作者:微财技术研发经理 宋鑫
微财介绍
微财是一家创新型的金融科技企业,凭借多年积累的金融科技能力和数据处理优势,为客户提供消费分期等金融信息服务,致力于成为值得信赖的金融机构合作伙伴。旗下拥有好分期等品牌,为高成长用户提供信用分期借款过程中的综合性信息、技术以及辅助服务。
业务挑战
数据资源是金融科技企业的核心价值,微财依托大数据评估用户借款过程中的风险,随着微财业务的快速发展,积累了大量用户数据,大数据集的训练逐渐成为瓶颈,其成熟度对业务的重要性不言而喻。根据性能、成本、安全、易用性、可靠性和扩展性等多维度评估,我们可以发现,要搭建一套成熟、稳定且高效的大数据模型训练平台需要耗费大量人力和时间成本。
选择 Spark 技术栈
在数据平台计算引擎层技术选型上,前期的架构选型我们做了很多的调研,综合各个方面考虑,希望选择一个成熟且统一的平台:既能够支持数据处理、数据分析场景,也能够很好地支撑数据科学场景。加上团队成员对 Python 及 Spark 的经验丰富, 且Spark拥有比较成熟的机器学习生态,所以,从一开始就将目标锁定到了 Spark 技术栈。
为什么选择阿里云EMR Serverless Spark
在机器学习场景下需要解决的问题,
-
一是要突破单机训练使用的数据规模的瓶颈;
-
二是要提高训练的效率,EMR Serverless Spark 的全托管服务、灵活的弹性扩缩容很好的满足了这两点问题,保证了用户级别的独立资源供给。
