春节期间,IT圈内两件大事持续发酵,一件是中国大模型DeepSeek R1的开源震动全球AI界,让中国科技界扬眉吐气,廉价大模型走入千家万户;另一件是SAP被客户居然之家告上法庭,要求索赔590万开发费用和1700万软件费用,最终法院判SAP退还350万研发费用。这两件事的背后,实际上映射了一个势不可挡的历史趋势:
大模型时代下,恐龙式软件生态的时代终结,猴群协作生态的时代兴起。
恐龙式软件,指的是试图做到面面俱到,以"一体化解决方案"覆盖企业所有需求的软件,如传统巨型的ERP系统。
猴群式软件,则是专注于某一领域的专业型软件,有比较强的技术专业性和专注度,企业需要通过灵活拼装多个软件,形成适合自己的解决方案,例如美国的SaaS软件生态。
![file]()
为什么SAP这类恐龙软件在中国逐渐没落?
SAP这些软件并非不专业,而是中国的零售业、制造业流程与管理模式,已经突破了SAP诞生时代的认知边界。换句话来说,当年在德国制造体系下流行的流程和制度难以满足中国智能制造2025的需求,因此必须升级。然而,适应中国市场的体系化软件尚未完全成型,而智能制造模式仍在剧烈变革,无法凝聚成固定的认知体系,也就无法凝聚成固定的新的"巨型"软件架构。
在这种环境下,体量庞大的软件,就像白垩纪的恐龙,在巨变中难以快速适应,而小而灵活的"猴群式"软件反而更具竞争力。
企业的实际方案也已经从"买一款大而全的软件"转向"像拼乐高一样,用多个软件模块组装出最适合自己的解决方案"。这种模式在美国互联网高速发展时曾经发生过变革,美国最终孵化出了SaaS模式。而中国过去十年,由于存在大量低成本的996工程师,很多互联网/大型企业选择自建和定制化开发系统。然而,随着劳动力成本上升,企业降本增效的压力增大,企业正在重新评估软件采购策略,由多家专业软件生态公司组成的解决方案优势逐渐凸显。
SAP并不是过时,只是它的"大一统"模式无法满足中国客户高速发展的需求。
DeepSeek等廉价大模型:恐龙软件的小行星级天灾
如果说中国行业的变革是恐龙软件的挑战,那么DeepSeek和国产廉价大模型的兴起,就是这些软件的"小行星级天灾"。
廉价大模型的崛起,正在瓦解恐龙型软件的核心竞争力:
功能堆砌的门槛被摧毁:
过去,恐龙软件的优势在于功能全面,而大模型可以自动生成业务流程和代码,让"功能多"不再是壁垒。
代码不再稀缺,真正稀缺的是行业深度认知。
未来,企业的业务流程构建方式将从低代码、无代码转向"自然语言自动生成"。
软件的用户角色变迁:
过去是"人用软件",未来是"AI用软件",人类只负责监督和调整。 这意味着,小型、灵活、专注的专业软件将比庞大的恐龙软件更具适应力。
大模型让软件编写变得"唾手可得",那么一个软件的核心竞争力一定不是在不停地扩展功能边界,不停地为贴合企业需求做定制化上,因为这企业比你更在行且容易获得。一个软件需要在自己的专业领域里做专做深,做出足够高的门槛,让大模型和企业自己的IT部门难以逾越。
