6月初,太原市小店区商务局举办“提振消费2025暨抱鼓巷夜经济AR景观发布仪式”。作为山西省首个5G+AR全场景数字商业街区标杆项目,通过“科技+文化+惠民”三重赋能,为太原夜经济注入强劲动力。
【苹果(AAPL.US)公布“无摄像头眼动追踪系统”专利,意在打造更轻薄AR眼镜】
6月5日消息,美国专利商标局公开了一项来自苹果的专利申请,揭示了一种无需摄像头的下一代眼动追踪系统。这一技术突破对于苹果未来的AR眼镜和智能眼镜产品具有重要意义,可在不依赖摄像头的前提下实现高效精确的眼部追踪,同时大幅减小设备体积与复杂度。
【Meta(META.US)斥资数百万美元拉拢好莱坞,为下一代头显打造独家沉浸式内容】
据《华尔街日报》报道,Meta正积极游说好莱坞影视公司为其Horizon OS生态打造独家沉浸式视频内容,并已向包括迪士尼与独立电影厂牌A24在内的多家公司开出数百万美元的内容采购报价。
【高通(QCOM.US)骁龙AR2芯片推动AR眼镜技术飞跃】
获悉,高通骁龙AR2芯片成为AR技术革新的核心驱动力,通过采用创新的多芯片架构,骁龙AR2成功实现了端侧算力提升3倍的显著成效。
在实际应用中,这意味着用户在使用AR眼镜时,即使处于网络信号不佳的环境,也能获得稳定且高效的AR体验。在实现强大算力的同时,骁龙AR2芯片在轻量化设计方面也取得了令人瞩目的成绩。
这一轻量化设计极大地提升了用户佩戴的舒适度,使得长时间佩戴AR眼镜成为可能,无论是日常出行、办公,还是娱乐场景,用户都能轻松自在地使用AR眼镜。
【小鹏汽车(XPEV.US)联合华为发布「追光全景」车载AR-HUD】
6 月 5 日,小鹏汽车与华为智能汽车解决方案联合发布了名为「追光全景」的车载 AR-HUD。该抬头显示系统融合了小鹏的 AI 智驾算法与华为的 AR-HUD 光学技术。
核心参数方面,该 AR-HUD 配备了车规级 LCoS 显示芯片+第二代车规级 PGU 成像模组,可实现 87 英寸超大画幅、12000nits 的超高亮度和 1800:1 的对比度,确保在各种光线条件下画面清晰。
同时,该系统最大的创新在于将 AI 智驾与视觉引导深度结合。其打造的 AR 车道级导航,能将导航指引以光毯形式精准贴合在真实道路上,实现“所见即所行”。在智能辅助驾驶时,它能更直观地展示 AI 的决策逻辑,增强驾驶者信任感。
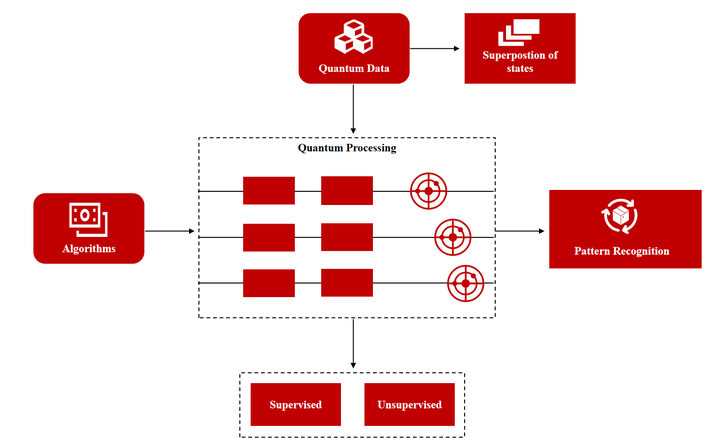
【微美全息(WIMI.US)布局可扩展量子卷积神经网络,提升图像分类精度与效率】
在当今科技飞速发展的时代,量子机器学习(QML)作为一个极具前瞻性的研究领域,越来越受关注。它巧妙地融合了量子计算的强大能力与机器学习方法,旨在处理海量数据并攻克具有挑战性的问题,展现出超越传统计算机的巨大潜力。
与此同时,卷积神经网络(CNN)在图像分类等领域凭借其比传统神经网络更高效的特征提取能力,展现出显著的技术优势。然而,传统的CNN在训练过程中对计算资源的巨大需求,以及量子机器学习面临的量子比特和量子计算机可扩展性受限等问题,成为了阻碍这两项技术进一步发展的瓶颈。
在此背景下,纳斯达克上市企业微美全息,正积极探索可扩展量子卷积神经网络(SQCNN)技术。与现有的量子神经网络模型相比,微美全息研究的可扩展量子卷积神经网络模型展现出了卓越的性能,显著提升了分类精度,能够更加精准地提取图像中的关键特征,从而大幅提高了分类的准确性。
总之,微美全息探索的可扩展量子卷积神经网络不仅实现了特征提取的并行化与多维化,更以动态适配量子设备规模的能力,打破了传统模型在计算资源与任务复杂度间的矛盾。这一创新不仅显著提升了图像分类的精度与效率,更在泛化能力与训练成本间找到了平衡点,为自动驾驶、医疗影像分析等高实时性、高复杂度场景提供了技术支撑。
【三星(SSNGY.US)或在2026年推出新款智能戒指】
据消息,目前三星正在研发Galaxy Ring系列新品。知情人士透露,三星正在研发下一代Galaxy Ring,但产品目前处于开发状态,因此预测新品将不会在今年推出,有望在明年与三星Galaxy S26系列新机同期(或稍晚)推出。
参数上,Galaxy Ring还有望采用柔性设计。三星日前公布了一项关于柔性设计的专利申请。该设计能够确保传感器更好地贴合用户手指。
随着夏天的到来,HTC决定举办年中购物节,以提振自家的XR头显销量,时间从6月2日持续到6月30日,消费者可在HTC线上商店、各大电商平台、指定实体实体店等,购买XR头显,就能够享受独家好礼。
从HTC给出的独家好礼的情况来看,属于买XR头显送配件、送游戏,至于消费者的反应如何,也只能后续观察。