通过与阿里云计算平台EMR团队进行多方面的技术交流以及实际的概念验证,我们最终选择了阿里云EMR Serverless Spark。作为 一站式全托管湖仓分析平台,其自研 Fusion 引擎,内置高性能向量化计算和 RSS 能力,统一的数据工程和数据科学等,都是我们决定选择 Serverless Spark的重要原因。
具体来看,Serverless Spark提供的核心优势如下:
-
引擎性能大幅提升:自研 Fusion 引擎,内置高性能向量化计算和 RSS 能力,相对开源版本性能提升 3 倍以上;
-
完整 Spark 技术栈集成:支持使用 DataFrame、SQL、PySpark 等多种编程方式开发批、流、交互式分析、机器学习等不同类型的任务,并进行调度执行;支持通过 Spark Submit、Livy、Spark Thrift Server 等开源兼容的方式进行任务提交;提供内置 SQL Editor 和 Notebook,提供ETL和数据科学一体化开发体验;
-
Serverless 全托管服务:开箱即用,免运维,无需关注底层资源情况,降低运维成本,聚焦分析业务,秒级资源供给,按任务级别弹性扩缩容;
-
高品质支持以及SLA保障:阿里云提供覆盖Serverless Spark 的技术支持;提供商业化 SLA 保障与7*24小时 Serverless Spark 专家支持服务;
-
总成本降低:自研 Fusion 性能优势显著;同时基于计算存储分离架构,存储依托阿里云 OSS;能够有效降低集群总体使用成本。
“EMR Serverless Spark让我们有了单独的资源池进行模型训练,避免了资源冲突,同时还解决了我们在存算分离架构下需要处理shuffle稳定性和性能问题的困扰”
——微财产品技术研发负责人
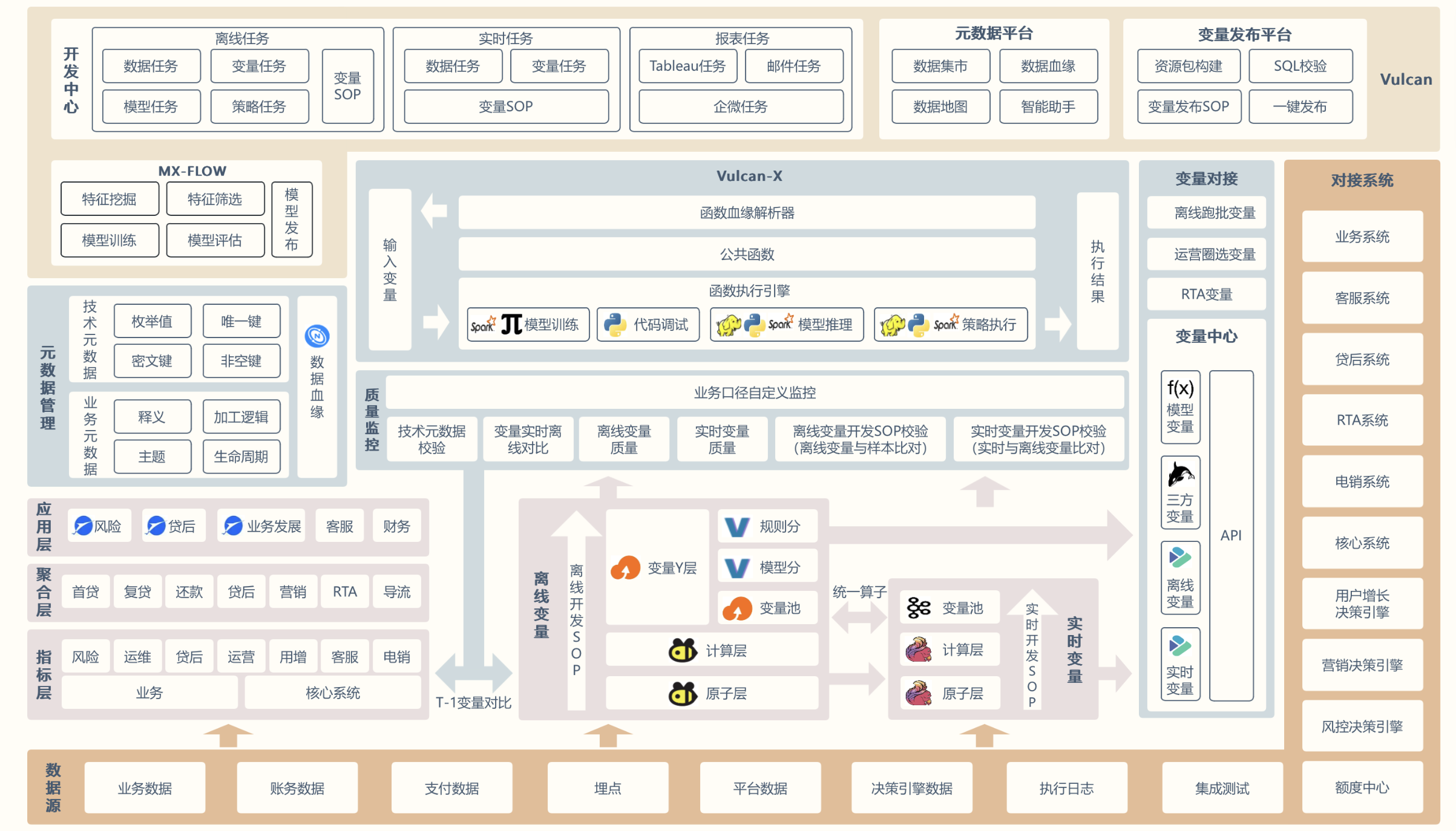
技术数据平台整体架构
![]()
数据采集
在微财数据仓库搭建的初期,我们自主研发了 dw-shell 工具,提供了完善的数据采集能力,并且屏蔽了存储引擎和计算引擎之间的差异。这一工具在我们的上云过程中发挥了至关重要的作用,帮助我们在一个月内完成了所有大数据计算任务的全量迁移。
数据入湖
在数据入湖方面,我们采用了 Apache Paimon 作为数据湖存储框架,并集成了 Apache Spark、Flink 和 Hive 作为计算引擎,构建了一个完整的数据湖生态系统。这一系统已经在实时数据监控和分析等场景中得到了成熟的应用,显著提升了我们的数据处理能力和业务效率。
数据科学
