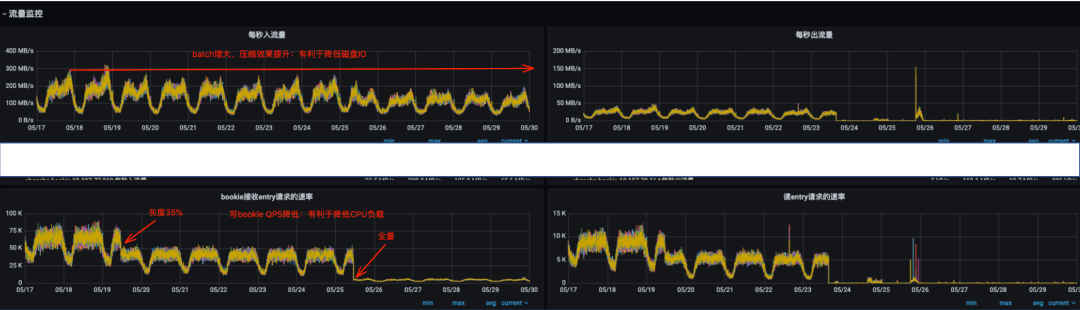
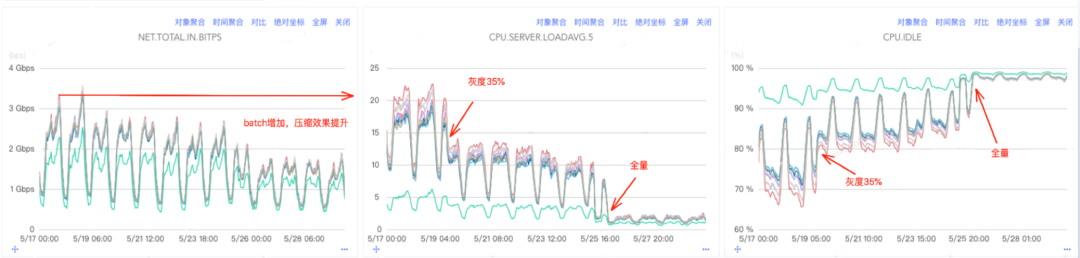
以线上一个业务参数调优为例,前后都开启压缩的情况下调整上述参数后的一个效果。
服务端(Pulsar):
![图片]()
![图片]()
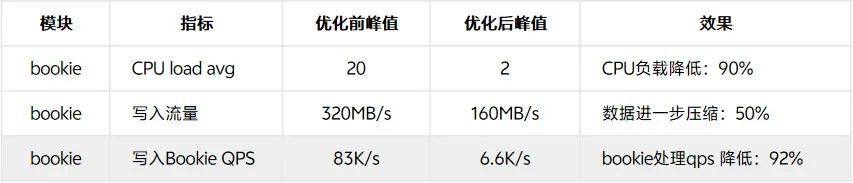
优化前后对比数据:
![图片]()
相同的写入速率,Pulsar服务端网卡流量缩减约50%(batch包体增加,压缩效果提升),cpu负载降低约90%,Pulsar服务端总体成本相较优化前至少可降低50%以上,客户端也有一定程度的负载降低。
参数调整后,CPU负载得到明显降低,一定程度上避免了CPU成为系统的瓶颈,同时由于压缩效果的提升,Pulsar 的磁盘IO负载得到显著降低,可以用更少的机器处理更多的数据。
四、总结
理解Producer发送原理以及核心参数是写好数据发送程序最为有效的手段,最简单的客户端参数优化反而隐藏了巨大的收益。本文通过对Producer原理进行剖析、对消息的流转过程中参数效用进行讲解,并配合参数调优实践案例,介绍了具体的分析思路和调优的方法,在实际使用过程中通过对核心的几个上游系统进行调优,服务端单机处理能力至少提升了一倍以上,成本得到了极大的降低。
参考文章:
https://pulsar.apache.org/docs/4.0.x/concepts-overview/