摘要:本文整理自Flink Forward Asia 2024大会中阿里云 DataWorks 数据集成团队陈吉通的分享,主要分享Flink CDC 在阿里云 DataWorks数据集成入湖场景的应用实践。内容分为以下四个部分:
1.阿里云 DataWorks 数据集成介绍
2.DataWorks 数据集成入湖解决方案的架构和原理
3.DataWorks 数据集成入湖场景的产品化案例分享
4.未来规划
一、阿里云 DataWorks 数据集成介绍
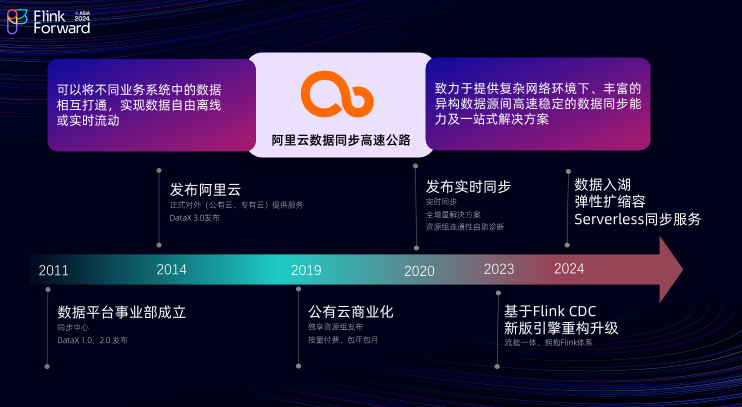
DataWorks 数据集成在阿里云具有悠久的历史
![]()
2011 年,阿里云数据平台事业部宣告成立,同年 DataX 1.0 与 2.0 版本相继发布;2014 年,阿里云DataWorks数据集成正式对外提供服务,同年 DataX 3.0 版本发布;2019 年, DataWorks数据集成在公有云上实现了商业化,推出了独享资源组服务,并提供了按量付费和包年包月两种灵活的计费方式;2020 年, DataWorks数据集成正式推出了实时同步服务,其中包括了全方位、一体化的数据集成解决方案,以及资源组网络连通性诊断工具;2023 年, DataWorks数据集成基于 Flink CDC 与 DataX 进行了新版引擎的升级,正式拥抱 Flink 体系;2024 年,DataWorks数据集成提供了数据入湖、弹性扩缩容以及 Serverless 同步服务。
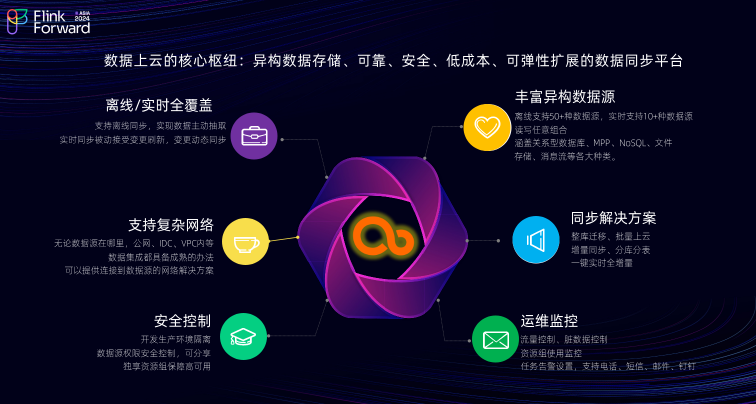
数据集成的定位是数据上云的核心枢纽,致力于打造一个可靠、安全、低成本且可弹性伸缩的异构数据源之间的数据同步平台。
![]()
数据集成目前已实现实时与离线同步能力的全覆盖,支持超过五十种离线数据源之间的互导,以及十多种数据源之间的实时互导;数据集成还支持复杂网络环境的打通,无论用户的数据源位于公网 IDC 、 VPC 还是其他网络环境中,数据集成都提供了成熟的解决方案,能够确保用户数据源与数据集成系统之间的网络可达性;数据集成还为用户提供了一站式同步解决方案,涵盖了迁移批量上云、增量同步以及分库分表一键实时同步等功能;同时数据集成借助 DataWorks 在生产环境与开发环境之间的隔离优势,能够确保安全控制的有效实施; 此外数据集成还为用户提供了流量控制、脏数据控制、资源组指标监控等服务;支持用户设置任务级别的告警通知,通知方式涵盖电话、短信、钉钉、邮件等多种渠道。
DataWorks数据集成的业务规模十分庞大
![]()
DataWorks 数据集成服务业务规模日同步数据量约为 10 PB ,数据条数则达到了约 10 万亿。同时DataWorks 数据集成服务于阿里集团 130 多个 相关BU ,覆盖 21 个公有云区域,以及 180 多个专有云客户,其中包括国家电网、城市大脑等。
二、DataWorks 数据集成入湖解决方案的架构和原理
