一、前言
之前在问卷以及Q群上有同学有提出过能否将网页上的一些数据通过 Airtest 去导出生成一份 Excel ,那么我们今天一起讨论一下,我们应该如何去实现,以及当我们获取的数据类型不同的时候,获取的方式该怎么随之调整?
二、知识点介绍
2.1 python下的Excel的操作
import xlwings as xw
# 创建一个新的Excel工作簿和工作表
wb = xw.Book()
sheet = wb.sheets[0]
#将内容写入Excel内
sheet.range((row_index, col_index)).value = cell.text
# 保存Excel文件
wb.save('output.xlsx')
wb.close()
2.2 获取table数据
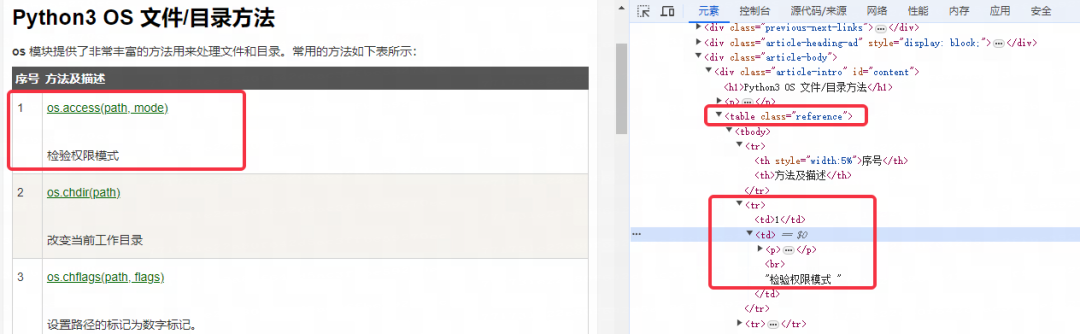
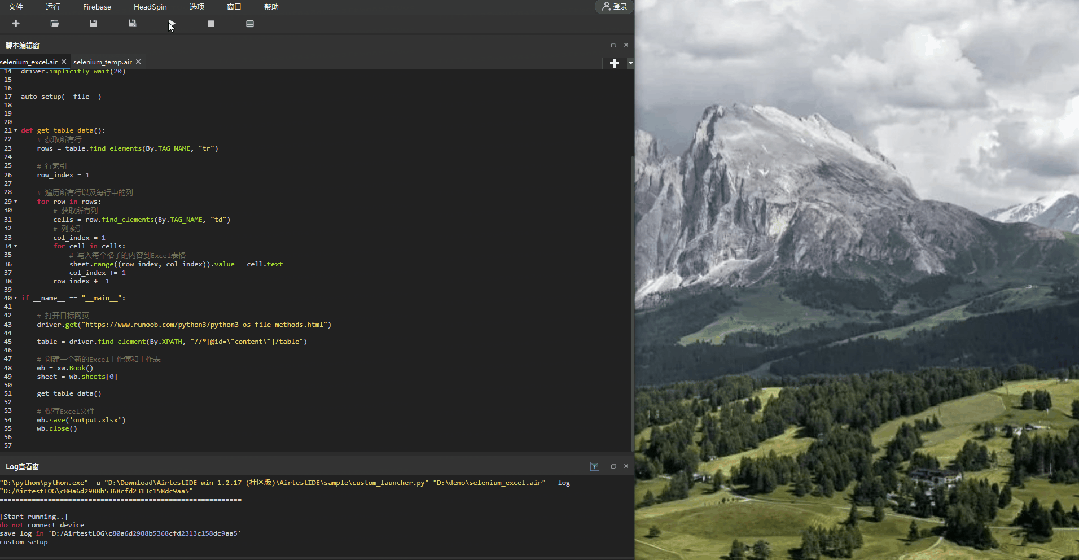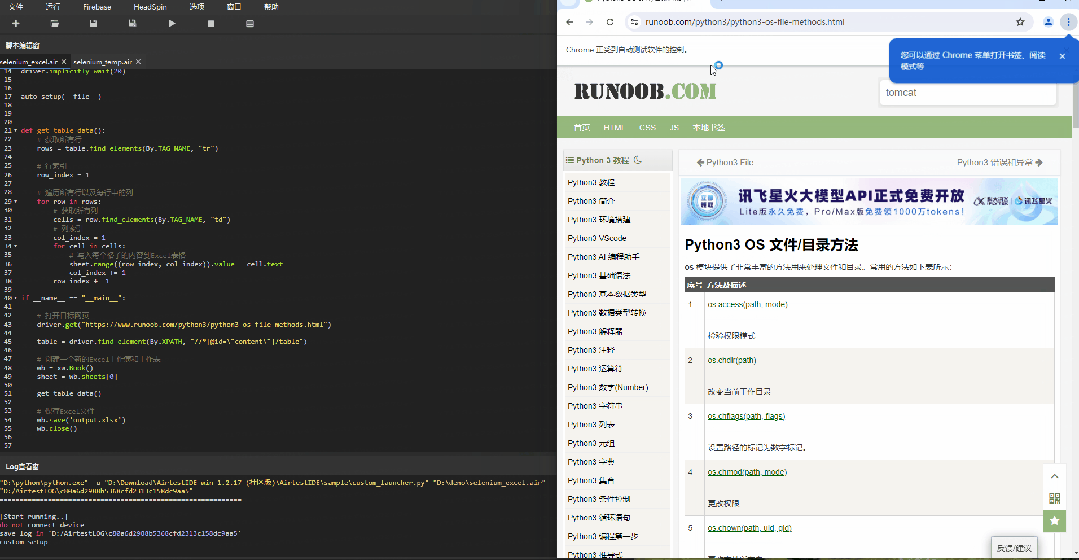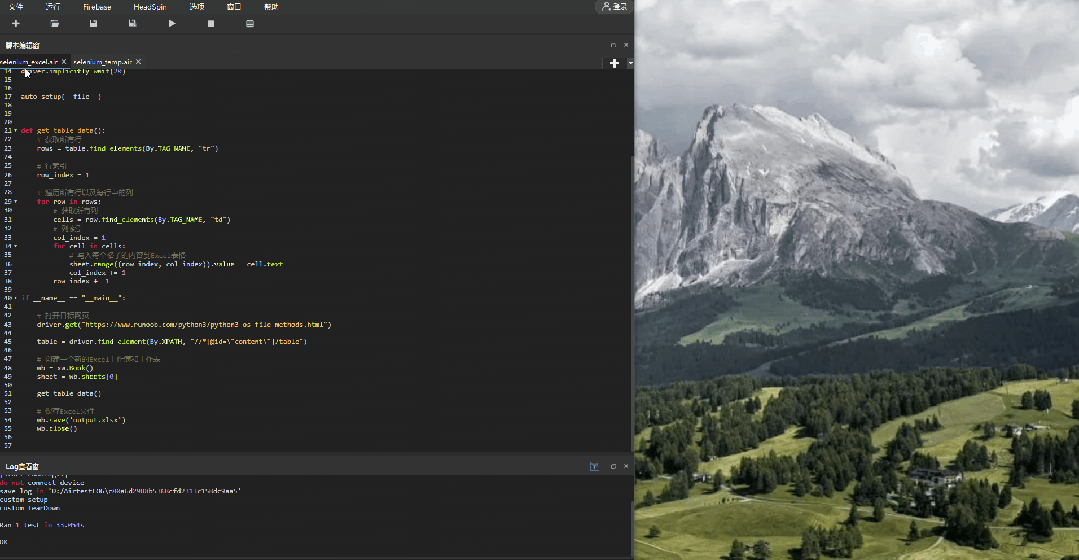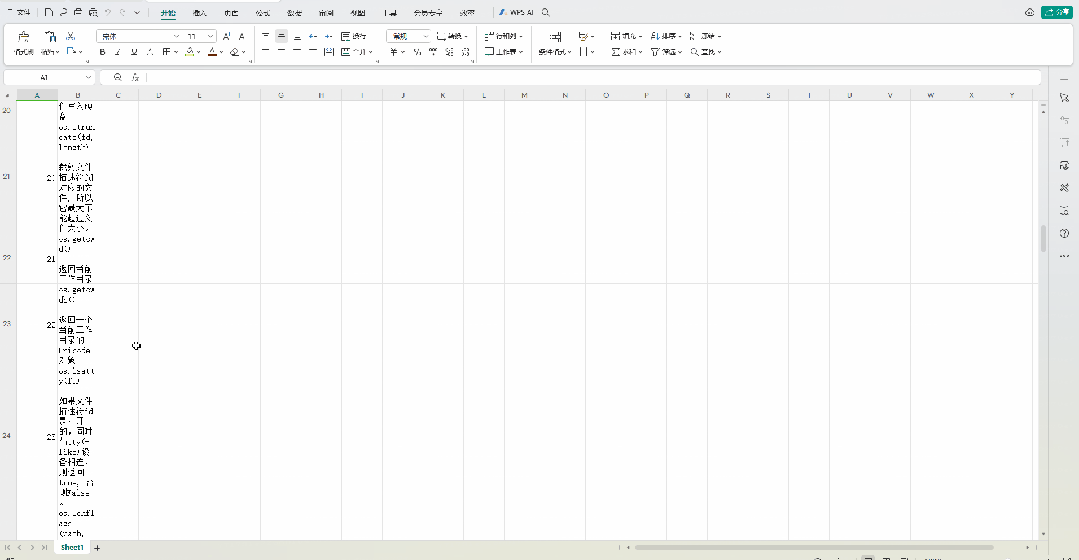
在网页上看到类似图下的表格内容时,可以在界面点击 F12 唤出页面开发者模式,可以看到表格在 HTML 中的标签为 <table> ,以及在表格中 <tr> 标签是表格的行, <td> 标签是表格的列,我们只需要找到 <table> 标签,将表格内的行列内容以此读取并导出到Excel中或输出即可。
