作者:汪诚愚(熊兮)、高一鸿(子洪)、黄俊(临在)
Qwen1.5(通义千问1.5)是阿里云最近推出的开源大型语言模型系列。作为“通义千问”1.0系列的进阶版,该模型推出了多个规模,从0.5B到72B,满足不同的计算需求。此外,该系列模型还包括了Base和Chat等多个版本的开源模型,为全球的开发者社区提供了空前的便捷性。阿里云的人工智能平台PAI,作为一站式的机器学习和深度学习平台,对Qwen1.5模型系列提供了全面的技术支持。无论是开发者还是企业客户,都可以通过PAI-QuickStart轻松实现Qwen1.5系列模型的微调和快速部署。
1、Qwen1.5系列模型介绍
通义千问1.5在先前发布1.0版本模型的基础上进行了大幅更新,主要体现在如下三个方面:
- 多语言能力提升:Qwen1.5在多语言处理能力上进行了显著优化,支持更广泛的语言类型和更复杂的语言场景。
- 人类偏好对齐:通过采用直接策略优化(DPO)和近端策略优化(PPO)等技术,增强了模型与人类偏好的对齐度。
- 长序列支持:所有规模的Qwen1.5模型均支持高达32768个tokens的上下文长度,大幅提升了处理长文本的能力。
- 在性能评测方面,Qwen1.5在多项基准测试中均展现出优异的性能。无论是在语言理解、代码生成、推理能力,还是在多语言处理和人类偏好对齐等方面,Qwen1.5系列模型均表现出了强大的竞争力。
2、PAI-QuickStart 介绍
快速开始(PAI-QuickStart)是阿里云人工智能平台PAI的产品组件,它集成了国内外 AI 开源社区中优质的预训练模型,涵盖了包括大语言模型,文本生成图片、语音识别等各个领域。通过 PAI 对于这些模型的适配,用户可以通过零代码和 SDK 的方式实现从训练到部署再到推理的全过程,大大简化了模型的开发流程,为开发者和企业用户带来了更快、更高效、更便捷的 AI 开发和应用体验。