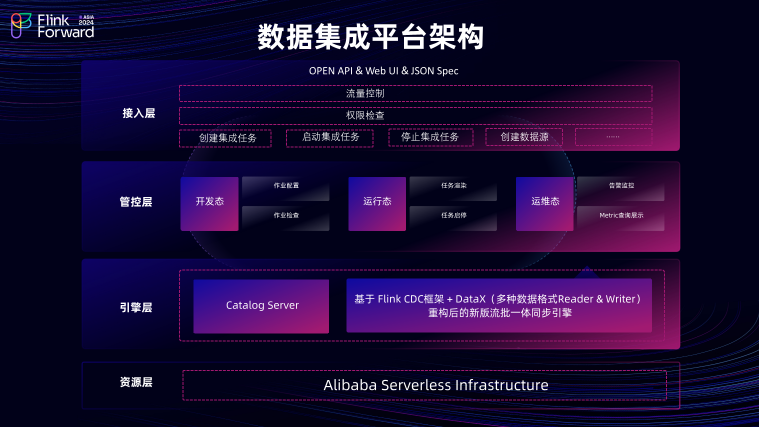
数据集成平台的架构,主要可分为四个部分,包含接入层、管控层、引擎层、资源层。
![]()
-
在接入层,用户可以通过 Open API 、 Web UI 以及JSON Spec来进行任务的配置,这包括创建数据同步任务、启停数据同步任务以及数据源的创建。
-
在管控层,数据集成平台会对用户创建的任务进行对应的作业检查、作业配置以及任务的启停和渲染。此外还提供了一些运维态的指标告警监控,以及 Metric查询展示功能。
-
在引擎层,包含两个服务,一个是Catalog Server 数据源服务,主要是与用户配置的数据源打交道,可以提供批量建表和获取表Meta 信息等服务。另外一个是真正执行数据同步的引擎,该引擎是基于 Flink CDC框架 + DataX重构后的新版流批一体同步引擎。
-
资源层为Alibaba Serverless Infrastructure。
数据集成入湖解决方案的架构特点
![]()
-
从功能特性方面来看数据集成提供了一站式的结构迁移和全增量同步的解决方案。支持源头数据库DML 和 DDL 事件的全事件流解析,确保数据的完整性和一致性。同时还为用户提供了丰富的T节点能力,以满足多样化的数据处理需求。
-
在性能与成本方面支持Sink实时写多表,以提高数据同步的效率。在数据分发过程中采用 PK shuffle(主键分发)来避免数据热点问题,确保数据分布的均衡性。此外还支持弹性扩缩容能力,能够根据业务高峰期和低峰期的需求,灵活调整资源分配,以优化性能和降低成本。
基于 Flink CDC 的数据集成入湖解决方案的引擎架构原理
![]()
-
源头支持多种数据源,包括关系数据库,如 MySQL 、 PostgreSQL 以及实时的消息流,如 Kafka、Loghub 等。利用 Flink CDC Source 实现全量和增量的数据摄取。
-
事件解析组件,将源头的Event事件转化为 Insert 、 Update 、 Delete 及 Alter 等操作类型。
-
在数据分发层按照主键做Hash分发,能有效避免源头热点表数据问题。
-
TableMapping组件,做数据的映射转发,将源头的Event事件映射到目的表,确保数据传输的准确性。同时提供了一系列丰富的T节点能力,涵盖了字符串替换、数据脱敏、JSON解析、数据过滤以及逻辑删除等能力,以满足用户多样化的数据处理需求。
-
在 Flink CDC 基础上实现了包括 Paimon 、Hudi、Iceberg等多种湖格式的Sink pipeline支持,能够实现DML 数据以及DDL在目的端重放。此外在入湖场景下也支持将 Paimon 、 Hudi、Iceberg等表结构的元数据同步到阿里云的 DLF上。用户在配置入湖同步解决方案时,可以选择将元数据构建在阿里云的 DLF 上,而实际的数据存储则依托于阿里云的 OSS 或 OSS-HDFS 文件存储服务。
