1. 前言
上一课我们讲到用Airtest-Selenium爬取下载可爱的猫猫图片,还没看的同学可以戳 这里 看看~
那么今天的推文,我们就来说说看,怎么实现模拟真人去打开微信读书网站,点击进入书本进行阅读。
2.需求分析和准备
3. 脚本实现与运行效果
3.1 脚本运行效果
在运行过程中,我们将每次的搜索结果通过读取url链接的方式去实现页面跳转,在进入到书籍阅读界面时,根据读取到的页面高度、文档高度、去计算可滑动高度,实现滑动阅读的操作。并且根据页面的JS距离去判断是否已经滑动到文档底部,从而执行点击下一章的操作。
![]()
3.2 完整代码分享
这里也附上完整的示例代码给大家参考,有需要的同学可以自取学习哦:
# -*- encoding=utf8 -*-
__author__ = "Airtest"
from airtest.core.api import *
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from airtest_selenium.proxy import WebChrome
from selenium.webdriver.common.by import By
# 创建一个实例
driver = WebChrome()
driver.implicitly_wait(20)
def start_selenium():
driver.get("https://www.baidu.com/")
# 输入搜索关键词并提交搜索
search_box = driver.find_element_by_name('wd')
search_box.send_keys('微信读书')
search_box.submit()
# 获取搜索结果并打开新页面
open_new_page()
# 滚动页面并阅读章节
read_chapters()
def open_new_page():
# 使用XPath查找文本为 "微信读书" 的元素并点击
try:
element = driver.find_element_by_xpath("//div[@id='content_left']/div[@id='1']/div[@class='c-container']/div[1]/h3[@class='c-title t t tts-title']/a")
except Exception as e:
element = driver.find_element_by_xpath('//*/text()[normalize-space()="微信读书"]/parent::*')
element.click()
# 获取所有窗口句柄
window_handles = driver.window_handles
# 切换到新打开的窗口
driver.switch_to.window(window_handles[1])
# 获取新页面的链接
new_page_url = driver.current_url