def get_table_data():
#获取表格
table = driver.find_element(By.XPATH, "//*[@id=\"content\"]/table")
# 获取所有行
rows = table.find_elements(By.TAG_NAME, "tr")
# 行索引
row_index = 1
# 遍历所有行以及每行中的列
for row in rows:
# 获取所有列
cells = row.find_elements(By.TAG_NAME, "td")
# 列索引
col_index = 1
for cell in cells:
# 写入每个格子的内容到Excel表格
sheet.range((row_index, col_index)).value = cell.text
col_index += 1
row_index += 1
2.3 获取普通数据内容
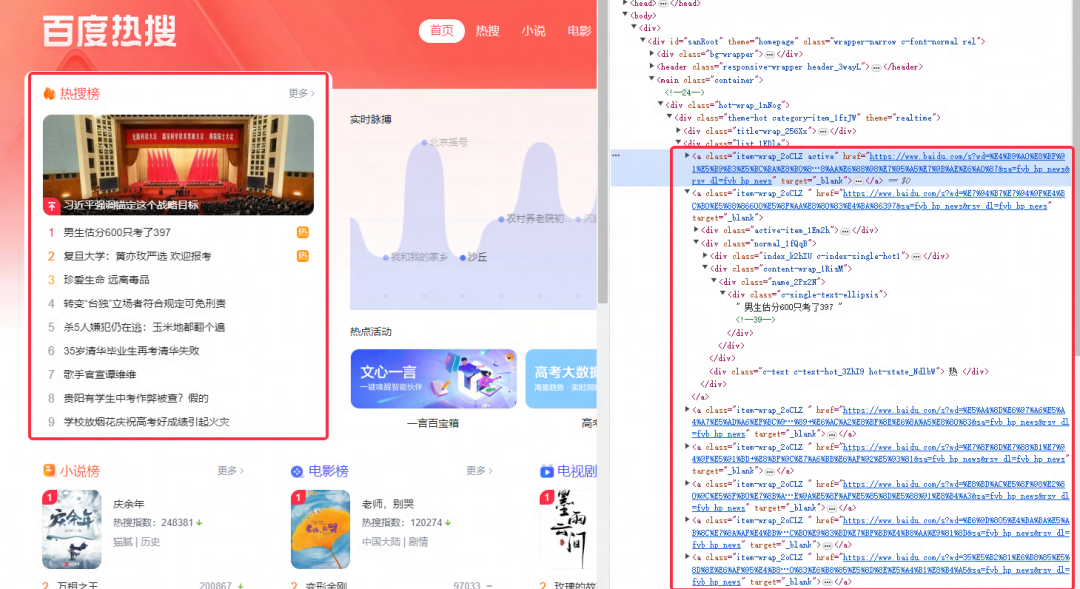
如果是要将普通的数据依照一定的规律去进行导出的话,我们可以看一下在浏览器内,数据的表现是怎么样的,例如我们这边用的例子是百度热搜界面,想要将热搜榜导出,我们可以先观察一下热搜榜的 HTML 代码排布,热搜词条是在同一层级下按顺序排布的。
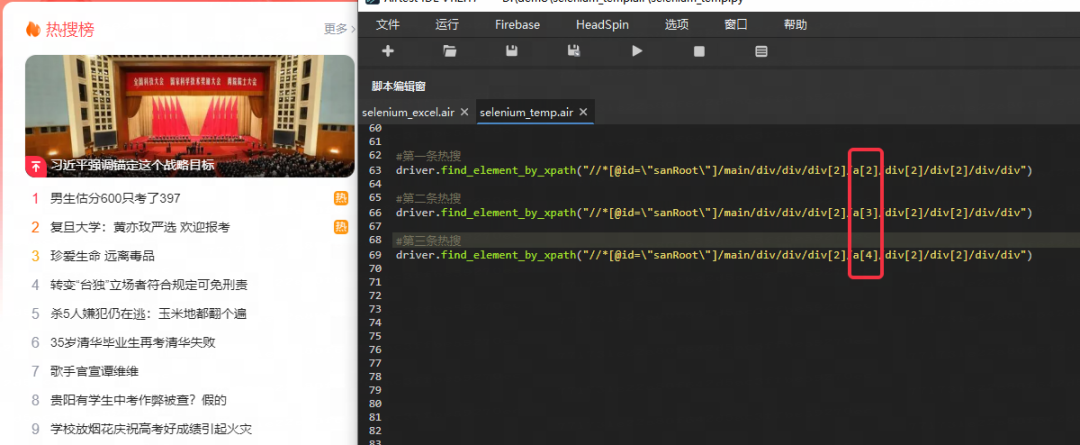