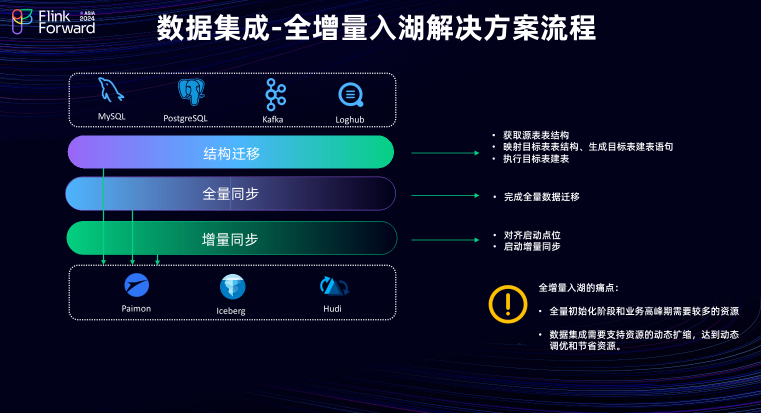
数据集成-全增量入湖的解决方案流程![]()
数据集成整库入湖解决方案主要分为下面三个流程步骤
-
结构迁移:其核心工作在于获取源头表的表结构信息,并将其映射到目的端表结构,同时生成目的端所需的建表语句并执行建表。
-
全量同步:完成从源头数据库到目的端的历史数据迁移。
-
增量同步:在全量同步完成后需进行位点对齐操作,并启动增量同步。增量同步能够实时捕捉源头数据和表的Schema变化,并将其同步到目的端,从而保持数据的实时性和一致性。
全增量入湖的过程中存在一些痛点:在全量同步阶段,由于用户可能积累了大量的数据,因此需要较多的资源来完成数据的迁移。此外在用户的业务高峰期期间也需要比较多的资源。
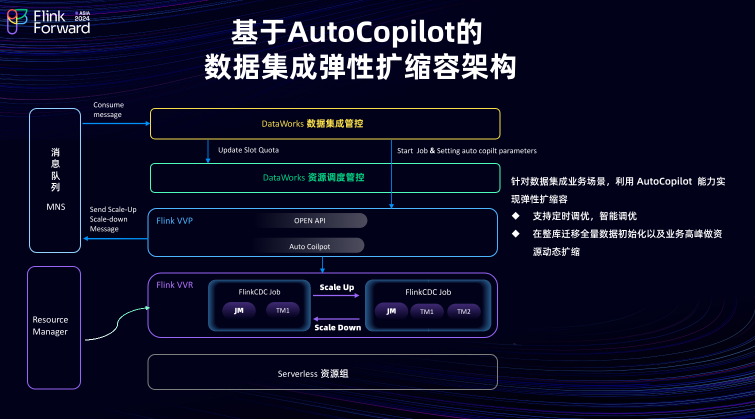
基于AutoCopilot的数据集成弹性扩缩容架构
![]()
数据集成需要解决的一个核心问题,如何根据用户的实际需求实现资源的动态伸缩。基于Flink Auto Copilot 机制,数据集成实现了弹性扩缩容机制。该功能的主要架构如下:
DataWorks数据集成管控系统与DataWorks资源调度管控进行交互,接收用户设置的调优参数,并将这些参数下发给 Flink VPP 。随后 Flink VPP 与 Flink VVR 进行交互, 根据用户设置的调优参数进行任务的弹性伸缩操作。当弹性伸缩完成后,相关消息会通过消息队列的方式发送给数据集成管控系统。数据集成管控系统在接收到这些消息后,会与 DataWorks 资源调度系统进行交互,更新资源分配情况,以实现资源的动态调整。
通过这一架构成功支持了用户的定时调优和智能调优需求。支持用户可以根据自己的业务场景,为对应的同步任务配置资源的弹性伸缩策略,从而确保数据同步的高效性和稳定性。
三、DataWorks 数据集成入湖场景的产品化案例分享
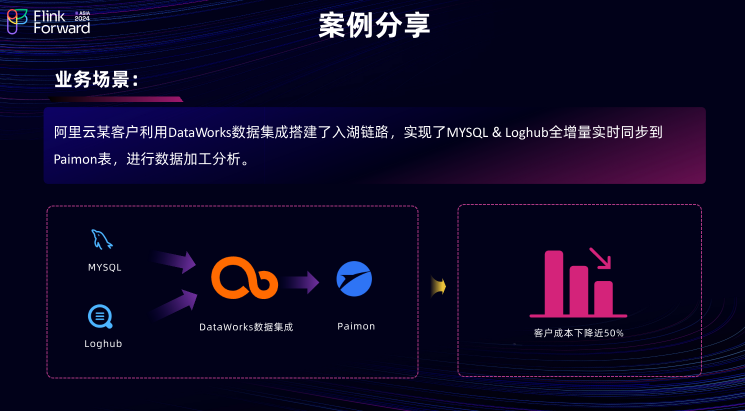
1. DataWorks 数据集成入湖场景的客户成功实践。
![]()
阿里云某客户利用 DataWorks 数据集成链路,成功搭建了一条入湖链路,实现了将源端 MySQL 的数据全增量同步到目的端的 Paimon表,进而进行数据加工和分析。借助 DataWorks 引擎的性能优势和弹性扩缩容架构,用户的成本最终下降了大约 50% 。
四、未来规划
未来规划主要包含以下三个部分:
![]()
-
计划支持更多的云端用户使用场景。
目前支持的源端主要包括 MySQL 、Loghub、 Kafka等,后续将拓展到更多的源头数据源,如 Oracle 、 Hive 等,以满足更广泛的用户入湖需求。
-
打造基于 AI 的任务诊断系统。
通过 AI大模型为用户提供任务的自助运维能力,提升任务管理的便捷性和效率。
-
推出数据质量检验功能。
数据质量检验功允许用户周期或实时地比对源端数据和目的端数据的准确性,确保数据在迁移和同步过程中的一致性和完整性。