3、运行环境要求
本示例目前支持在阿里云北京、上海、深圳、杭州地域,使用PAI-QuickStart产品运行。 资源配置要求:
4、通过PAI-QuickStart使用模型
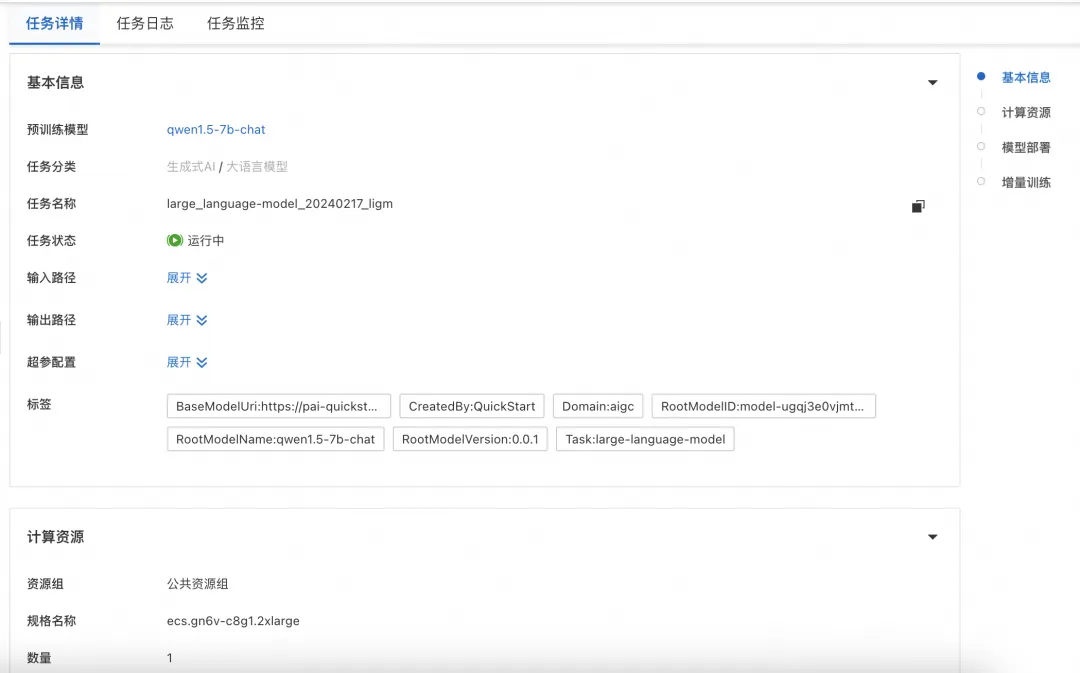
开发者可以在 PAI 控制台的“快速开始”入口,找到Qwen1.5系列模型,以Qwen1.5-7B-Chat为例,模型卡片如下图所示: ![]()
4.1 模型部署和调用
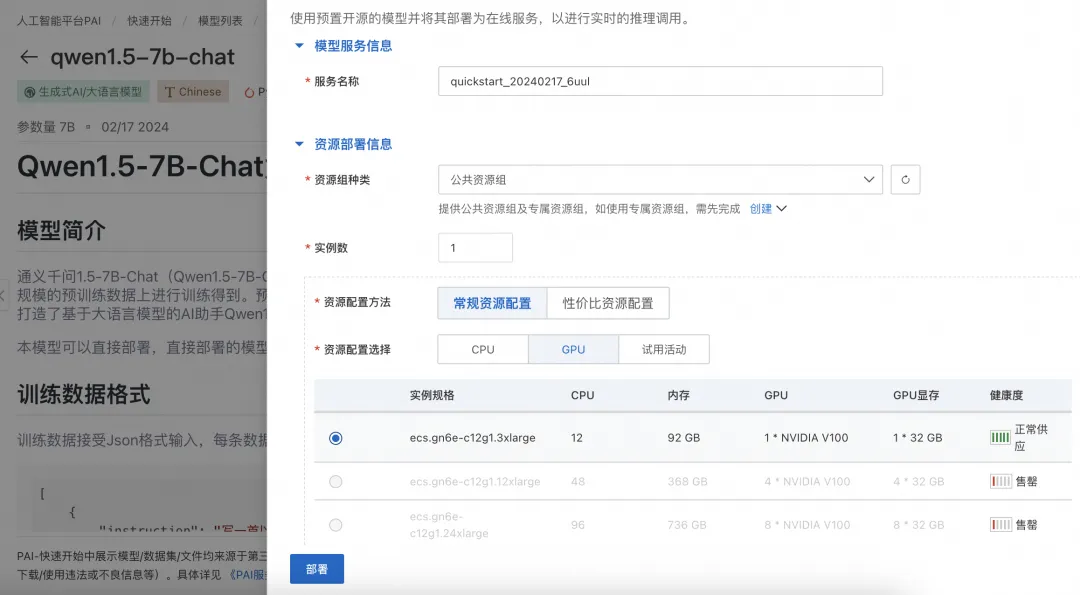
PAI 提供的Qwen1.5-7B-Chat预置了模型的部署配置信息,用户仅需提供推理服务的名称以及部署配置使用的资源信息即可将模型部署到PAI-EAS推理服务平台。当前模型需要使用公共资源组进行部署。 ![]()
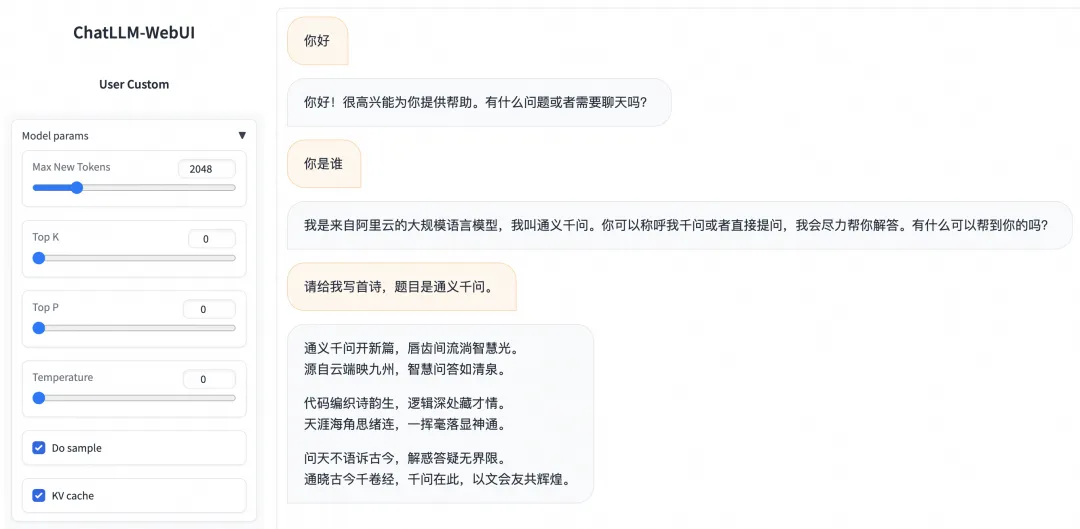
部署的推理服务支持使用ChatLLM WebUI进行实时交互,示例如下: ![]()
4.2 模型微调训练
PAI 为Qwen1.5-7B-Chat模型配置了微调算法,支持用户以开箱即用得方式对Qwen1.5-7B-Chat进行微调。训练算法支持使用 Json 格式输入,每条数据由问题、答案组成,分用“instruction”、“output”字段表示,例如:
[
{
"instruction": "写一首以“寓居夜感”为题的诗:",
"output": "独坐晚凉侵,客窗秋意深。风沙疑化雾,夜气欲成霖。家务劳人倦,浓茶代酒斟。哀鸿鸣四野,一并助长吟。"