# 打印新页面的链接
print(f"新页面的链接: {new_page_url}")
driver.get(new_page_url)
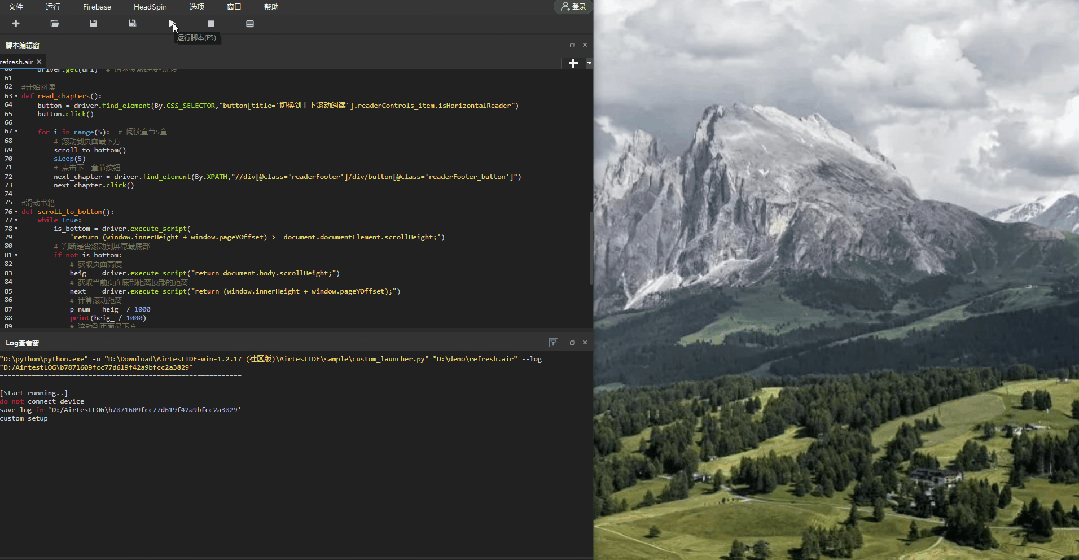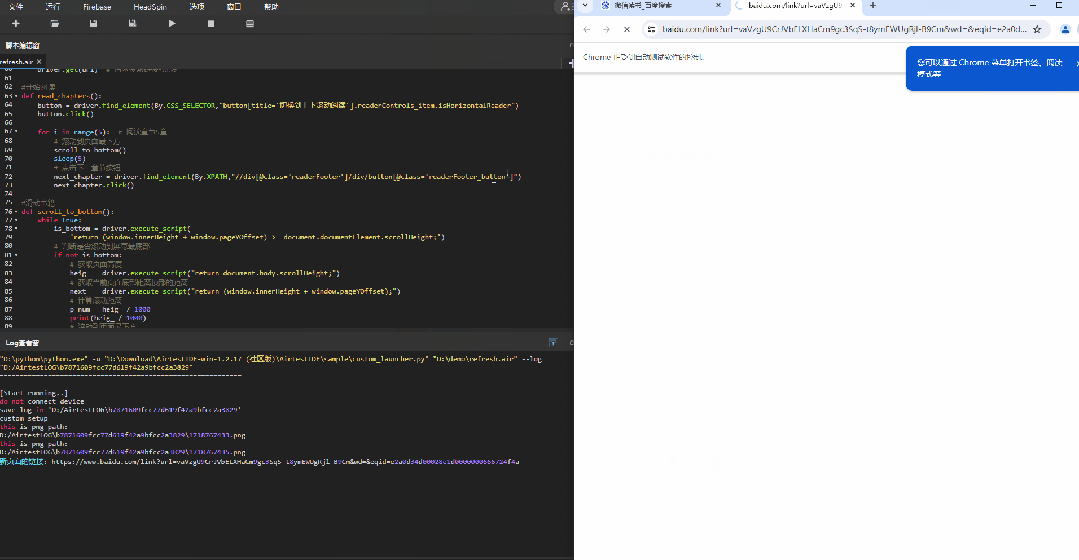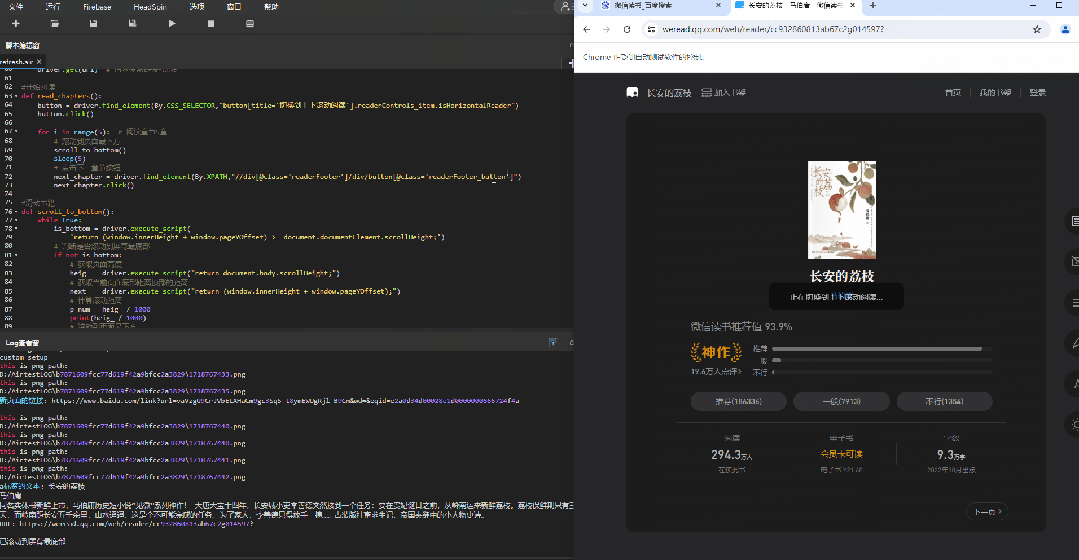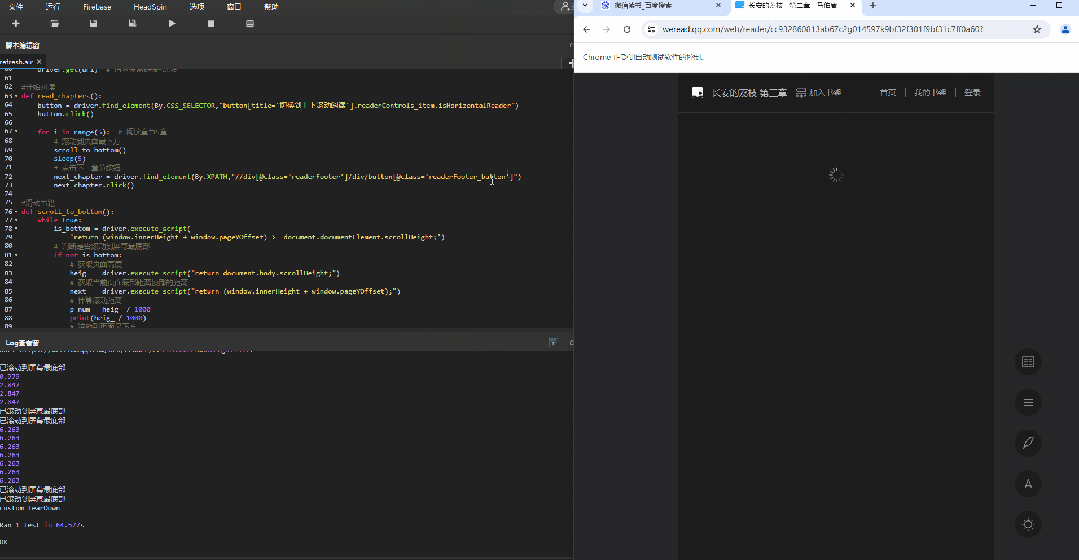
#点击搜索书籍《长安的荔枝》
driver.find_element_by_xpath("//input[@type='text']").click()
driver.find_element_by_xpath("/html/body/div[7]/div/div/div[2]/div/input").send_keys("长安的荔枝")
driver.find_element_by_xpath("/html/body/div[7]/div/div/div[2]/span[2]").click()
# 获取a标签的URL以及书籍简介
search_box = driver.find_element_by_xpath("/html/body/div[7]/div/div[3]/div/ul/li/a")
print(f"a标签的文本: {search_box.text}")
url = search_box.get_attribute('href')
# 打印URL
print(f"URL: {url}")
driver.get(url) # 请求搜索链接-跳转
#开始阅读
def read_chapters():
#切换上下滚动阅读模式
button = driver.find_element(By.CSS_SELECTOR,"button[title='切换到上下滚动阅读'].readerControls_item.isHorizontalReader")
button.click()
for i in range(5): # 阅读章节5章
# 滚动到页面最下方
scroll_to_bottom()
sleep(5)
# 点击下一章节按钮
next_chapter = driver.find_element(By.XPATH,"//div[@class='readerFooter']/div/button[@class='readerFooter_button']")
next_chapter.click()
#滑动书籍
def scroll_to_bottom():
while True:
is_bottom = driver.execute_script('return (window.innerHeight + window.pageYOffset) >= document.documentElement.scrollHeight;')
# 判断是否滚动到屏幕最底部
if not is_bottom:
# 获取页面高度
heig_ = driver.execute_script("return document.body.scrollHeight;")
# 获取当前页面底部距离顶部的距离
next_ = driver.execute_script("return (window.innerHeight + window.pageYOffset);")
# 计算滚动距离
p_num = heig_ / 1000
print(heig_ / 1000)
# 滚动到页面最下方
driver.execute_script(f"window.scrollTo(0, {p_num + next_});")
sleep(2)
else:
print('已滚动到屏幕最底部')
break
#管理 WebDriver 的生命周期
class SeleniumDriver:
def __enter__(self):
return driver
def __exit__(self, exc_type, exc_val, exc_tb):
pass
if __name__ == "__main__":
with SeleniumDriver():
start_selenium()
3.2 重要知识点
1)返回当前页面的文档在垂直方向上的高度
driver.execute_script("return document.body.scrollHeight;")
2)获取当前页面可见区域的高度和页面滚动距离
driver.execute_script("return (window.innerHeight + window.pageYOffset);")
driver.execute_script('return (window.innerHeight + window.pageYOffset) >= document.documentElement.scrollHeight;')
4)管理WebDriver的生命周期
如果不需要完成任务后就关闭浏览器的话,可以在 exit 的时候直接 pass 处理,如果需要立即关闭浏览器的话,可以选择在 exit 函数内填入 driver.close()
class SeleniumDriver:
def __enter__(self):
return driver
def __exit__(self, exc_type, exc_val, exc_tb):
pass
4. 注意事项与小结
4.1 相关教程
4.2 课程小结
在本周的课程中,我们介绍了如何使用Airtest-selenium在微信读书web端上模拟阅读书籍的操作,也分享了Airtest-selenium比较常见的获取滑动距离、计算滑动距离以及判断是否到底部的用法。但是,请大家注意,我们的分享仅供学习参考哦!我们分享的代码并不是永远适用的,因为网页的页面元素可能会不断更新。
同时,我们也非常欢迎同学们能够提供自己常用场景的代码,我们会积极分享相关的使用技巧。让我们一起努力,共同进步~