我们将机器学习的训练过程从单机训练迁移到了大数据集群,采用本地 Python 环境 + 云端训练的方式,将训练任务提交到 Serverless Spark,保证了本地开发灵活性的同时,充分利用了集群的计算资源,通过自研的模型开发框架vulcan-x,使分布式训练代码的编写、超参调优与本地开发无异,大幅降低了分布式训练代码编写的难度,基本消除了数据科学家开发的学习成本。
典型应用场景介绍
智能风控
![]()
为了帮助数据科学家无缝将训练任务迁移到 Serverless Spark执行,我们搭建了风控能力平台 MX FLow,提供以下几方面的能力。
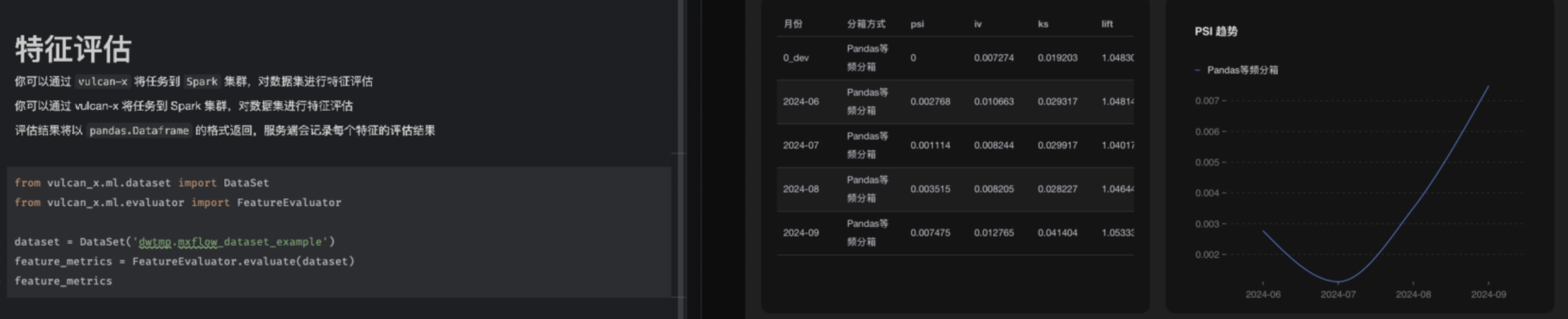
特征挖掘支持
我们在 Serverless Spark 实现了特征挖掘常用的分箱方法,如等频分箱、决策树分箱、卡方分箱等,以及特征评估的相关函数,支持用户使用分布式能力将特征离散化,评估特征的风险区分度。
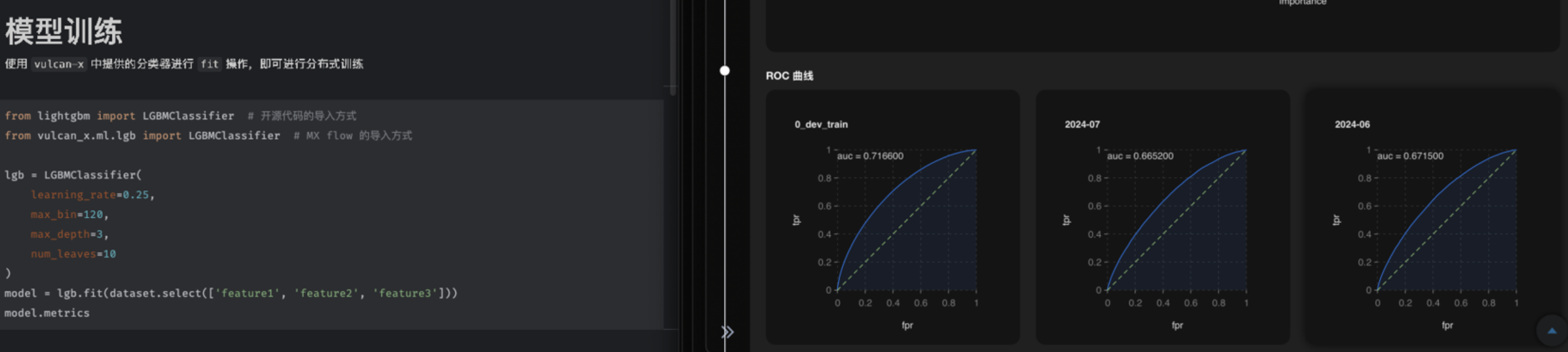
分布式训练
基于 Spark MLlib 成熟的机器学习生态,我们结合了 Spark MLlib内置算法、以及相关开源算法,如 SynapseML 提供的 lightgbm 分布式实现,为用户提供与本机训练相同的 API,截至目前累计支持了随机森林、逻辑回归、lightgbm、catboot、xgboost等算法。
![]()