那我们可以看一下在AirtestIDE内获取的语句是否也存在一些规律,可以看到,我们在读取的时候,语句中的其中一个标签的索引值是呈递增的,那我们就可以利用这个特性去进行循环获取我们所需要的内容。
# 循环获取XPath范围内的元素文本内容和链接
row_index = 1
for i in range(2, 11): # 假设你要获取10个元素
xpath = f"//*[@id='sanRoot']/main/div/div/div[2]/a[{i}]/div[2]/div[2]/div/div"
# 查找元素
element = driver.find_element(By.XPATH, xpath)
# 获取元素文本内容
content = element.text
# 获取元素的父链接 (a 标签)
parent_element = driver.find_element(By.XPATH, xpath + "/ancestor::a[1]")
link = parent_element.get_attribute('href')
# 写入Excel表格
sheet.range((row_index, 1)).value = content
sheet.range((row_index, 2)).value = link
row_index += 1
三、使用Airtest-selenium获取网页上的table内容并生成excel
接下来我们先来看一个导出网页上的 <table> 表格数据到本地Excel表的例子:
![]()
# -*- encoding=utf8 -*-
__author__ = "Airtest"
from airtest.core.api import *
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from airtest_selenium.proxy import WebChrome
from selenium.webdriver.common.by import By
import xlwings as xw
driver = WebChrome()
driver.implicitly_wait(20)
auto_setup(__file__)
def get_table_data():
# 获取所有行
rows = table.find_elements(By.TAG_NAME, "tr")
# 行索引
row_index = 1
# 遍历所有行以及每行中的列
for row in rows:
# 获取所有列
cells = row.find_elements(By.TAG_NAME, "td")
# 列索引
col_index = 1
for cell in cells:
# 写入每个格子的内容到Excel表格
sheet.range((row_index, col_index)).value = cell.text
col_index += 1
row_index += 1
if __name__ == "__main__":