在恐龙灭绝后的生物大爆发中,生存下来的并不是个体最强的生物,而是那些最具协作能力、最能适应环境变化的小型哺乳动物。
冰河期不是坏事,而是优胜劣汰的催化剂
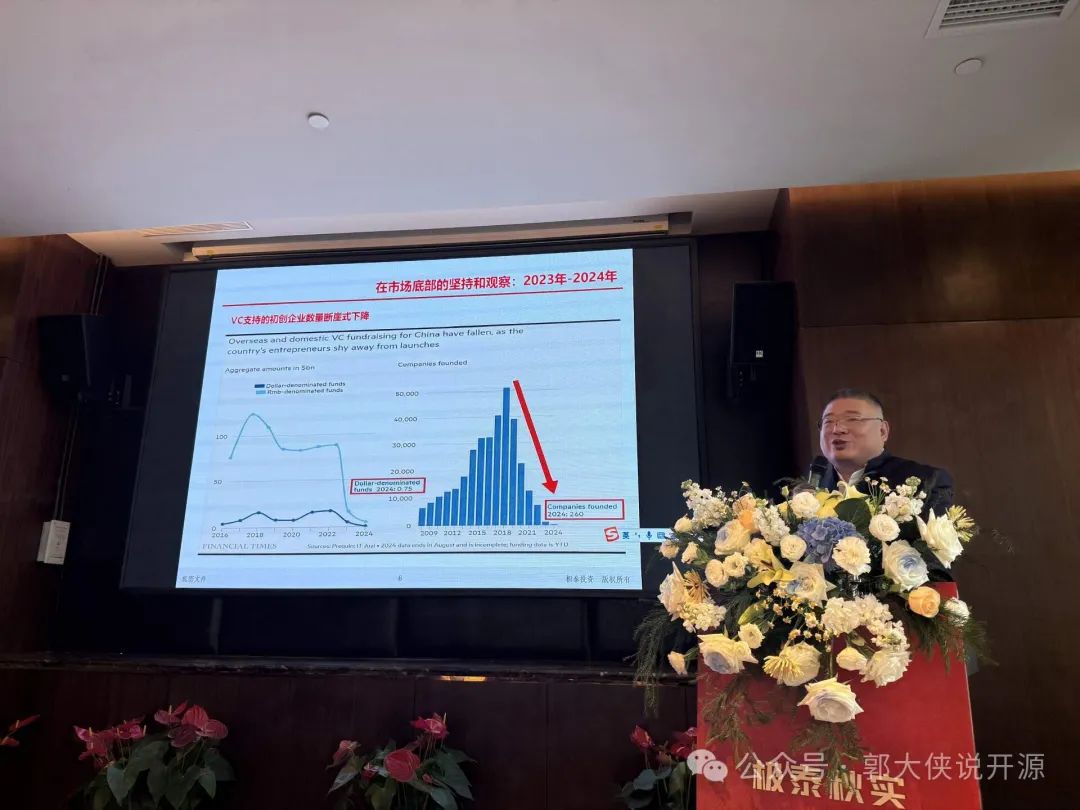
![file]()
2018年美元资本投资了5万家中国企业,而2024年只有260家,降幅达到99.48%。资本市场的降温,实际上是对中国软件行业的"优胜劣汰",逼迫企业从无边界竞争回归高效分工。我认为,过去十年,中国SaaS行业的溃败,不能仅归咎于私有化部署的挑战,而是由于资本的过度涌入导致SaaS公司疯狂扩张产品边界,集中在热门赛道低价倾销,缺乏上下游协同,最终拖垮了整个行业。
如今,资本寒冬迫使软件行业转向"猴群协作生态",让数万家细分领域的专业软件公司形成上下游高度协同的"中国软件供应链",实现更高效的资源整合,复刻"中国制造"的硬件供应链体系才是最终出路。
未来的企业不需要一款覆盖所有需求的恐龙软件,而是需要一群能够协同作战、各有所长的"猴群协作软件生态"。
我自己的感受:2025年猴群协作生态的变化
"猴群协作生态"变化,我今年开年就在白鲸开源的实践中已经深有体会。
白鲸开源是围绕Apache DolphinScheduler和Apache SeaTunnel,专注于数据开发、数据传输和ETL处理开源原创公司。过去几年,每个OLAP、数据仓库和大模型厂商(我比作数据油田)都会自建一套数据处理工具(我比作数据原油的炼化和管道),但他们逐渐意识到:
- 数据油田的核心竞争力是采油(数据存储、计算和推演),而非数据传输和炼化。
- 炼化和传输是一个高度专业化的领域,需要高效炼化和传输到数百家数据油田并不容易,而实施和环境适配更需要一套专业的方法论和体系来指导。
2025年初以来,我接触到越来越多的数据库和大模型公司开始主动和白鲸开源寻求合作,而不是再重复造轮子。见微知著,这种趋势意味着,中国软件行业正在从单打独斗的恐龙模式,转向更具协同效应的猴群模式。
企业只有专注自身过硬的核心业务,才能在大变革时代生存下来;如果试图变成一头无所不能的恐龙,最终只能被时代淘汰。
结语:大变革时代,恐龙将灭亡,猴群将进化成人类
2025年伊始,科技圈已发生诸多震撼行业的大事件,而这在2025年将是常态。在时代剧烈变革时,恐龙最难适应,灵活协作的猴群才会是未来的王者。
不可避免地,一些猴群会在竞争中被淘汰,但最终留下来的猴群,将进化成未来的软件生态主导者,就像人类最终取代了恐龙统治地球一样。
在这个时代,选择恐龙模式的企业,正在走向历史的终点;而选择猴群生态的企业,正在走向无限的未来。 本文由 白鲸开源科技 提供发布支持!