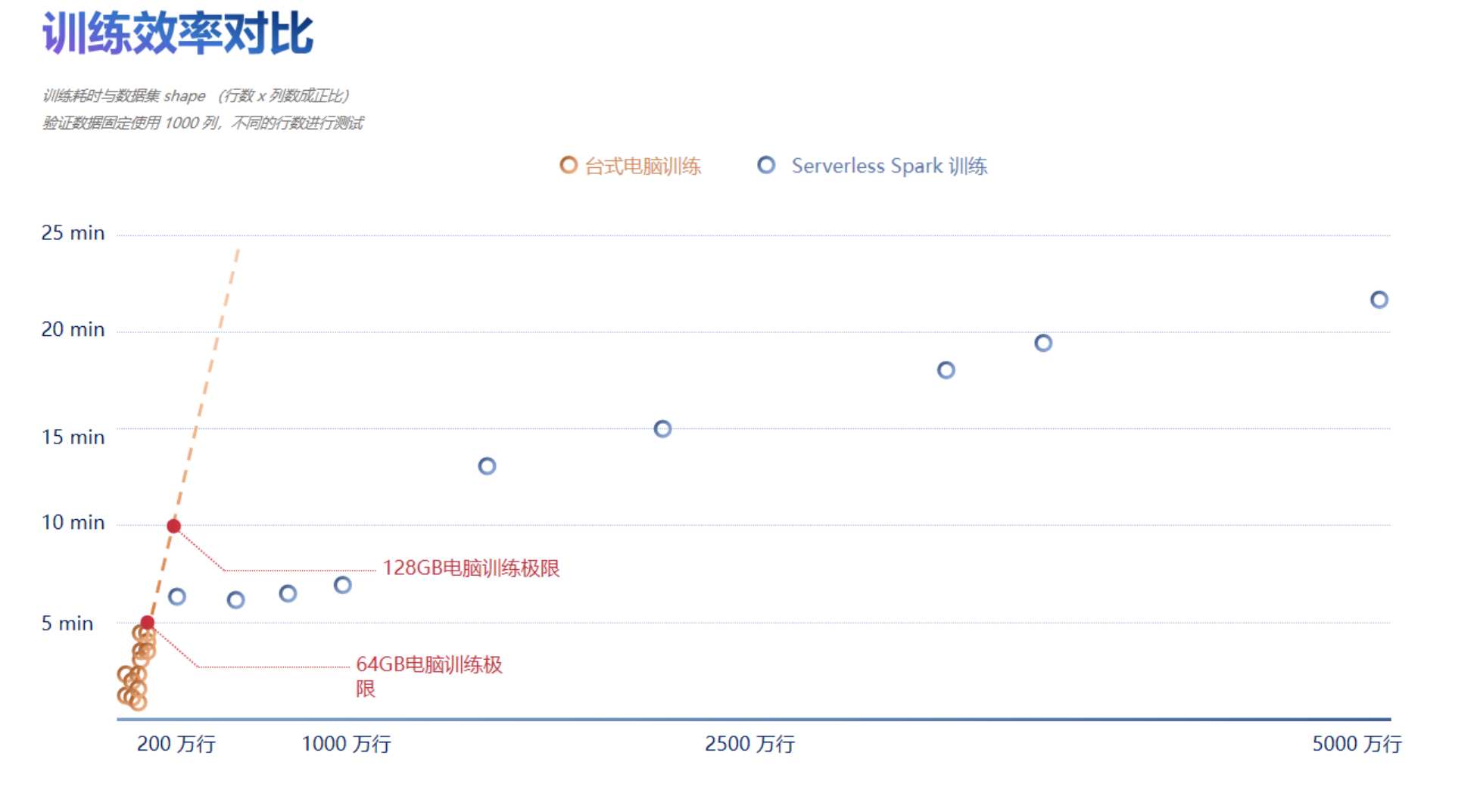
实际测试中发现,训练耗时基本与数据集的 shape(行数 x 列数) 成正比。在常用的训练 PC 上 400万行的训练集,机器内存已经达到瓶颈,使用 Serverless Spark 使用默认参数进行分布式训练,训练集 5000 万行时,训练耗时在 20 min 左右。
![]()
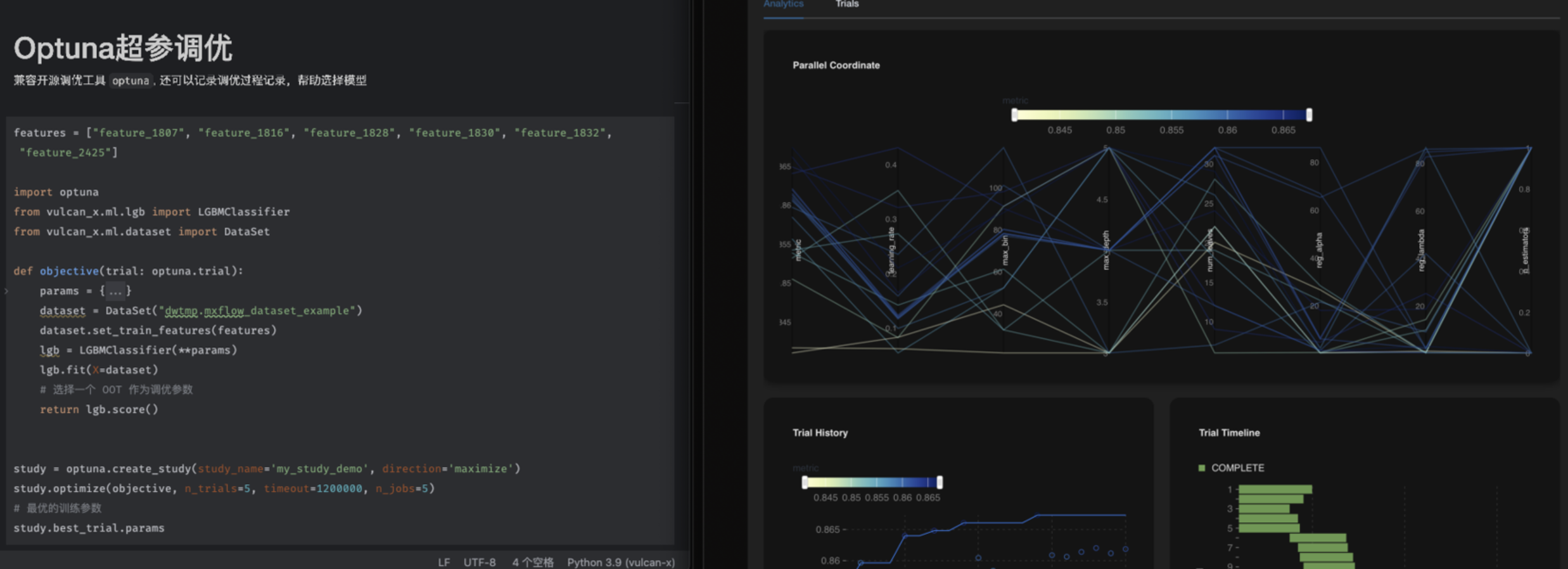
自动项目管理
MX Flow与vulcan-x配合使用,形成客户端与服务端的交互模式,用户在本地使用vulcan-x编写运行的代码产生的过程或结果数据,自动以数据集服务在服务端组织起来,提供可视化过程数据报告、模型管理等功能。服务端也提供了完整的超参调优功能,兼容开源工具 optuna,提供调优过程Dashboard。
![]()
![]()
![]()
![]()
总结与展望
随着微财业务数据量的不断增长,我们将会进一步拓展分布式训练的规模。微财在智能风控场景中已经开始深度学习能力的探索,利用多节点的分布式训练框架,如 Horovod、PyTorch Distributed 等,加速大规模深度学习模型的训练过程。未来也希望能够在 Serverless Spark 上能够使用到 GPU 训练的能力,共同探索分布式训练在深度学习领域的应用方向,提高训练效率和可扩展性。