# 打开目标网页
driver.get("https://www.runoob.com/python3/python3-os-file-methods.html")
table = driver.find_element(By.XPATH, "//*[@id=\"content\"]/table")
# 创建一个新的Excel工作簿和工作表
wb = xw.Book()
sheet = wb.sheets[0]
get_table_data()
# 保存Excel文件
wb.save('output.xlsx')
wb.close()
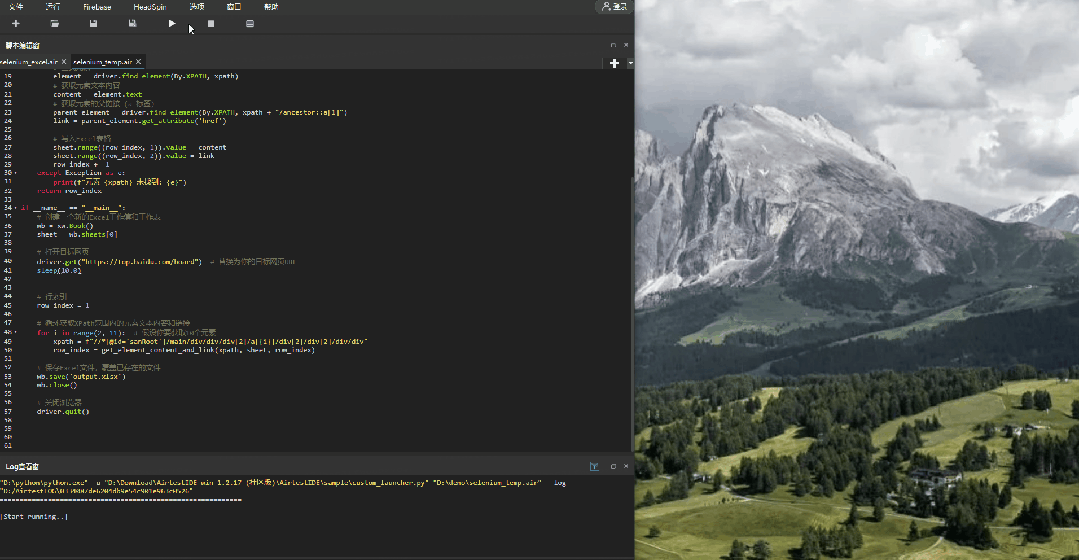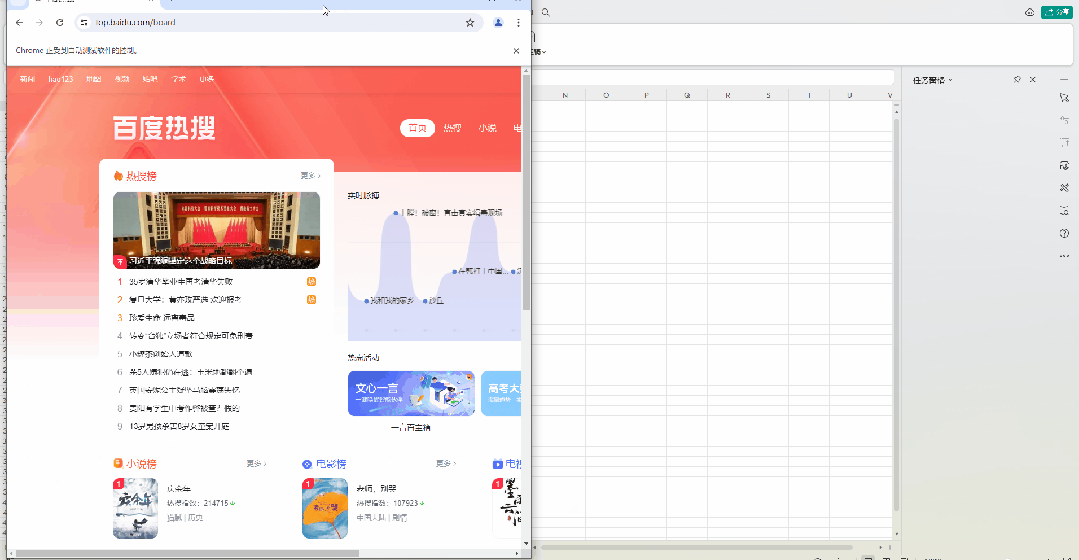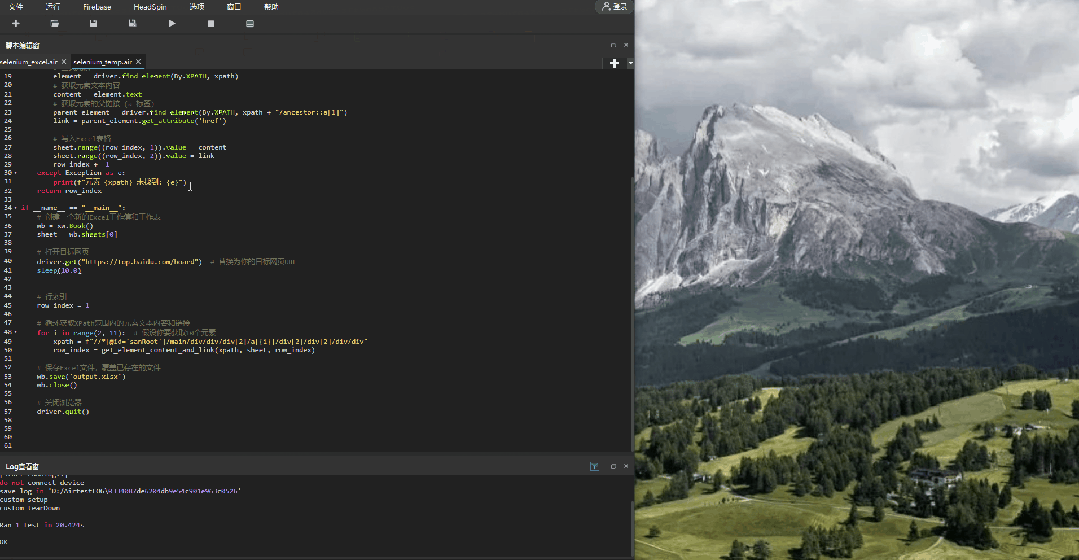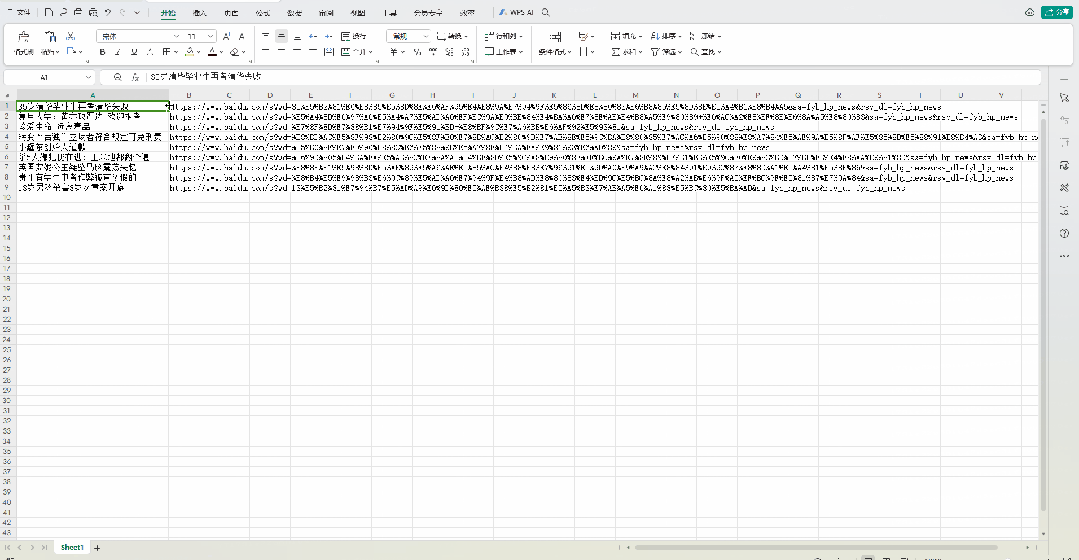
四、使用Airtest-selenium获取网页上的热搜榜并导出标题以及链接
然后我们再来看一个更实用的例子,获取百度热搜榜单内容到本地 Excel 的例子(PS:运营同学甚至可以做成定时脚本,定时收集榜单信息参考,时刻关注热门话题):
![]()
# -*- encoding=utf8 -*-
__author__ = "Airtest"
from airtest.core.api import *
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from airtest_selenium.proxy import WebChrome