},
{
"instruction": "写一首以“次答友人思乡诗”为题的诗:",
"output": "阅尽沧桑万事空,何如归卧夕阳中。并州最是伤心地,四十馀年噩梦同。"
}
]
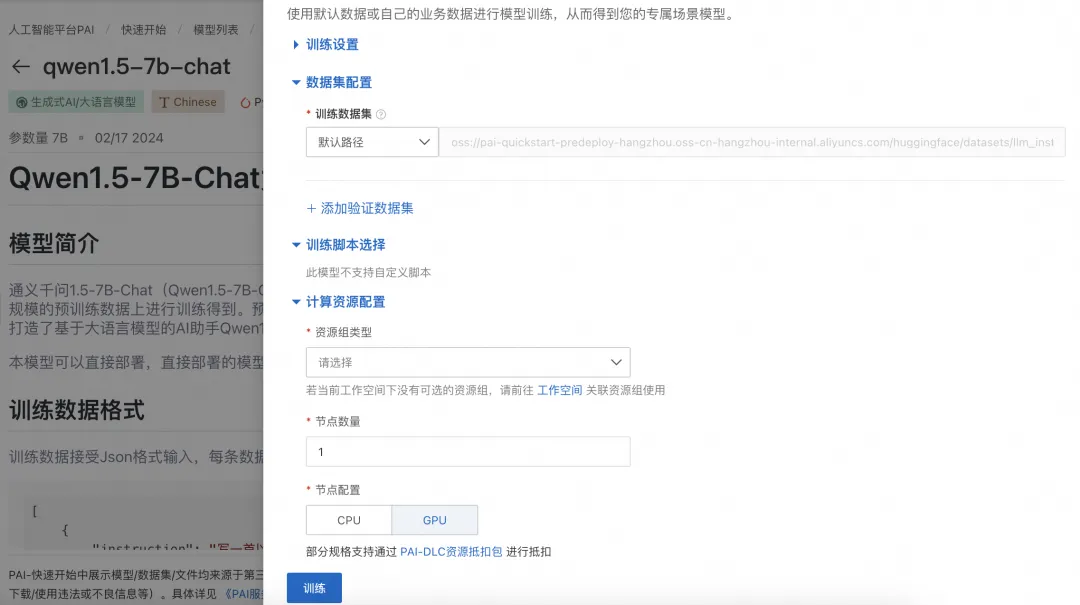
当完成数据的准备,用户可以将数据上传到对象存储 OSS Bucket 中。算法需要使用V100/P00/T4(16GB显存)的GPU资源,请确保选择使用的资源配额内有充足的计算资源。 ![]()
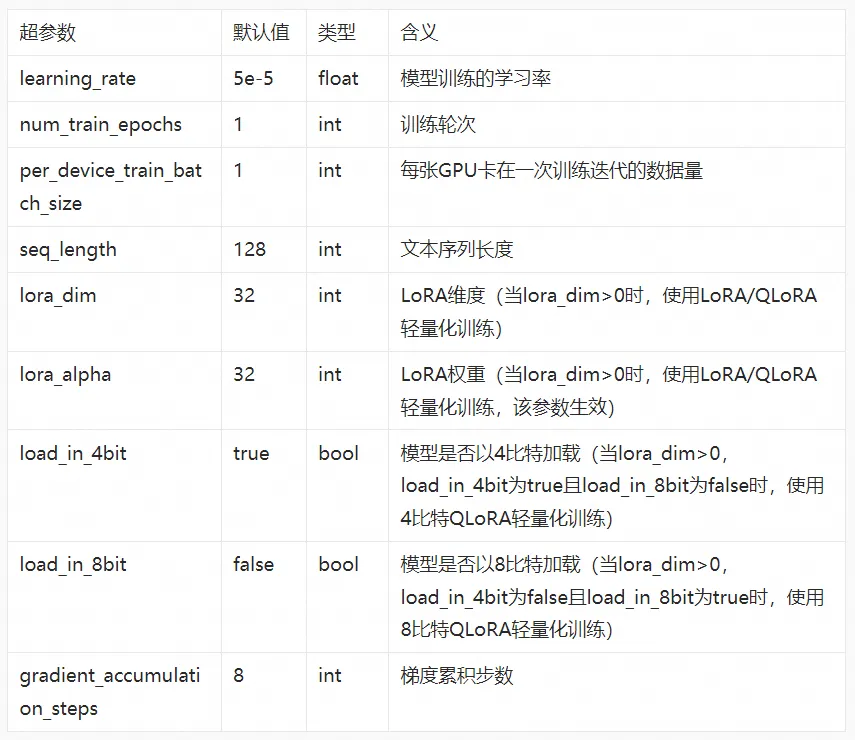
训练算法支持的超参信息如下,用户可以根据使用的数据,计算资源等调整超参,或是使用算法默认配置的超参。 ![]()
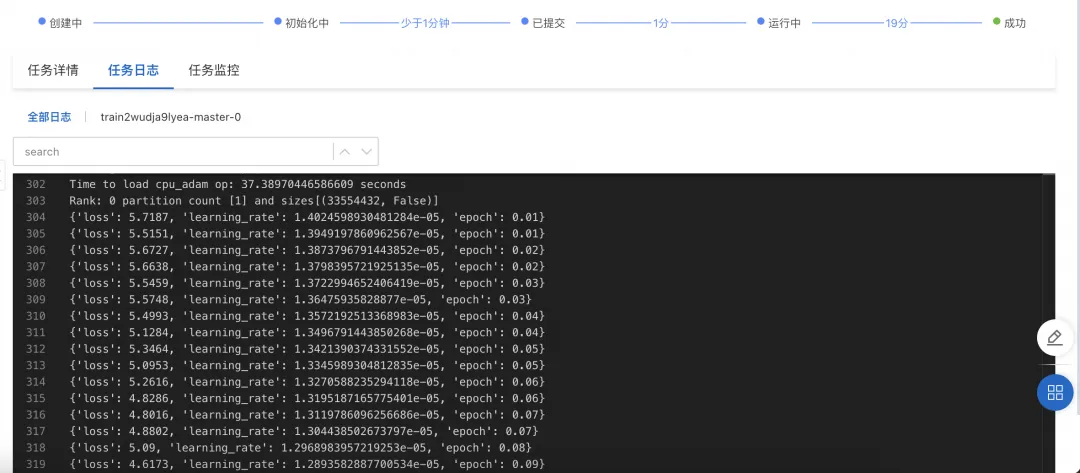
点击“训练”按钮,PAI-QuickStart 开始进行训练,用户可以查看训练任务状态和训练日志。 ![]()
![]()
如果需要将模型部署至PAI-EAS,可以在同一页面的模型部署卡面选择资源组,并且点击“部署”按钮实现一键部署。模型调用方式和上文直接部署模型的调用方式相同。
4.3 通过Python SDK使用
PAI 提供了Python SDK,支持开发者方便得使用Python在PAI完成模型的开发到上线的。通过PAI Python SDK,开发者可以轻松调用PAI-快速开始提供的模型,完成相应模型的微调训练和部署。
部署推理服务的示例代码如下:
from pai.model import RegisteredModel
# 获取PAI提供的模型
model = RegisteredModel(
model_name="qwen1.5-7b-chat",
