本文分享自华为云社区《【GaussTech技术专栏】数据库中并行计算技术应用探秘》,作者:GaussDB数据库。
并行计算是提高系统性能的重要手段之一。该技术是通过利用多台服务器、多个处理器、处理器中的多核以及SIMD指令集等技术,实现任务的并行化处理,从而加快任务处理的速度。同时,在多个计算机领域有应用,如图像处理、大数据处理、科学计算及数据库等。
数据库中的并行处理技术
1. 分布式并行处理架构
并行处理数据库架构的出现可以追溯到上世纪80年代。当时计算机性能非常有限,但企业已经有了大规模的数据的处理需求。
那当时技术界是如何提升数据处理能力的呢?
当时技术界提出了三种并行架构:Shared Nothing、Shared Disk、Shared Memory,并对他们展开了各种讨论。图灵奖获得者Michael Stonebraker在1985年发表的一篇关于Shared Nothing的文章《The Case for Shared Nothing》,从不同维度,对三种架构能力做了一些比较分析。由于在成本、扩展性、可用性方面的优势,Shared Nothing成为主流的设计思路。
1)最早的Shared Nothing商业产品
最早的Shared Nothing数据处理系统是1984年Teradata公司发布的第一代产品DBC/1012。
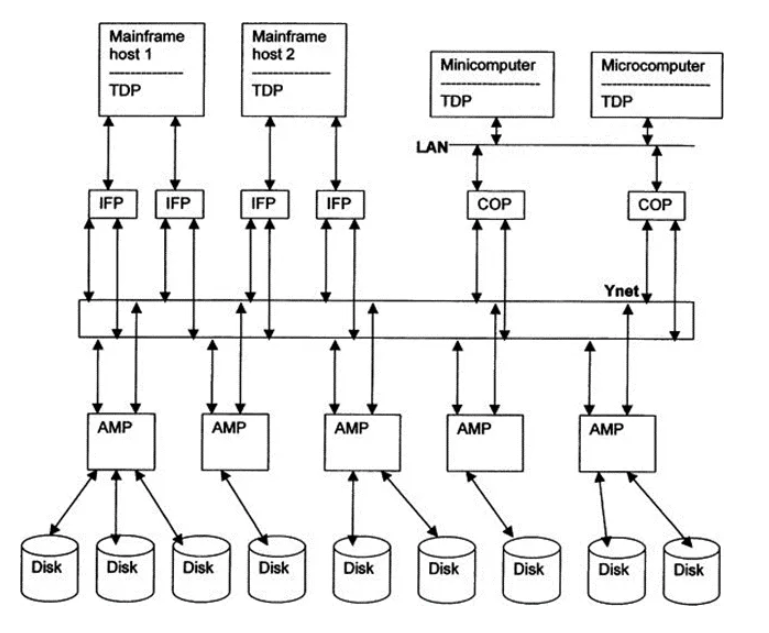
![1.PNG]()
图1 DBC/1012架构
DBC/1012的系统架构的关键组件有:
DBC/1012一开始作为大型机IBM 370的后端,后来也可用作其他各种大型机、小型计算机和工作站的后端。数据被算法平均划分到AMP管理的本地Disk,AMP之间通常不交换数据。可通过增加AMP的数量来提升整个系统的数据容量和性能。
虽然现在看来满满的历史感,但是当时借助Shared Nothing技术处理大数据时,Teradata表现得非常好,因此也赢得了优质大客户,帮助Teradata取得商业上的成功。
2)MPP(Massively Parallel Processing)和shared-nothing
数据库并行处理技术中经常会提到的MPP(Massively Parallel Processing),通常指的是服务器的系统架构分类方法。除了MPP之外,还有NUMA、SMP这两个分类。
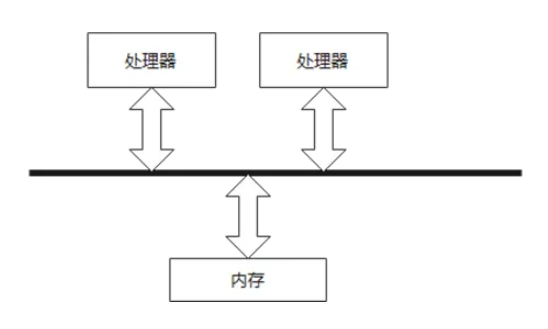
SMP服务器的主要特征是共享。系统中的所有资源(如内存、I/O等)都是共享的,扩展能力比较有限。
SMP有时也被称为一致存储器访问(UMA)结构体系,内存被所有处理机均匀共享。和NUMA不同,SMP所有处理器对所有内存具有相同的访问时间。
![2.PNG]()
图2 SMP示意
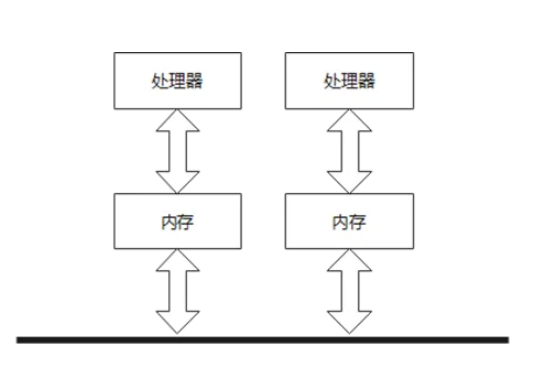
NUMA服务器的主要特征是拥有多个CPU模块,模块之间可以通过互联模块连接和信息交互。
每个CPU可以访问整个系统的内存,但是访问速度不一样。CPU访问本地内存的速度远远高于系统内其他节点的内存速度。
NUMA和MPP的区别在于,NUMA是一台物理服务器,而MPP是多台。
![3.PNG]()
图3 NUMA示意
MPP是多台服务器节点通过互联网络连接起来,各个服务器节点只访问本地资源(内存和存储),各个服务器之间shared nothing。
在数据库领域里,当我们说起一个数据库是MPPDB,是指在数据的设计实现上,利用MPP并行处理的服务器集群scale-out扩展数据库性能,服务器之间Shared Nothing。可以理解为MPPDB == Shared Nothing数据库。
当前支持MPP架构数据库产品有很多,如:Netezza(基于PG;IBM收购后不活跃)、Greenplum(基于PG;VMware)、Vertica(HP)、Sybase IQ(SAP)、TD Aster Data(Teradata)、Doris(百度)、Clickhouse(Clickhouse, Inc.)、GaussDB(华为)、SeaboxMPP(东方金信)等。
2. SMP并行
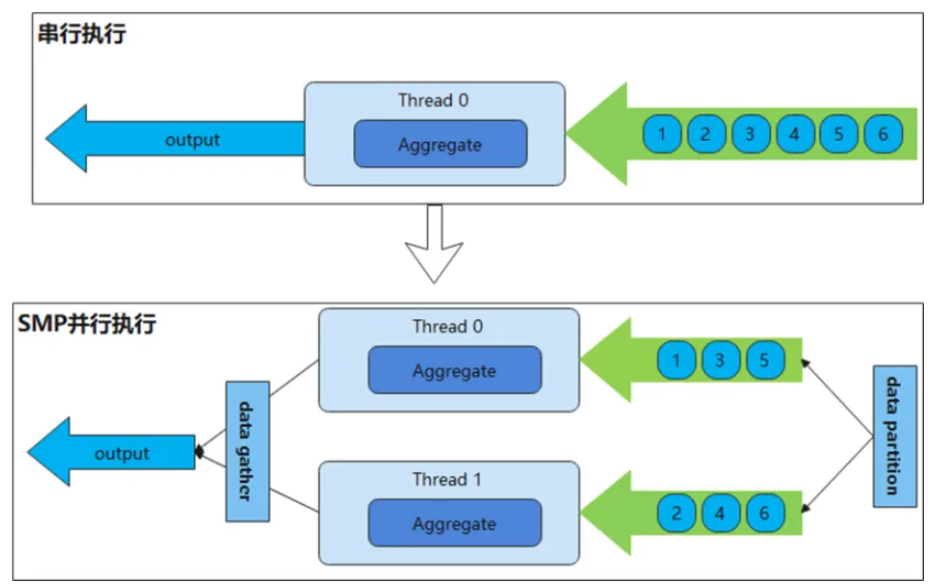
One size does not fit all。Shared Nothing并行技术做到了很好的水平横向扩展(scale-out),但随着单台物理服务器的硬件资源越来越强大(几十~上百个core/服务器),仅仅采用Shared Nothing技术,不能很好地挖掘硬件潜力。因为组成Shared Nothing架构数据库的单机很多都是SMP架构,即使是NUMA架构,其实每个NUMA域也可以近似认为是一个SMP系统。因此,业界又做了SMP并行执行的工作,提升单机上纵向扩展(scale-up)能力,优化处理性能。
SMP并行技术可通过多线程多子任务并行执行的机制实现系统计算资源的充分高效使用,如下图所示:
![4.PNG]()
3. 其他并行技术
SMP进一步提升了数据库节点内并行处理的能力,但是数据库节点的处理芯片的处理性能仍可以进一步压榨,比如ARM和x86处理器往往都配备了SIMD指令集,提升了一条指令可以处理的数据的位宽。篇幅原因,这些并行技术会在后续GaussTech系列文章中阐述,这里不再赘述。
开源数据库中的并行技术应用
当前流行的开源数据库有两款:MySQL和PostgreSQL。让我们来看一下这两款开源数据库系列中Shared Nothing和SMP技术的运用吧。
1. Shared Nothing
MySQL搭建Shared Nothing数据库集群主要靠借助各厂商自研或者开源的中间件,结合MySQL数据库提供分布式并行处理能力。比如:GoldenDB、TDSQL-MySQL等。MySQL官方也提供了MySQL NDB Cluster,可借助其搭建分布式集群。
PostgreSQL也是类似的思路,比如:TDSQL- PostgreSQL以及PostgreSQL生态圈流行的开源中间件Postgres-XL、Postgres-XC、citus等。
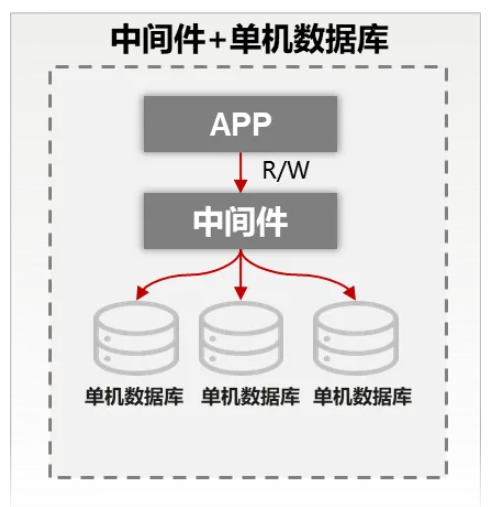
可以看到,MySQL以及PostgreSQL系提供Shared Nothing能力的主要是中间件架构的分布式数据库。
![5.PNG]()
虽然这类数据库能横向扩展数据处理能力,但也存在功能降级、全局事务能力和高可用、性能等方面存在短板,需要有针对性增强。
2. SMP并行技术
MySQL在2019年发布的8.0.14版本中第一次引入了并行查询特性,对于一条SQL语句,也能发挥主机CPU多核能力,改善复杂大查询的能力。
并行处理能力主要是由存储引擎InnoDB提供的:
(1) innodb_parallel_read_threads :配置用于并行扫描的最大线程数。
(2) innodb_ddl_threads :控制 InnoDB 创建(排序和构建)二级索引的最大并行线程数。
PostgreSQL从2016年发布的9.6开始支持并行顺序扫描、聚合,在2018年发布的11支持了更多的并行算子:并行哈希连接、Append、创建索引等。
PostgreSQL提供了一些参数来进行并行的控制,比如max_parallel_workers_per_gather。当优化器预判并行执行成本较高时,也不会生成并行执行计划。
可以看到,作为开源数据库中的翘楚,PostgreSQL和MySQL都应用了SMP线程级并行处理技术提升数据库的单节点处理性能。
总结
并行计算技术作为提升数据库处理性能的重要手段,在现有的数据库产品中得到了广泛的应用。本文简要说明了以Shared Nothing为代表的节点间并行处理技术,以及SMP节点内并行处理技术和它们在开源数据库中的应用。
GaussDB作为企业级数据库,也使用了这两项技术,提升了数据库处理的性能。相较于开源数据库的实现,GaussDB的实现方式,结合各类实际场景,添加了更多的特色实现,进一步提升了分布式处理性能,这些我们将于下一篇文章加以说明。
点击关注,第一时间了解华为云新鲜技术~