import xlwings as xw
from selenium.webdriver.common.by import By
driver = WebChrome()
driver.implicitly_wait(20)
auto_setup(__file__)
def get_element_content_and_link(xpath, sheet, row_index):
try:
# 查找元素
element = driver.find_element(By.XPATH, xpath)
# 获取元素文本内容
content = element.text
# 获取元素的父链接 (a 标签)
parent_element = driver.find_element(By.XPATH, xpath + "/ancestor::a[1]")
link = parent_element.get_attribute('href')
# 写入Excel表格
sheet.range((row_index, 1)).value = content
sheet.range((row_index, 2)).value = link
row_index += 1
except Exception as e:
print(f"元素 {xpath} 未找到: {e}")
return row_index
if __name__ == "__main__":
# 创建一个新的Excel工作簿和工作表
wb = xw.Book()
sheet = wb.sheets[0]
# 打开目标网页
driver.get("https://top.baidu.com/board") # 替换为你的目标网页URL
# 行索引
row_index = 1
# 循环获取XPath范围内的元素文本内容和链接
for i in range(2, 11): # 假设你要获取10个元素
xpath = f"//*[@id='sanRoot']/main/div/div/div[2]/a[{i}]/div[2]/div[2]/div/div"
row_index = get_element_content_and_link(xpath, sheet, row_index)
# 保存Excel文件,覆盖已存在的文件
wb.save('output.xlsx')
wb.close()
# 关闭浏览器
driver.quit()
五、小结
本周推文我们主要是讲了 Airtest-selenium 获取网页上两种不同数据并导出到Excel表的情况,主要是介绍了关于 Airtest-selenium 与 Excel 的协作,以及在获取不同数据内容的时候,我们应该如何去获取以及思考脚本思路。在实际应用过程,同学们可以根据自己的需求,去编写更加复杂和专业的脚本。
如果在测试的过程中,遇到了问题,或者有任何想要深入了解的知识点,欢迎在官方交流群(526033840)里告诉我们或者提交issue,也欢迎大家投稿其他不同的使用小技巧。