model_provider="pai"
)
# 直接部署模型
predictor = model.deploy(
service="qwen7b_chat_example"
)
# 用户可以通过推理服务的详情页,打开部署的Web应用服务
print(predictor.console_uri)
微调训练的示例代码如下:
# 获取模型的微调训练算法
est = model.get_estimator()
# 获取PAI提供的公共读数据和预训练模型
training_inputs = model.get_estimator_inputs()
# 使用用户自定义数据
# training_inputs.update(
# {
# "train": "<训练数据集OSS或是本地路径>",
# "validation": "<验证数据集的OSS或是本地路径>"
# }
# )
# 使用默认数据提交训练任务
est.fit(
inputs=training_inputs
)
# 查看训练产出模型的OSS路径
print(est.model_data())
通过快速开始的模型卡片详情页,用户可以通过“在DSW打开”入口,获取一个完整的Notebooks示例,了解如何通过PAI Python SDK使用的细节。
5、结论
Qwen1.5(通义千问1.5)的推出标志着阿里云在开源大语言模型领域的最新进展。这个系列推出了不同规模的开源模型,可广泛用于多样化的下游应用场景。开发者可以借助PAI-QuickStart轻松地对Qwen1.5模型进行定制和部署。此外,PAI QuickStart还汇集了一系列先进的模型,覆盖多个专业领域,欢迎广大开发者们体验和应用这些丰富的资源。
相关资源链接: